标签:set sqrt val alt for input load count split
对于同一个input ,在某个正态分布上所在的区间更接近置信区间中心,对应的Y值大 ,说明它更像是这个label上的某一个样本
Geogebra 模拟
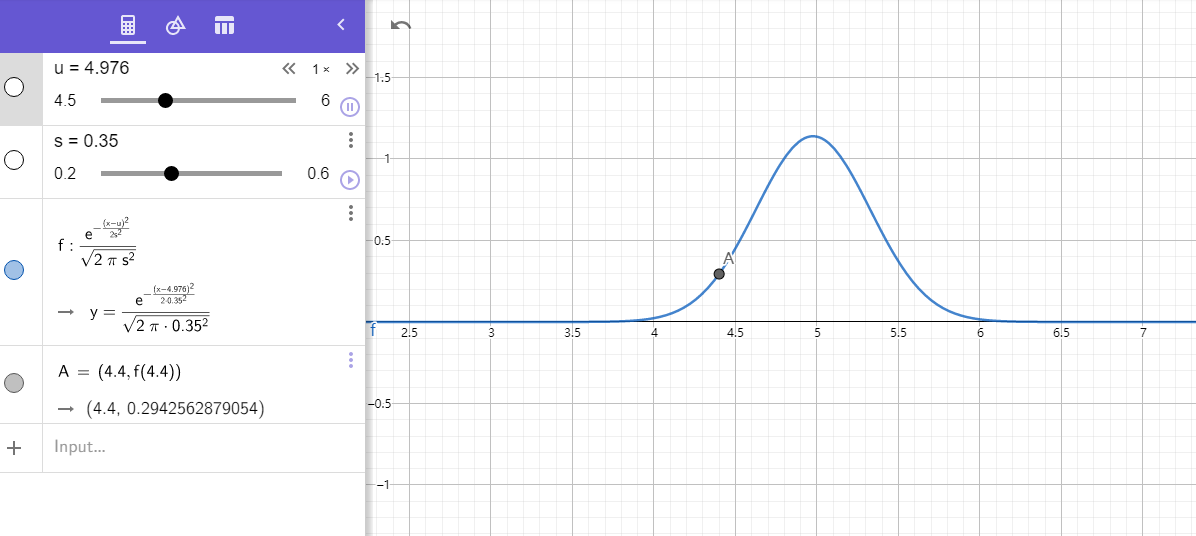
label0:
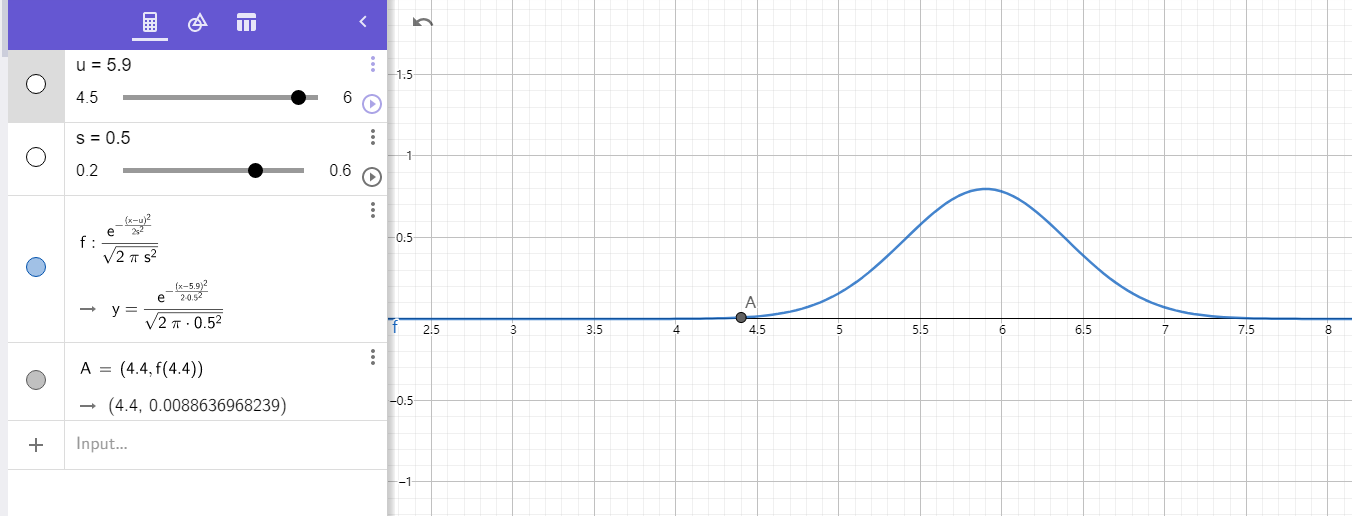
label1:
result summary:
label0:
meanVal : array([4.96571429, 3.38857143, 1.47428571, 0.23714286])
stdevVal : array([0.35370921, 0.36077015, 0.16620617, 0.10713333])
0 [0.3139061 0.96461384 1.38513086 3.50658634] 1.4707152132084353
label1:
meanVal: array([5.90285714, 2.71142857, 4.21142857, 1.29714286])
stdevVal: array([0.52180221, 0.28562856, 0.49267284, 0.19196088])
1 [1.20819778e-02 3.23420084e-01 2.11449510e-08 1.67604215e-07] 1.3848305491176349e-17
import numpy as np
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from collections import Counter
import math
def gaussian_probability( x, mean, stdev):
exponent = math.exp(-(math.pow(x - mean, 2) /
(2 * math.pow(stdev, 2))))
return (1 / (math.sqrt(2 * math.pi) * stdev)) * exponent
# data
X,y = load_iris(return_X_y=True)
X=X[:100,:]
y=y[:100]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
df_train = pd.DataFrame(X_train, columns=[‘sepal length‘, ‘sepal width‘, ‘petal length‘, ‘petal width‘])
df_train[‘label‘] = y_train
#fit
groupLabel= df_train.groupby(by = ‘label‘ ).size()
#统计每种类型 每个特性的mean, std ,
inputVal=np.array([4.4, 3.2, 1.3, 0.2])
for idx, targetLabel in enumerate(groupLabel.index):
meanVal= df_train[ df_train[‘label‘] == targetLabel].mean().values[:-1]
stdevVal= df_train[ df_train[‘label‘] == targetLabel].std(ddof=0).values[:-1]
#计算概率 对于特定的输入 求解它的特性与训练样本构成的高斯概率
gaussian_probability= np.exp(- 0.5* (inputVal-meanVal)**2 / stdevVal**2 ) / np.sqrt( 2*np.pi ) / stdevVal
probabilities=1
for prob in gaussian_probability:
probabilities = probabilities* prob
print(targetLabel,gaussian_probability, probabilities )
Gaussian Naive Bayes 高斯型 朴素贝叶斯
标签:set sqrt val alt for input load count split
原文地址:https://www.cnblogs.com/boyang987/p/14703082.html