标签:height 同事 整数 ima lis rem http 如何 文件
可以存哪些数据?
基本的数据模型是 key-value 模型
键和值用什么结构组织?
为什么哈希表操作变慢了?
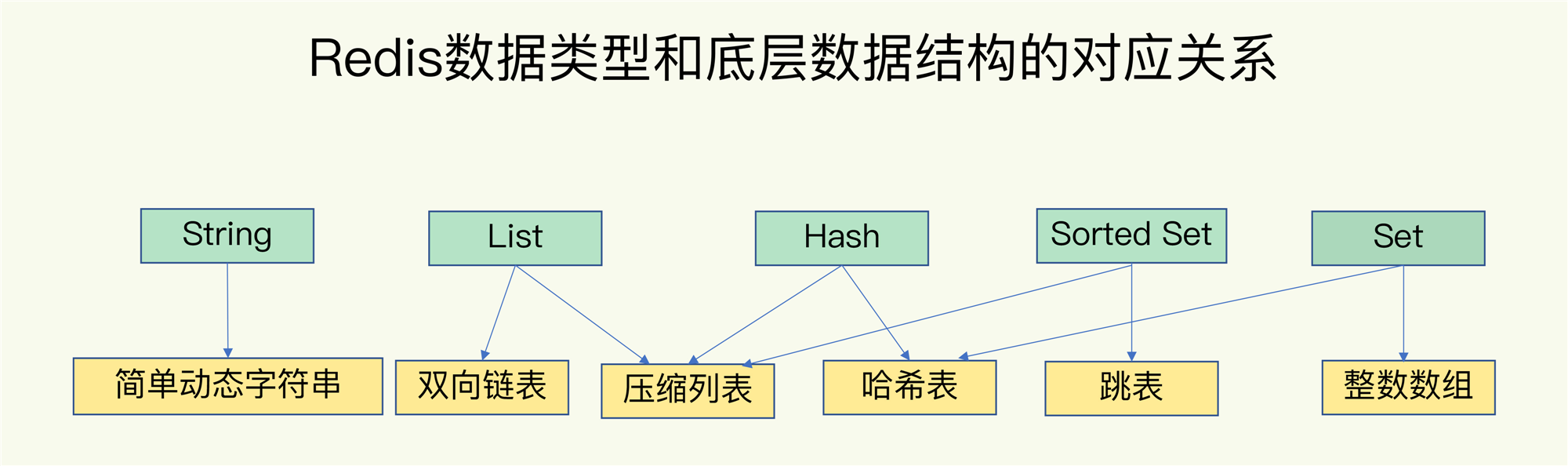
有哪些底层数据结构?
集合类型的底层数据结构主要有 5 种:整数数组、双向链表、哈希表、压缩列表和跳表。
其中,哈希表的操作特点我们刚刚已经学过了;整数数组和双向链表也很常见,它们的操作特征都是顺序读写,也就是通过数组下标或者链表的指针逐个元素访问,操作复杂度基本是 O(N),操作效率比较低;压缩列表和跳表我们平时接触得可能不多,但它们也是 Redis 重要的数据结构,所以我来重点解释一下。
不同操作的复杂度

在压缩列表中,如果我们要查找定位第一个元素和最后一个元素,可以通过表头三个字段的长度直接定位,复杂度是 O(1)。而查找其他元素时,就没有这么高效了,只能逐个查找,此时的复杂度就是 O(N) 了。
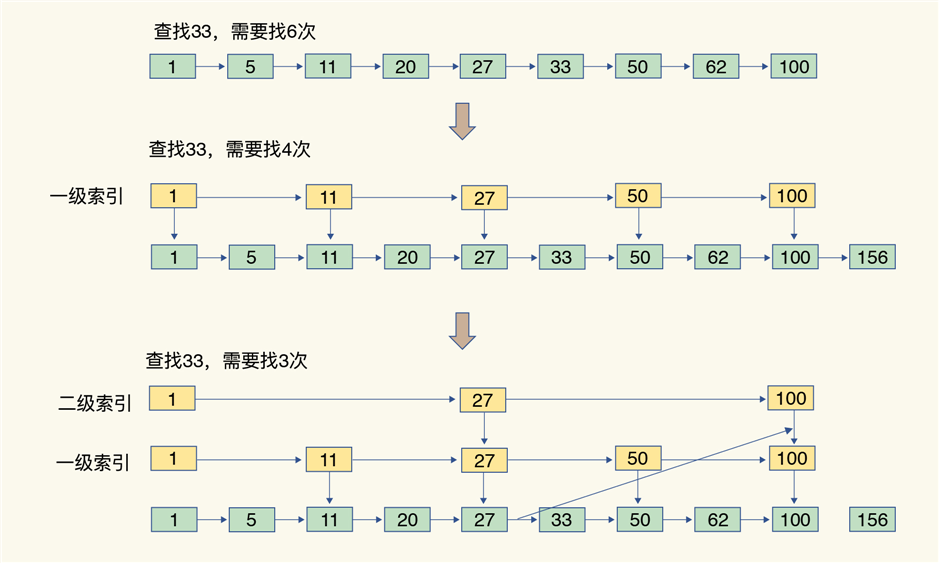
我们再来看下跳表。
有序链表只能逐一查找元素,导致操作起来非常缓慢,于是就出现了跳表。具体来说,跳表在链表的基础上,增加了多级索引,通过索引位置的几个跳转,实现数据的快速定位.
单元素操作,是指每一种集合类型对单个数据实现的增删改查操作。例如,Hash 类型的 HGET、HSET 和 HDEL,Set 类型的 SADD、SREM、SRANDMEMBER 等。这些操作的复杂度由集合采用的数据结构决定,例如,HGET、HSET 和 HDEL 是对哈希表做操作,所以它们的复杂度都是 O(1);Set 类型用哈希表作为底层数据结构时,它的 SADD、SREM、SRANDMEMBER 复杂度也是 O(1)。
范围操作,是指集合类型中的遍历操作,可以返回集合中的所有数据,比如 Hash 类型的 HGETALL 和 Set 类型的 SMEMBERS,或者返回一个范围内的部分数据,比如 List 类型的 LRANGE 和 ZSet 类型的 ZRANGE。这类操作的复杂度一般是 O(N),比较耗时,我们应该尽量避免
Redis 为什么用单线程?
多线程的开销
单线程 Redis 为什么那么快?
基本 IO 模型与阻塞点
对不同事件的发生,调用相应的处理函数
AOF 日志是如何实现的?
always everysec no(操作系统后决定)
AOF重写机制,重写机制具有“多变一”功能。所谓的“多变一”,也就是说,旧日志文件中的多条命令,在重写后的新日志中变成了一条命令
Redis 提供了两个命令来生成 RDB 文件,分别是 save 和 bgsave
bgsave 使用操作系统的copyOnWrite技术。
全量快照和增量快照
混合使用AOF和快照
内存快照以一定的频率执行,在两次快照之间,使用 AOF 日志记录这期间的所有命令操作
给哪些内存数据做快照?
标签:height 同事 整数 ima lis rem http 如何 文件
原文地址:https://www.cnblogs.com/likeloves/p/14661409.html