标签:获取 文件 部署 rgb lan Opens 相关 type color
雪花算法概述
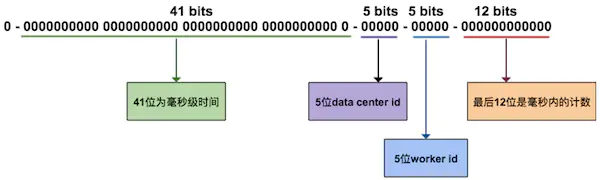
雪花算法简单来说是这样一个长整形数值。它64位,8个字节,刚好一个long。(为什么雪花算法ID是64位? 大概也是这个原因吧。理论上当然可以使用更多位,但是其实不是很有必要)
雪花算法,在单个节点上是有序的,如同 号段模式,但它也不是 全局严格有序,而是单个节点严格递增。
雪花算法的问题
1 因为雪花算法 依赖于本地时钟。所以存在时钟回拨问题。那么,如何避免时钟回拨?
2 雪花算法实现起来不复杂。但是问题是分布式场景之下,当需要启动的leaf服务越来越多时,对其分配workerId是一件非常令人头疼的事情。我们要做的是,尽量让一件事情简单化,让用户无感知。百度的UID做到了(文末有相关阅读链接),leaf也做到了!
美团Leaf snowflake模式原理
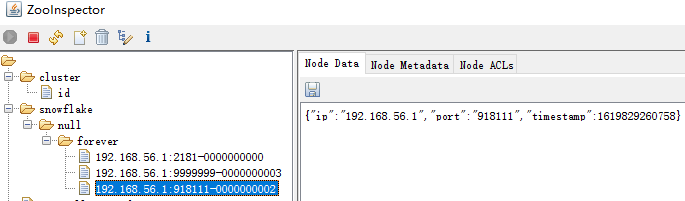
leaf的Snowflake模式是怎么做到的呢?很简单,通过zookeeper的PERSISTENT_SEQUENTIAL类型节点为每一个leaf实例生成一个递增的workerId。以总计部署4个leaf实例为例:第1个leaf实例的workerId为0,且根据该实例的IP地址和配置的Port值,即使接下来重启,workerId仍然为0;第2个leaf实例的workerId为1;第3个leaf实例的workerId为2;第4个leaf实例的workerId为3,以此类推。leaf持久化在zookeeper中的数据如下所示:
- /snowflake/afei/forever/
- |--192.168.0.1--0
- |--192.168.0.2--1
- |--192.168.0.3--2
我们可以看到这些数据的路径是:/snowflake/${leaf.name}/forever/${ip}:${port}。如此一来,对于所有部署的leaf实例,其获取到的workerId只跟它的ip和port有关。当然,由于其workerId占10位,所以,理论上Leaf服务实例数可以达到1024个(很明显,这个实例数上限几乎能够满足任何业务场景)。
实际情况, 默认会增加 - 00000 这样的 序号。
美团Leaf snowflake的使用&配置
默认的配置是:
leaf.name=com.sankuai.leaf.opensource.test
leaf.snowflake.zk.address=localhost
leaf.snowflake.port=2181
说明:
leaf.snowflake.zk.address 确实是将要连接的zk的地址列表,形如192.168.56.1:2181;192.168.56.2:2181,它可以是localhost,这个时候leaf实际上连接zk使用的是2181;
需要注意的是上面leaf.snowflake.port为2181, 会让人产生误解。因为它并不是zk的端口,仅仅是用来标志当前leaf节点。用来拼接在节点名称, 所以超过65536 也不会做检查,它不管它是什么具体值(但需要是整数).. 实际上, 我们可以把它设置为web的端口,这样就会出现冲突。
/**
* @param zkAddress zk地址
* @param port snowflake监听端口
* @param twepoch 起始的时间戳
*/
public SnowflakeIDGenImpl(String zkAddress, int port, long twepoch) {
this.twepoch = twepoch;
Preconditions.checkArgument(timeGen() > twepoch, "Snowflake not support twepoch gt currentTime");
final String ip = Utils.getIp(); // 实际将创建的节点的ip, 使用这个
SnowflakeZookeeperHolder holder = new SnowflakeZookeeperHolder(ip, String.valueOf(port), zkAddress);
如上,实际将创建的节点的ip, 使用的是本机ip,然后拼接上面的leaf.snowflake.port端口,创建的节点是PERSISTENT_SEQUENTIAL类型节点,从名字上看,它会持久化,然后又是有序的(从父节点的角度来看,它是有序的。它会从0每次增加1,节点可以有自己的名字,但是zk会主动给节点添加一个序号的后缀,长度是10,类型是10进制)。所以它会一直保存在zk之上,也就是说zk因为异常等原因重启之后,它依然存在,不会丢失。节点的内容是json,包括ip,port,时间戳timestamp;其中timestamp 是每3s更新一次。(点击黄色的刷新按钮,可以看到timestamp字段的变化)
leaf.name 配置项是做什么用的呢? 是用来确定将创建的zk节点的路径,上图因为没有配置 leaf.name 所以 展现是null!虽然是null,不过好像也没有什么关系,不影响程序正常运行。不过,一般情况下,对于一个分布式id,我们所有的leaf客户端,需要设置为相同的leaf.name,这样,workerID才会有序递增,才不会出现冲突! 如果不同业务含义的分布式id,自然需要不同的leaf.name; 所以,可以理解为leaf.name是分布式id 的名字。注意到leaf.name 对于号段模式是没有用的!!
因为将创建的zk节点使用的ip固定是本地ip,如果一个集群上部署两个leaf呢?那leaf会重复利用那个节点,而不会新创建。就是说如果不改配置,一个机器只能部署一个相同的微服务。如果想两个相同的微服务呢?那只能部署到不同的机器上去。 当然,对于不同的微服务,肯定需要不同leaf的配置,不然也不合理。那就只能修改 leaf.name 或leaf.snowflake.port; leaf会在本地创建缓存文件,名为workerID.properties,内容非常简单,就是使用给雪花算法使用的workerID。
这样下次重启leaf,即使zk连接不上,也能够正常运行。不过,就是后台会一直打印错误,有点烦人:
2021-05-01 14:43:35.450 INFO 13384 --- [.168.56.1:2181)] org.apache.zookeeper.ClientCnxn : Opening socket connection to server 192.168.56.1/192.168.56.1:2181. Will not attempt to authenticate using SASL (unknown error) 2021-05-01 14:43:37.452 WARN 13384 --- [.168.56.1:2181)] org.apache.zookeeper.ClientCnxn : Session 0x0 for server null, unexpected error, closing socket connection and attempting reconnect java.net.ConnectException: Connection refused: no further information at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method) ~[na:1.8.0_231] at sun.nio.ch.SocketChannelImpl.finishConnect(SocketChannelImpl.java:717) ~[na:1.8.0_231] at org.apache.zookeeper.ClientCnxnSocketNIO.doTransport(ClientCnxnSocketNIO.java:361) ~[zookeeper-3.4.6.jar:3.4.6-1569965] at org.apache.zookeeper.ClientCnxn$SendThread.run(ClientCnxn.java:1081) ~[zookeeper-3.4.6.jar:3.4.6-1569965]
当然,首次还是需要连zk的。另外,如果修改了leaf的配置,即leaf.properties ,那么会在zk上创建新节点;而之间创建的节点依然会留下来。
实际情况如何部署?
如同美团Leaf 号段模式,leaf-server 是可选的,我们只要创建自己的SnowflakeIDGenImpl实现的IDGen就可以了,然后当然要注意配置,要保证每个微服务实例使用相同leaf.name,然后要都能有各自的zk节点即可。任何两个实例不能使用相同zk节点,相同则可能出现重复id!
美团Leaf snowflake的测试
leaf-sever提供了rest 获取id 接口:
http://localhost:8010/api/snowflake/get/key
( 对于雪花算法,这里的key是没有作用的)
结果是: 1388377407299268680
多次刷新,可见这个值不断增长,也就是满足单调递增。
另外decodeSnowflakeId 接口提供了解码雪花算法id 的功能:
http://localhost:8010/decodeSnowflakeId?snowflakeId=1388377012309078107
结果是:
{"workerId":"3","sequenceId":"91","timestamp":"1619849849189(2021-05-01 14:17:29.189)"}
sequenceId 是什么? 是id在当前毫秒内的 序列!它有12个bit,所以 一个毫秒内最多可以产生 4096个id 哦!但是因为美团leaf对id 起始值做了优化,
sequence = RANDOM.nextInt(100);
它是100内随机的。
然后在不同的微服务实例上测试 /api/snowflake/get/key 接口,然后解析,发现是不同的workerId, 满足分布式id 要求!
美团Leaf snowflake与时钟回拨问题
时钟回拨的原因在于 获取雪花算法id 的时候,会去获取本地时间。这个本地时间是可能被 有意无意修改,如果修改为过去的时间,就会可能导致id重复的问题,也就是回拨问题!
Segment模式有时钟回拨问题吗?很明显没有,因为通过这种模式获取的ID没有任何时间属性,所以不存在时钟回拨问题。美团Leaf-snowflake方案 是怎么解决这个问题的呢?我能够猜到的是,如果它通过zk来获取时间,那么就不会依赖本地时间了!进而解决问题!
然后,通过过程源码发现,并没有实现。 可能是这个时钟回拨并不是很严重的问题吧!leaf的Snowflake模式并没有彻底解决时钟回拨的问题。当运行过程中,如果时钟回拨超过5ms ( 准确说是两次get 方法之间的回拨),依然会抛出异常。那么,Snowflake模式主要解决什么问题?很明显,是snowflake中的workerId部分。最后,leaf会定期(间隔周期是3秒)上报更新timestamp。并且上报时,如果发现当前时间戳少于最后一次上报的时间戳,那么会放弃上报。之所以这么做的原因是,防止在leaf实例重启过程中,由于时钟回拨导致可能产生重复ID的问题。
也就是说,运行时,leaf允许最多5ms 的回拨;重启时,允许最多3s 的回拨!
我们看源码:
sequence = RANDOM.nextInt(100); 避免了 每次 容易获取到的为 0 的问题。
它是怎么引起的? 手动修改时间? 我们的多个 linux机器上的时间不一致。。
—— 谁会这么无趣的去修改时间呢? 一般情况我们的linux机器上的时间还是可以保持一致的吧。所以,时钟回拨 不是大问题, 而且到这个程度, 也已经差不多了!
全局有序问题!
美团Leaf-snowflake方案能够全局有序吗? 不能。 实际什么,任何算法都不能保证全局有序,除非 单点,集中部署;
是否有任何办法保证全局有序递增? 我们把节点id 字段设置为相同,是否可以? 不可以啊.. 因为可能出现相同id 的情况。那么改进一下, 使得每个节点的步长一致,然后起始值不同,如同 数据库的主主模式, 好像也可以避免id 重复! (这样做比较麻烦,但是 其实如果不在意是否全局有序,可以忽略这步..)
那么号段模式,是否可以也保证全局有序? 无法! 因为每个客户端会获取新的号段!号段之间是并发的!
美团Leaf snowflake模式详解
标签:获取 文件 部署 rgb lan Opens 相关 type color
原文地址:https://www.cnblogs.com/FlyAway2013/p/14724325.html