标签:分区 span 数据 out style stdout mod sel lazy
本实例使用Numpy的数组切片语法,实现了K折交叉验证的数据划分
为什么需要这个?
在机器学习中,因为如下原因,使用K折交叉验证能更好评估模型效果:
K折验证是什么
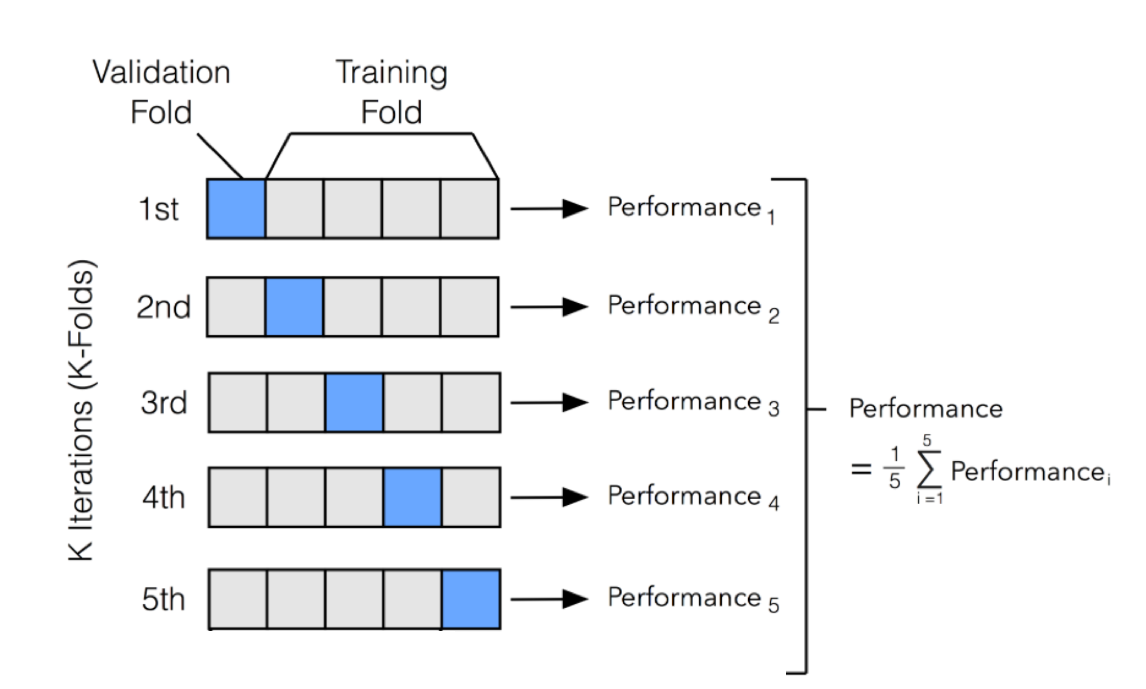
K折验证(K-fold validtion)将数据划分为大小相同的K个分区。
对每个分区i,在剩余的K-1个分区上训练模型,然后在分区i上评估模型。
最终分数等于K个分数的平均值,使用平均值来消除训练集和测试集的划分影响;
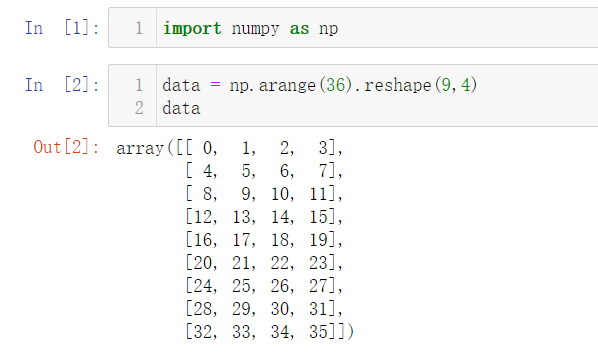
用样本的角度解释下data数组:
这是scikit-learn模型训练输入的标准格式
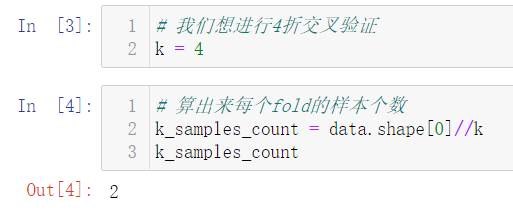
for fold in range(k):
validation_begin = k_samples_count*fold
validation_end = k_samples_count*(fold+1)
validation_data = data[validation_begin:validation_end]
# np.vstack,沿着垂直的方向堆叠数组
train_data = np.vstack([
data[:validation_begin],
data[validation_end:]
])
print()
print(f"#####第{fold}折#####")
print("验证集:\n", validation_data)
print("训练集:\n", train_data)
标签:分区 span 数据 out style stdout mod sel lazy
原文地址:https://www.cnblogs.com/zhjblogs/p/14725322.html