标签:并且 address open pytho gets details 成功 执行 import
Ps : 参考博文 https://blog.csdn.net/qq_38330148/article/details/113930949

# coding : utf-8
import requests
import json
def KFC_spider(url=None, keyword=‘北京‘):
"""
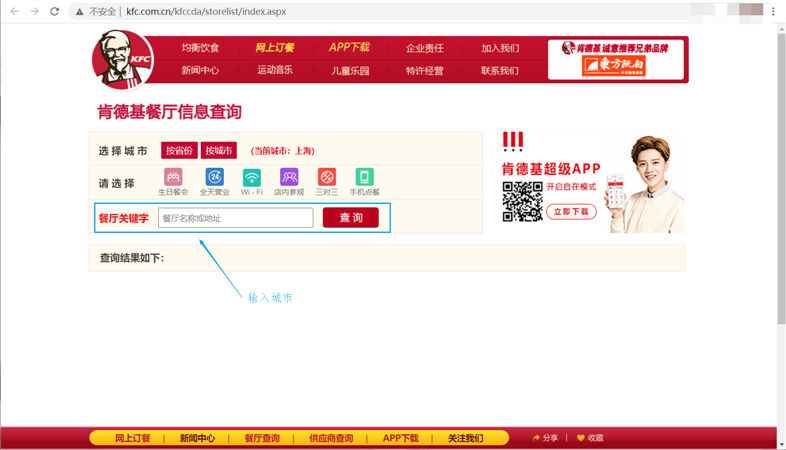
根据关键字爬取KFC餐厅信息
:param url: url链接
:param keyword: 地址关键字
:return:
"""
if url is None:
print("url should not be None!")
return
# 1.指定url
url = url
# 2.UA伪装
headers = {
‘User-Agent‘:‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36‘
}
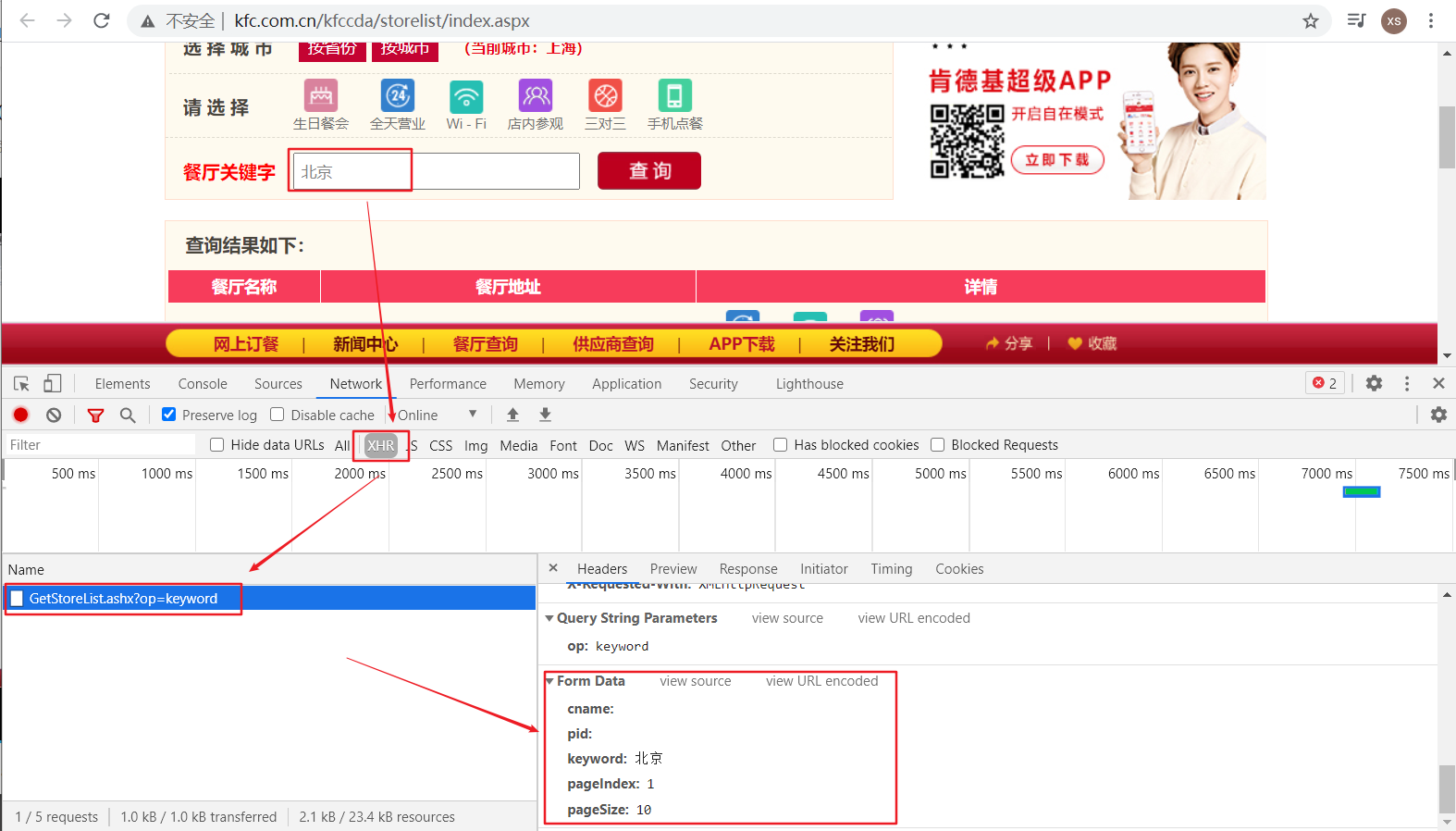
# 3.设置请求参数
params = {
‘cname‘: ‘‘,
‘pid‘: ‘‘,
‘keyword‘: keyword,
‘pageIndex‘: ‘1‘,
‘pageSize‘: ‘10‘
}
# 4.发送请求
response = requests.post(url=url, data=params, headers=headers)
# 5.获取响应数据
page_text = response.json()
# 持久化存储
fileName = keyword + ".json"
fp = open(fileName, ‘w‘, encoding=‘utf-8‘)
json.dump(page_text, fp=fp, ensure_ascii=False)
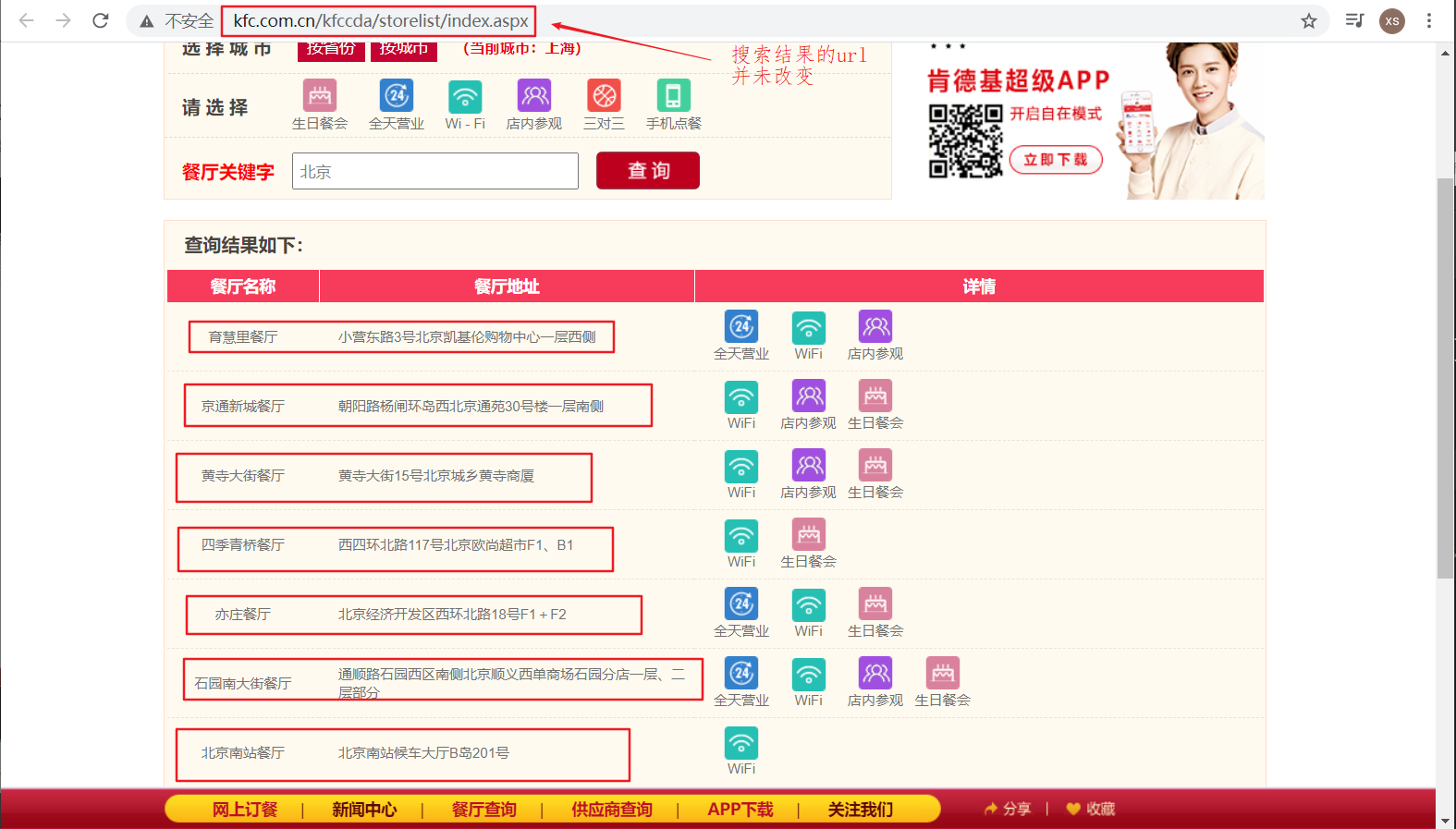
for data in page_text["Table1"]:
print("序号:{}, 店名:{}, 地址:{}, 信息:{}".format(data["rownum"], data["storeName"], data["addressDetail"], data["pro"]))
print("{}KFC餐厅信息爬取成功!".format(keyword))
if __name__ == ‘__main__‘:
# 指定url
url = ‘http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword‘
# 输入地址关键字
keyword = input("enter your address want to search:")
# 爬取餐厅信息
KFC_spider(url, keyword)
enter your address want to search:乐亭
序号:1, 店名:乐亭大东方, 地址:乐亭县城区中心社区金融街以北、发展大道以西大东方购物广场一层101号, 信息:Wi-Fi,店内参观
序号:2, 店名:乐亭大东方, 地址:乐亭县城区中心社区金融街以北、发展大道以西大东方购物广场一层101号, 信息:Wi-Fi,店内参观
乐亭KFC餐厅信息爬取成功!

标签:并且 address open pytho gets details 成功 执行 import
原文地址:https://www.cnblogs.com/dai-zhe/p/14727401.html