标签:cat http 交换 lazy val == nump 均值 com
import pandas as pd import numpy as np
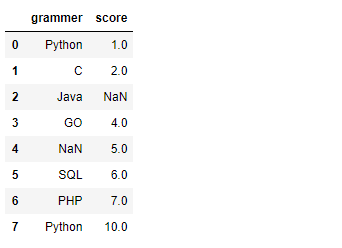
data = {"grammer":["Python","C","Java","GO",np.nan,"SQL","PHP","Python"],
"score":[1,2,np.nan,4,5,6,7,10]}
df = pd.DataFrame(data)
df
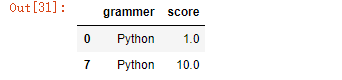
#方法一 df[df[‘grammer‘] == ‘Python‘] #方法二 results = df[‘grammer‘].str.contains("Python") results.fillna(value=False,inplace = True) df[results]
print(df.columns
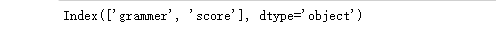
df.rename(columns={‘score‘:‘popularity‘}, inplace = True)
df
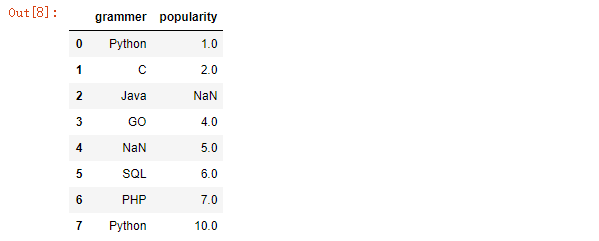
df[‘grammer‘].value_counts()

df[‘popularity‘] = df[‘popularity‘].fillna(df[‘popularity‘].interpolate()) df
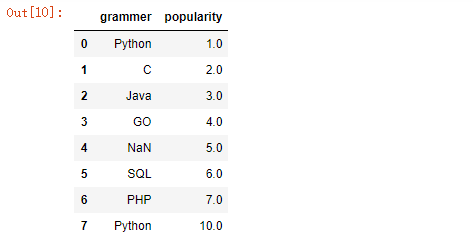
df[df[‘popularity‘] > 3]
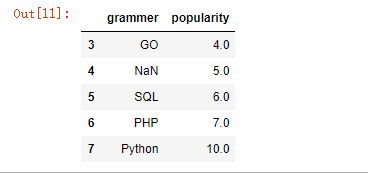
df.drop_duplicates([‘grammer‘])
df[‘popularity‘].mean()

df[‘grammer‘].to_list()
df.to_excel(‘test.xlsx‘)
df.shape

df[(df[‘popularity‘] > 3) & (df[‘popularity‘] < 7)]

‘‘‘ 方法1 ‘‘‘ temp = df[‘popularity‘] df.drop(labels=[‘popularity‘], axis=1,inplace = True) df.insert(0, ‘popularity‘, temp) df ‘‘‘ 方法2 cols = df.columns[[1,0]] df = df[cols] df ‘‘‘
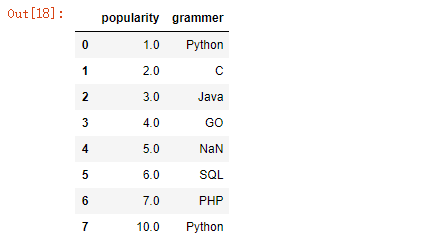
df[df[‘popularity‘] == df[‘popularity‘].max()]

df.tail()
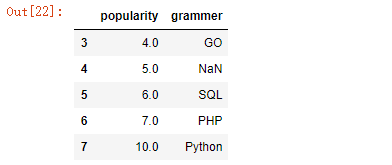
df.drop([len(df)-1],inplace=True)
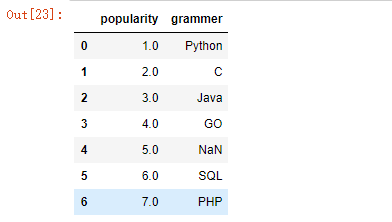
df
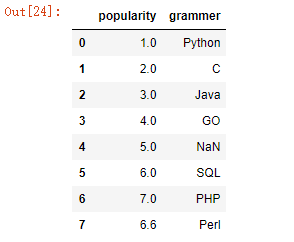
row={‘grammer‘:‘Perl‘,‘popularity‘:6.6}
df = df.append(row,ignore_index=True)
df
df.sort_values("popularity",inplace=True) df
df[‘grammer‘] = df[‘grammer‘].fillna(‘R‘) df[‘len_str‘] = df[‘grammer‘].map(lambda x: len(x)) df
数据可视化基础专题(十七):Pandas120题(二):1-20
标签:cat http 交换 lazy val == nump 均值 com
原文地址:https://www.cnblogs.com/qiu-hua/p/14728218.html