标签:流处理 location get fun word 获取 inpu targe int()
pom.xml 文件
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>deng.com</groupId> <artifactId>flink_demo</artifactId> <version>1.0-SNAPSHOT</version> <properties> <maven.compiler.source>8</maven.compiler.source> <maven.compiler.target>8</maven.compiler.target> </properties> <dependencies> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-java</artifactId> <version>1.10.1</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-java_2.12</artifactId> <version>1.10.1</version> </dependency> </dependencies> </project>
wordCount 程序
package com.deng; import org.apache.flink.api.common.functions.FlatMapFunction; import org.apache.flink.api.java.DataSet; import org.apache.flink.api.java.ExecutionEnvironment; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.util.Collector; public class WordCount { public static void main(String[] args) throws Exception { // 创建执行环境 ExecutionEnvironment env =ExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(8); // 从文件中读取数据 String inputPath="C:\\Users\\侠客云\\IdeaProjects\\flink_demo\\src\\main\\resources\\hello.txt"; DataSet<String> inputDataSet = env.readTextFile(inputPath); // 对数据集进行处理,按空格分词展开,转换成(word,1)二元组 DataSet<Tuple2<String,Integer>> resultSets= inputDataSet.flatMap(new MyFlatMaper()) .groupBy(0)//按照第一个位置word 进行分组 .sum(1) //按照 第二个位置上的数据求和 ; resultSets.print(); } // 自定义类,实现 FlatMapFunction 接口 public static class MyFlatMaper implements FlatMapFunction<String, Tuple2<String,Integer>>{ @Override public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception { // 按空格分词 String[] words=s.split(" "); // 遍历所有word,包成二元组 for (String word : words) { collector.collect(new Tuple2<>(word,1)); } } } }
StreamWordCount 程序
package com.deng;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class StreamWordCount {
public static void main(String[] args) throws Exception {
// 1.创建流处理执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(8);
// 2.
// 从文件中读取数据
// String inputPath="C:\\Users\\侠客云\\IdeaProjects\\flink_demo\\src\\main\\resources\\hello.txt";
// DataStream<String> inPutDataStream = env.readTextFile(inputPath);
// 用parameter tool 从程序启动参数中获取配置项
ParameterTool parameterTool = ParameterTool.fromArgs(args);
String host = parameterTool.get("host");
int port = parameterTool.getInt("port");
// 从socket文件流中获取数据
// DataStream<String> inPutDataStream =env.socketTextStream("hadoop102",7777);
DataStream<String> inPutDataStream =env.socketTextStream(host,port);
DataStream<Tuple2<String, Integer>> resultStream = inPutDataStream.flatMap(new MyFlatMaper())
.keyBy(0)
.sum(1);
resultStream.print();
// 执行任务
env.execute();
}
// 自定义类,实现 FlatMapFunction 接口
public static class MyFlatMaper implements FlatMapFunction<String, Tuple2<String,Integer>> {
@Override
public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception {
// 按空格分词
String[] words=s.split(" ");
// 遍历所有word,包成二元组
for (String word : words) {
collector.collect(new Tuple2<>(word,1));
}
}
}
}
测试环境中执行程序传参代码时,如何运行:
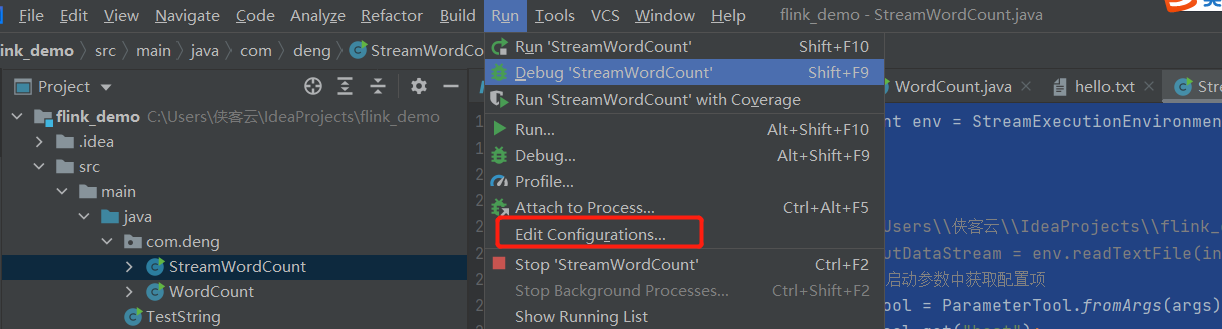
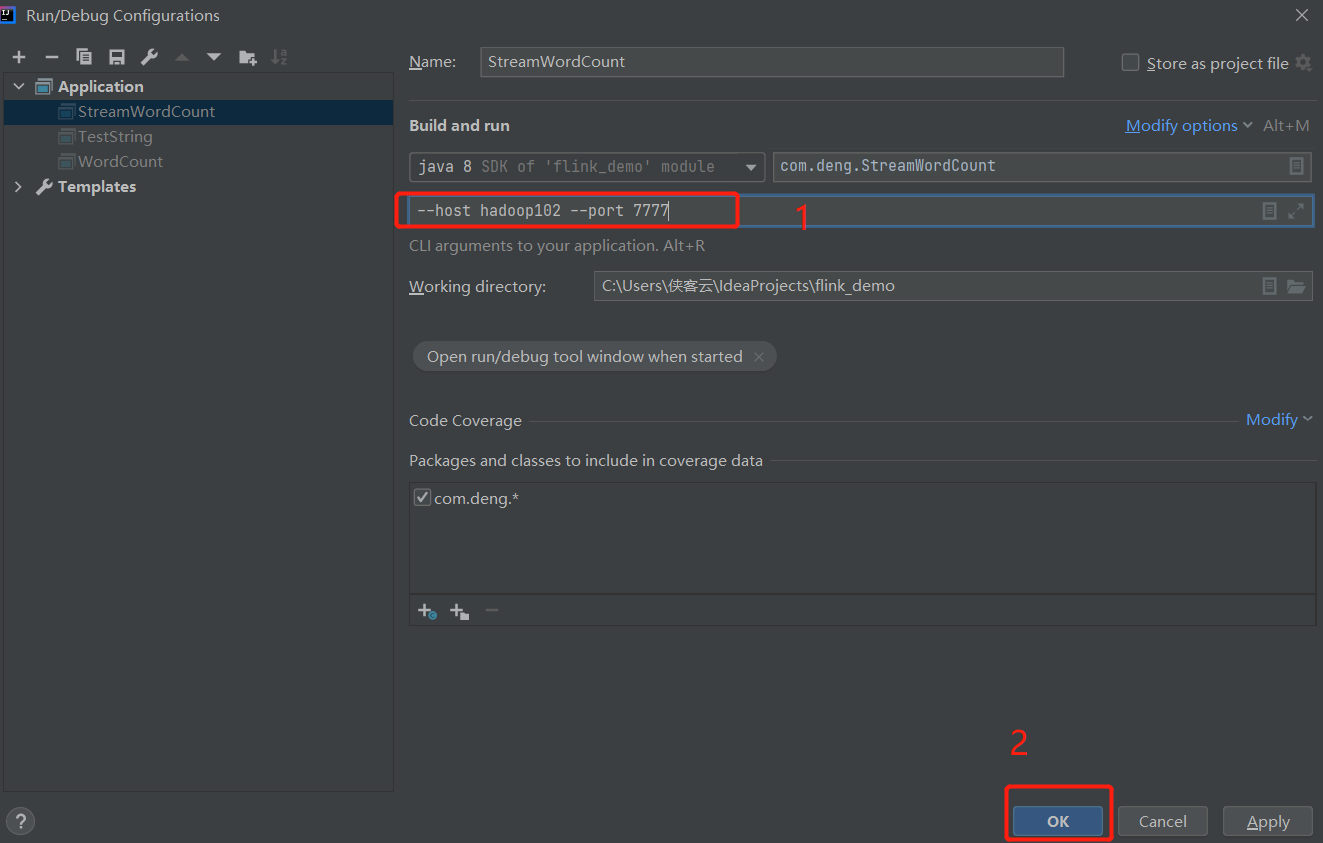
标签:流处理 location get fun word 获取 inpu targe int()
原文地址:https://www.cnblogs.com/knighterrant/p/14747603.html