标签:insert alt 开始 iter 代码 前言 恢复 packet 出现
前言
最近有个需求解析一个订单文件,并且说明文件可达到千万条数据,每条数据大概在20个字段左右,每个字段使用逗号分隔,需要尽量在半小时内入库。
思路
1.估算文件大小
因为告诉文件有千万条,同时每条记录大概在20个字段左右,所以可以大致估算一下整个订单文件的大小,方法也很简单使用FileWriter往文件中插入一千万条数据,查看文件大小,经测试大概在1.5G左右;
2.如何批量插入
由上可知文件比较大,一次性读取内存肯定不行,方法是每次从当前订单文件中截取一部分数据,然后进行批量插入,如何批次插入可以使用insert(...)values(...),(...)的方式,经测试这种方式效率还是挺高的;
3.数据的完整性
截取数据的时候需要注意,需要保证数据的完整性,每条记录最后都是一个换行符,需要根据这个标识保证每次截取都是整条数,不要出现半条数据这种情况;
4.数据库是否支持批次数据
因为需要进行批次数据的插入,数据库是否支持大量数据写入,比如这边使用的mysql,可以通过设置max_allowed_packet来保证批次提交的数据量;
5.中途出错的情况
因为是大文件解析,如果中途出现错误,比如数据刚好插入到900w的时候,数据库连接失败,这种情况不可能重新来插一遍,所有需要记录每次插入数据的位置,并且需要保证和批次插入的数据在同一个事务中,这样恢复之后可以从记录的位置开始继续插入。
实现
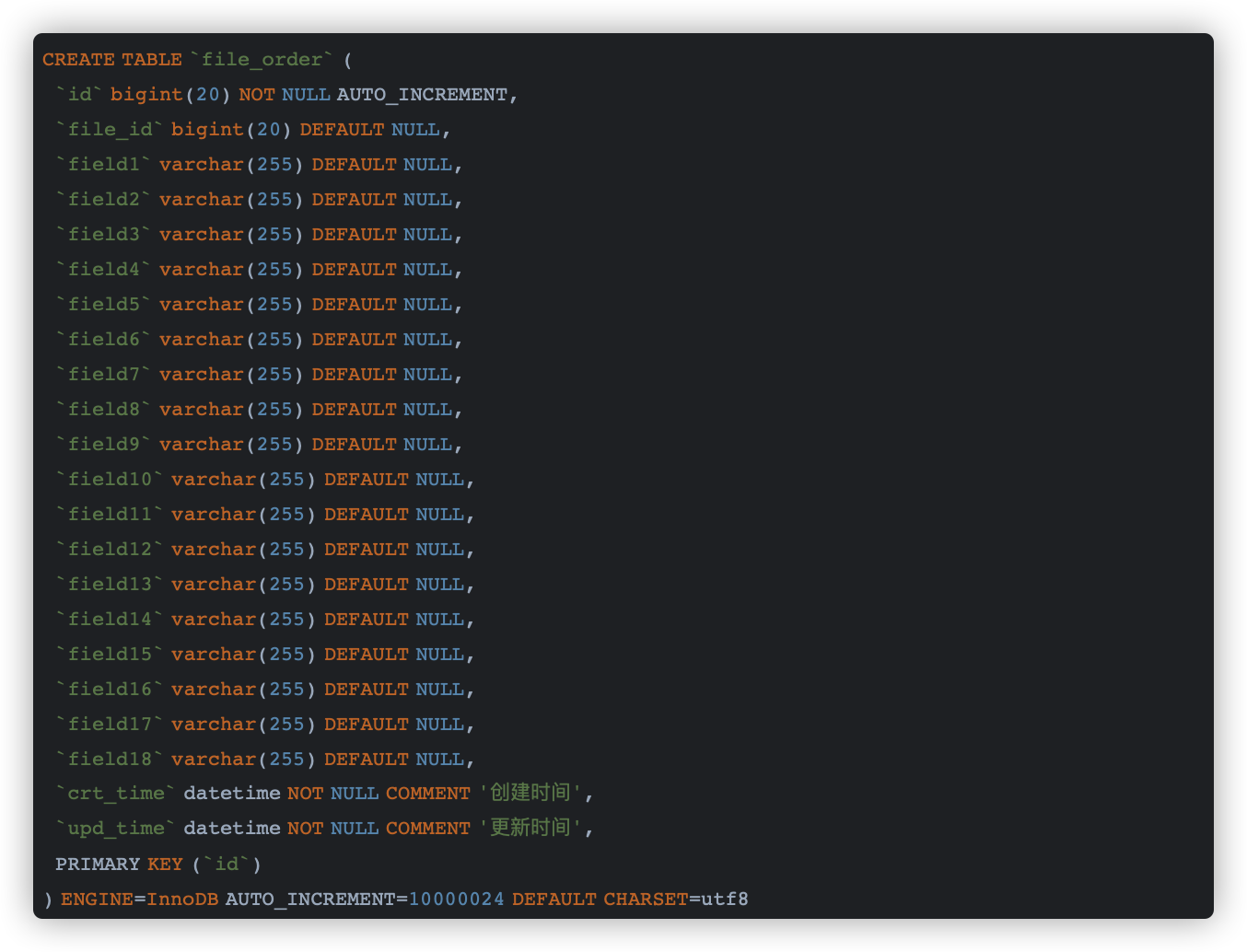
1.准备数据表
这里需要准备两张表分别是:订单状态位置信息表,订单表;

2.配置数据库包大小
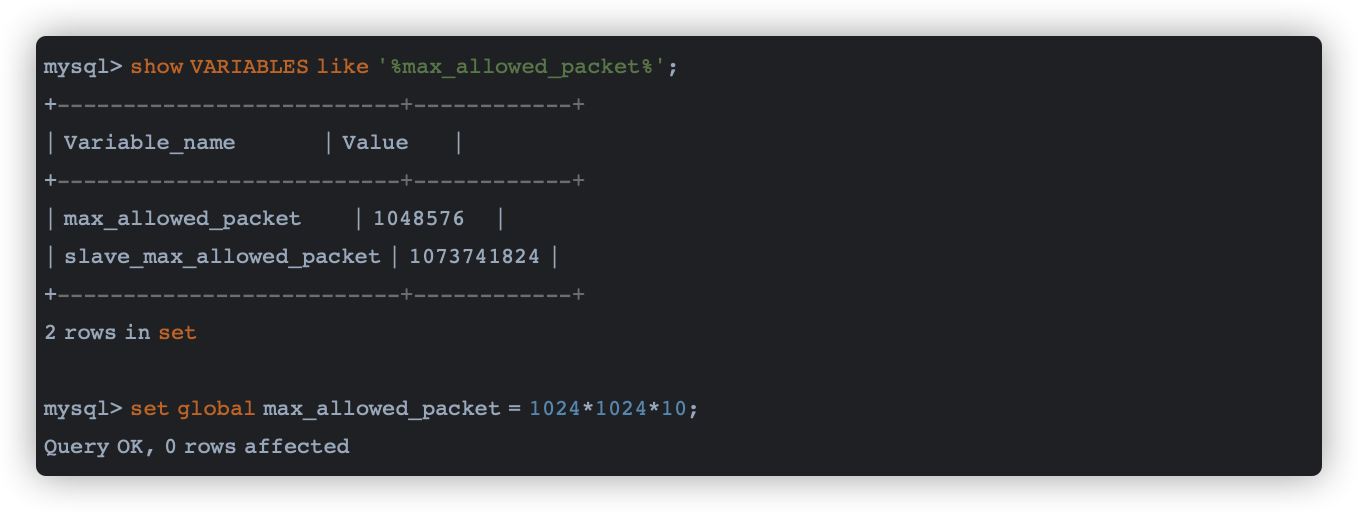
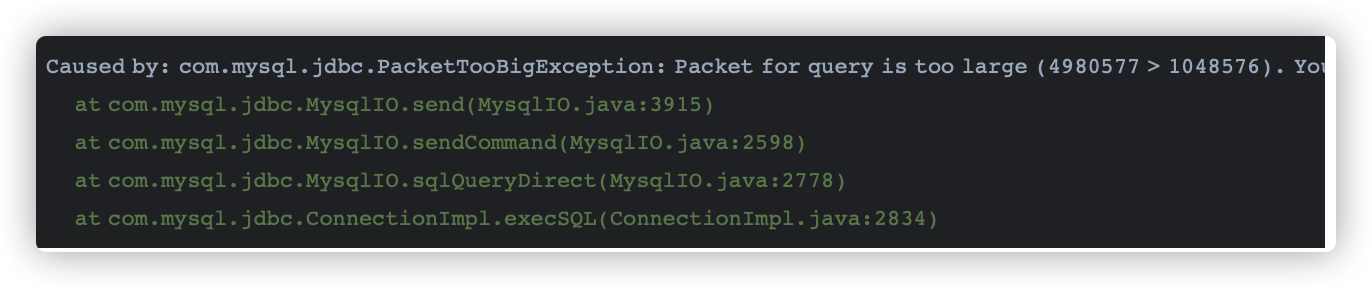
通过设置max_allowed_packet,保证数据库能够接收批次插入的数据包大小;不然会出现如下错误:
3.准备测试数据
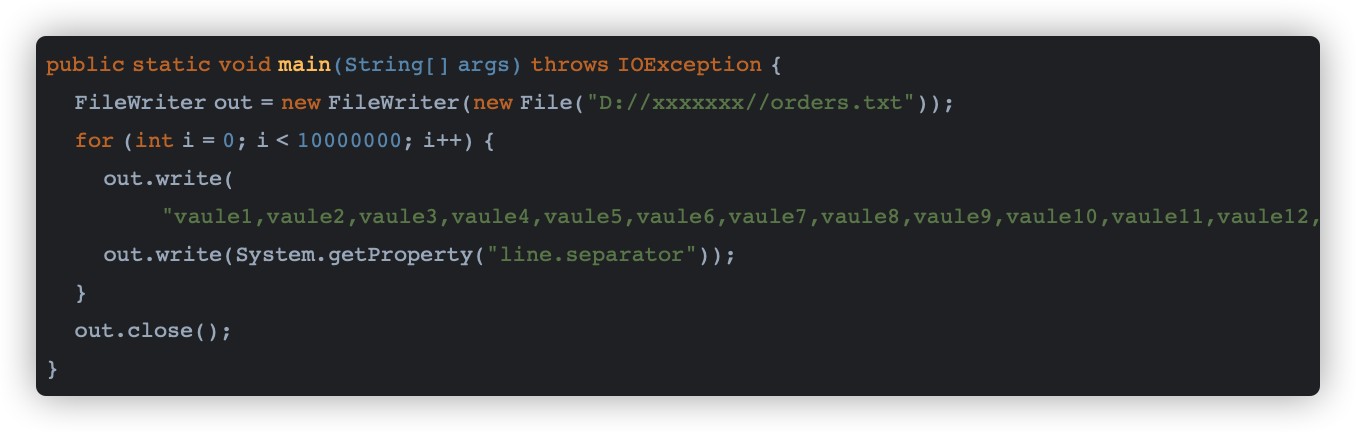
使用FileWriter遍历往一个文件里插入1000w条数据即可,这个速度还是很快的,不要忘了在每条数据的后面添加换行符(\n\r);
4.截取数据的完整性
除了需要设置每次读取文件的大小,同时还需要设置一个参数,用来每次获取一小部分数据,从这小部分数据中获取换行符(\n\r),如果获取不到一直累加直接获取为止,这个值设置大小大致同每条数据的大小差不多合适,部分实现如下:
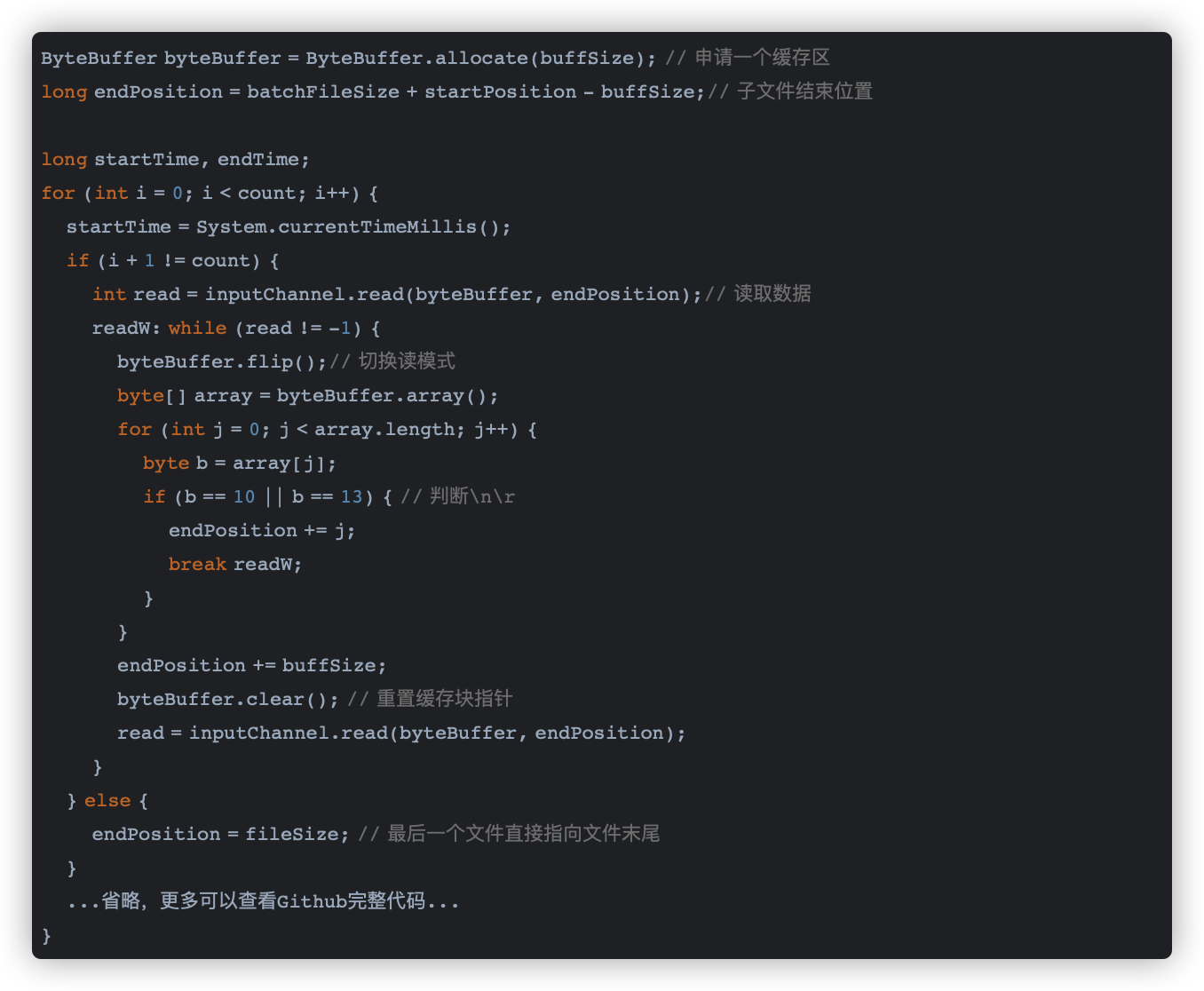
如上代码所示开辟了一个缓冲区,根据每行数据大小来定大概在200字节左右,然后通过遍历查找换行符(\n\r),找到以后将当前的位置加到之前的结束位置上,保证了数据的完整性;
5.批次插入数据
通过insert(...)values(...),(...)的方式批次插入数据,部分代码如下:
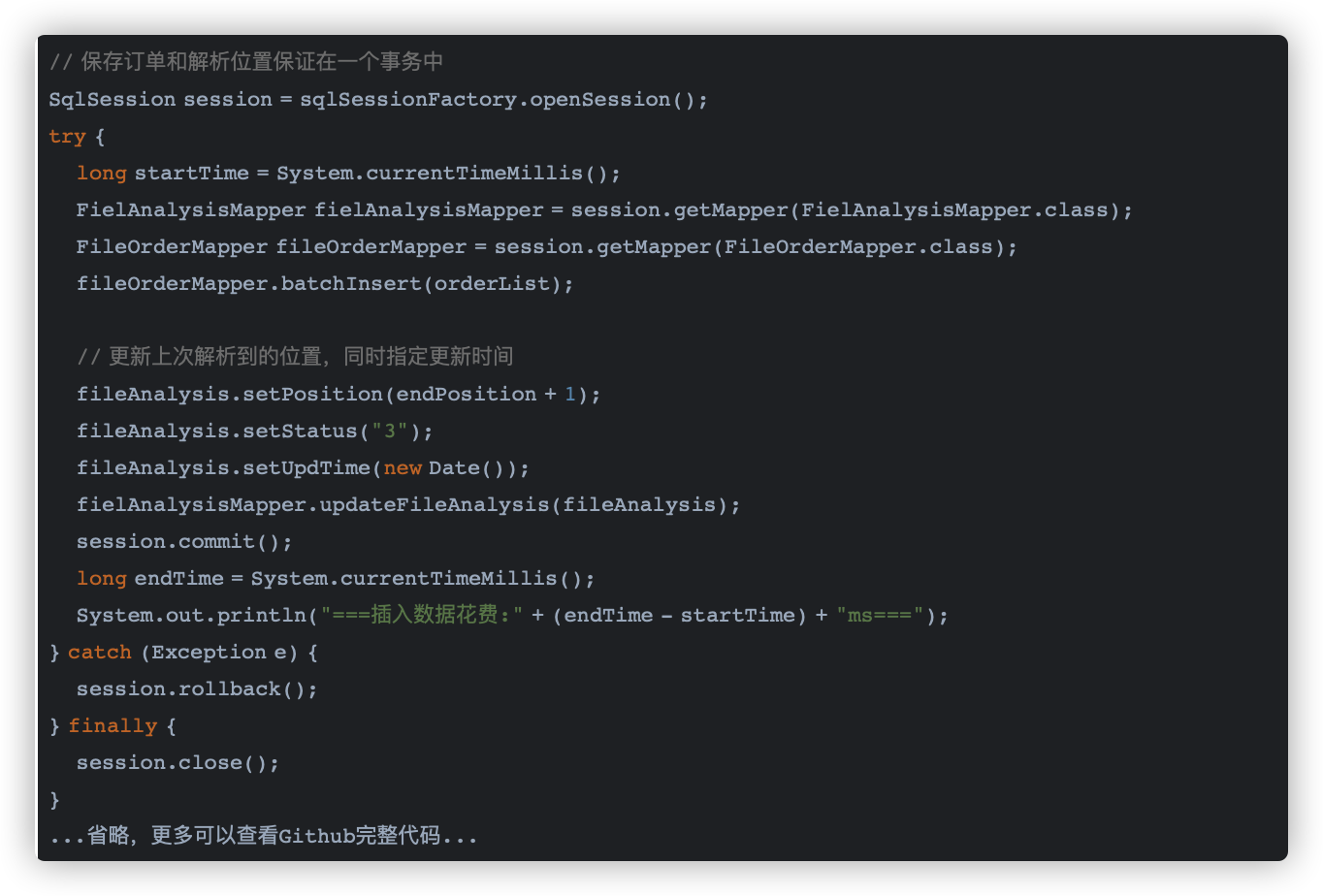
如上代码在一个事务中同时保存批次订单数据和文件解析位置信息,batchInsert通过使用mybatis的
总结
以上展示了部分代码,完整的代码可以查看Github地址中的batchInsert模块,本地设置每次截取的文件大小为2M,经测试1000w条数据(大小1.5G左右)插入mysql数据库中,大概花费时间在20分钟左右,当然可以通过设置截取的文件大小,花费的时间也会相应的改变。
完整代码
https://github.com/ksfzhaohui/blog/tree/master/mybatis
标签:insert alt 开始 iter 代码 前言 恢复 packet 出现
原文地址:https://www.cnblogs.com/z-x-f/p/14753961.html