标签:文件表 context and 重试 stack loading 性能 函数实现 处理机
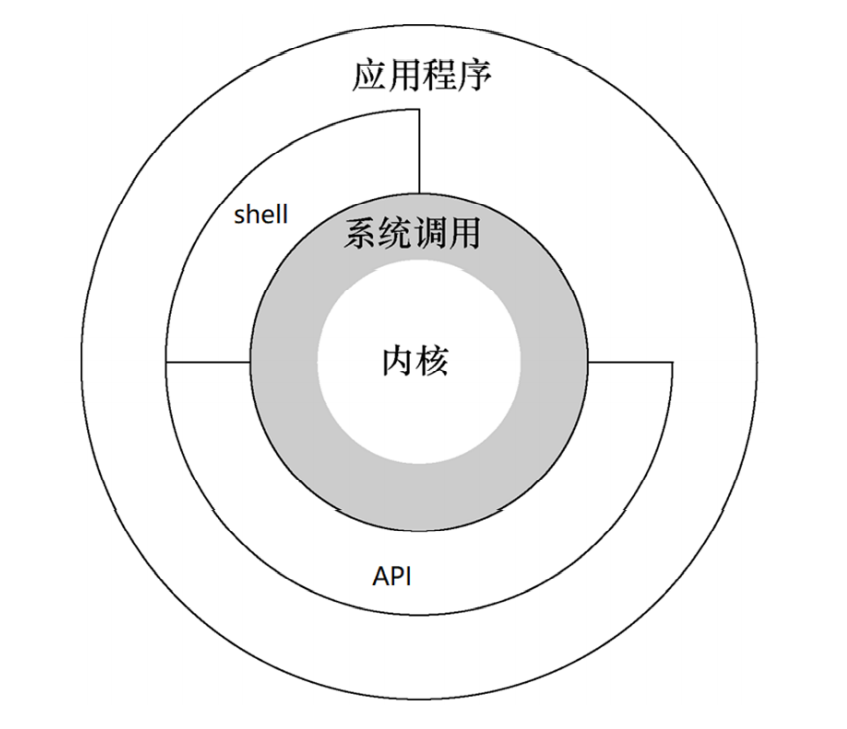
操作系统是管理计算机硬件与软件资源的计算机程序一般由内核、shell 和应用程序组成。核心是内核,控制着计算机系统上的所有硬件和软件,在必要时分配硬件,并根据需要执行软件。内核主要负责进程管理、内存管理、文件系统等。
? 进程管理模块主要是对进程使用的处理机进行管理和控制。Linux以进程作为系统资源分配的基本单位,并采用动态优先级的进程高级算法,保证各个进程使用处理机的合理性。使用的调度策略有:先进先出的实时进程、时间片轮转的实时进程、普通的分时进程。
? 内存管理模块采用了虚拟存储机制,实现对多进程的存储管理,使得每个进程都有各自互不干涉的进程地址空间。
? 文件系统模块采用了虚拟文件系统(VFS),屏蔽了各种文件系统的差别,为处理各种不同的文件系统提供了统一的接口,支持多种不同的物理文件系统。同时,Linux把各种硬件设备看作一种特殊的文件来处理,用管理文件的方法管理设备,非常方便、有效。
进程的描述
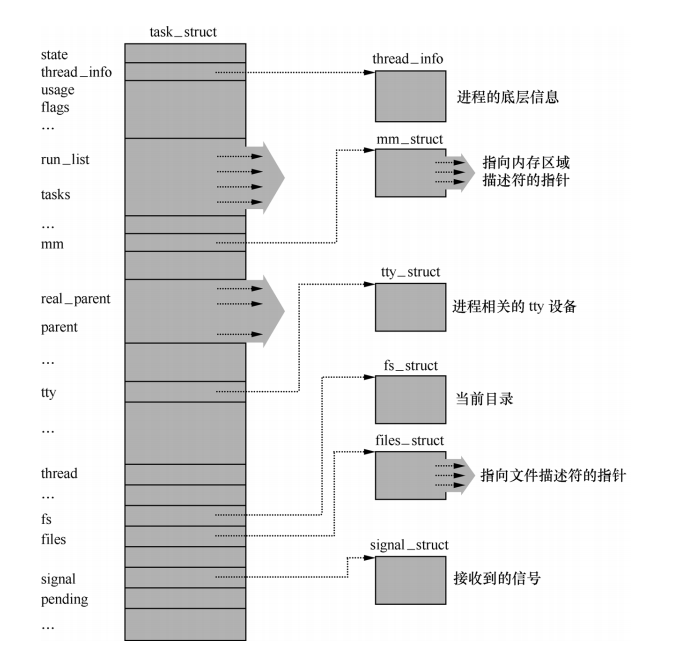
在Linux内核中用一个数据结构struct task_struct来描述进程,其中state是进程状态, stack是堆栈等,通过如图所示的进程描述符的结构示意图从总体上看清structtask_struct的结构关系。
进程状态
操作系统原理中的进程有就绪态、运行态、阻塞态这 3 种基本状态,实际的 Linux 内核管理的进程状 态与这 3 个状态是很不一样的。如图所示为 Linux 内核管理的进程状态转换图。
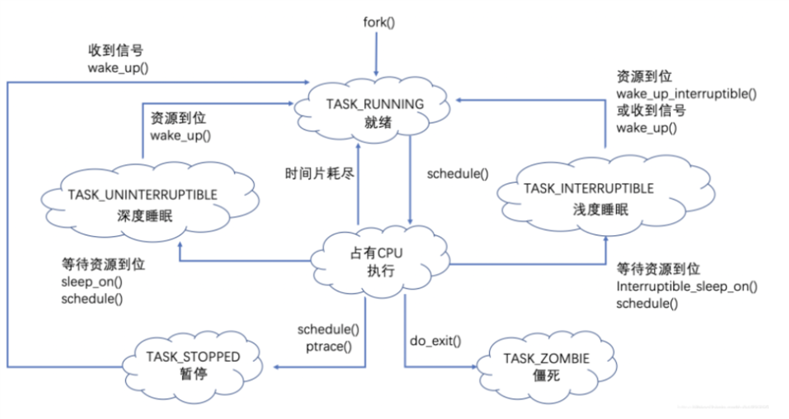
其中当使用 fork()系统调用来创建一个新进程时,新进程的状态是 TASK_RUNNING(就 绪态,但是没有在运行)。当调度器选择这个新创建的进程运行时,新创建的进程就切换 到运行态,它也是 TASK_RUNNING。也就是说,在 Linux 内核中,当进程 是 TASK_RUNNING 状态时,它是可运行的,也就是就绪态,是否在运行取决于它有没 有获得 CPU 的控制权,也就是说这个进程有没有在 CPU 中实际执行。如果在 CPU 中实 际执行了,进程状态就是运行态;如果被内核调度出去了,在等待队列里就是就绪态。
进程调度
Linux内核通过schedule函数实现进程调度,schedule函数负责在运行队列中选择一个进程,然后把它切换到CPU上执行。调用schedule函数的时机主要分为两类:
(1)中断处理过程中的进程调度时机,中断处理过程中会在适当的时机检测need_resched标记,决定是否调用schedule()函数。比如在系统调用内核处理函数执行完成后且系统调用返回之前就会检测need_resched标记决定是否调用schedule()函数。
(2)内核线程主动调用schedule(),如内核线程等待外设或主动睡眠等情形下,或者在适当的时机检测need_resched标记,决定是否主动调用schedule函数。
进程的切换
为了控制进程的执行,内核必须有能力挂起正在CPU上运行的进程,并恢复执行以前挂起的某个进程。这种行为被称为进程切换、任务切换或进程上下文切换。在进程切换时,需要保存当前进程的所有信息,如用户地址空间、控制信息、进程的CPU上下文,和相关寄存器的值。schedule()函数选择一个新的进程来运行,并调用context_switch进行上下文的切换。context_switch()首先调用switch_mm切换地址空间,然后调用switch_to()进行CPU上下文切换。
Linux 操作系统采用 0 和 3 两个特权级别,分别对应内核 态和用户态,区分方法就是 CS:EIP 的指向范围,在内核态时,CS:EIP 的值可以是任意的地址,在 32 位的 x86 机器上有 4GB 的进程地址空间,内核态下的这 4GB 的地址空间全都可以访问。但是在用户态时,只能访问 0x00000000~0xbfffffff 的地址空间,0xc0000000 以上的地址空间只能在内核态下访问。
发生从用户态到内核态的切换,一般存在以下三种情况:
1)库函数、系统调用或者shell命令。
2)异常事件: 当CPU正在执行运行在用户态的程序时,突然发生某些预先不可知的异常事件,这个时候就会触发从当前用户态执行的进程转向内核态执行相关的异常事件,典型的如缺页异常。
3)外围设备的中断:当外围设备完成用户的请求操作后,会像CPU发出中断信号,此时,CPU就会暂停执行下一条即将要执行的指令,转而去执行中断信号对应的处理程序,如果先前执行的指令是在用户态下,则自然就发生从用户态到内核态的转换。
总而言之就是通过中断。Linux 下系统调用通过 int 0x80 中断完成,中断保 存了用户态 CS:EIP 的值,以及当前的堆栈段寄存器的栈顶,将 EFLAGS 寄存器的当前的 值保存到内核堆栈里,同时把当前的中断信号或者是系统调用的中断服务程序的入口加载到 CS:EIP 里,把当前的堆栈段 SS:ESP 也加载到 CPU 里,这些都是由中断信号或者是 int 指令来完成的。完成后,当前 CPU 在执行下一条指令时就已经开始执行中断处理程序的入 口了,这时对堆栈的操作已经是内核堆栈操作了,之前的 SAVE_ALL 就是内核代码,完成 中断服务,发生进程调度。如果没有发生进程调度,就直接 restore_all 恢复中断现场,然 后 iret 返回到原来的状态;如果发生了进程调度,当前的这些状态都会暂时地保存在系统 内核堆栈里,当下一次发生进程调度有机会再切换回当前进程时,就会接着把 restore_all 和 iret 执行完,这样中断处理过程就执行完了
文件是具有符号名的、在逻辑上具有完整意义的一组相关信息项的有序序列。文件系统,就是操作系统中实现文件统一管理的一组软件、被管理的文件以及为实施文件管理所需要的一些数据结构的总称。要实现操作系统对其他各种不同文件系统的支持,就要将对各种不同文件系统的操作和管理纳入到一个统一的框架中。对用户程序隐去各种不同文件系统的实现细节,为用户程序提供一个统一的、抽象的、虚拟的文件系统界面,这就是所谓的虚拟文件系统VFS。通常,虚拟文件系统分为三个层次:
第一层为文件系统接口层,如open/write/close等系统调用接口。
第二层为VFS接口层。该层有两个接口:一个是与用户的接口;一个是与特定文件系统的接口。VFS与用户的接口将所有对文件的操作定向到相应的特定文件系统函数上。VFS与特定文件系统的接口主要是通过VFS-operations实现。
第三层是具体文件系统层,提供具体文件系统的结构和实现,包括网络文件系统,如NFS。
文件打开和读写的流程:
1. 进程X读写一个文件首先要使用open系统调用打开这个文件,根据给出的文件路径获取它在哪个存储设备上(FAT32格式的u盘、NTFS格式的磁盘等等),可以找到该设备对应的设备文件的文件控制块inode,inode里有对应的设备号,根据设备号可以找到对应的驱动程序。在内核初始化时已经将各个设备的设备驱动程序注册到内核,并为他们生成对应的设备文件,设备文件向上提供统一的接口如open()、read()等,方便调用。而open系统调用会新建一个file结构,并在进程X的进程打开文件表的fd数组里找到空闲的一项,指向刚创建的file结构,然后返回fd数组的下标。假如要访问的文件存储在FAT32格式的块设备上,程序员写的驱动程序包括具体的针对FAT32的读写打开关闭等函数,他们已经被注册到内核,通过设备号就能找到对应的驱动程序,然后用具体的操作函数来初始化设备文件的文件控制块inode节点里的cdev,再用inode节点的cdev初始化系统文件打开表file结构里的file_operations。以上都是open系统调用内核干的事,直观上来说就是内核向用户态返回了一个整数(fd数组的下标)。
2. 进程X使用read系统调用读这个文件,就会根据参数:fd数组的下标 找到fd数组的对应项,进而找到指向第1步创建的file结构的指针,进而找到这个file结构,进而找到file结构里的file_operations里的具体的read函数来读取文件,这是一个从抽象到具体的过程。最后系统调用返回告诉用户态进程X读操作成功与否。
3. 进程X使用write系统调用写数据到这个文件,就会根据参数:fd数组的下标 找到fd数组的对应项,进而找到指向第1步创建的file结构的指针,进而找到这个file结构,进而找到file结构里的file_operations里的具体的write函数来写文件,这也是一个从抽象到具体的过程。最后系统调用返回告诉用户态进程X写操作成功与否。
第一个终端里运行 sysbench ,模拟系统多线程调度的瓶颈:
# 以10个线程运行5分钟的基准测试,模拟多线程切换的问题 sysbench --threads=10 --max-time=300 threads run
在第二个终端运行 vmstat ,观察上下文切换情况:
# 每隔1秒输出1组数据(需要Ctrl+C才结束) vmstat 1 procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu---- r b swpd free buff cache si so bi bo in cs us sy id wa s 6 0 0 6487428 118240 1292772 0 0 0 0 9019 1398830 16 84 0 8 0 0 6487428 118240 1292772 0 0 0 0 10191 1392312 16 84
cs 列:上下文切换次数骤然上升到了 139 万
r 列:就绪队列的长度已经到了 8,远远超过了系统 CPU 的个数 2,所以肯定会有大量的 CPU 竞争
us(user)和 sy(system)列:这两列的 CPU 使用率加起来上升到了 100%,其中sy 列高达 84%
in 列:中断次数也上升到了 1 万左右,说明中断处理也是个潜在的问题。
综合这几个指标可以知道,系统的就绪队列过长,也就是正在运行和等待 CPU 的进程数过多,导致了大量的上下文切换,而上下文切换又导致了系统 CPU 的占用率升高。
在第三个终端再用 pidstat 来看一下, CPU 和进程上下文切换的情况:
# 每隔1秒输出1组数据(需要 Ctrl+C 才结束) # -w参数表示输出进程切换指标,而-u参数则表示输出CPU使用指标 pidstat -w -u 1 08:06:33 UID PID %usr %system %guest %wait %CPU CPU Command 08:06:34 0 10488 30.00 100.00 0.00 0.00 100.00 0 sysbench 08:06:34 0 26326 0.00 1.00 0.00 0.00 1.00 0 kworker/u4:2 08:06:33 UID PID cswch/s nvcswch/s Command 08:06:34 0 8 11.00 0.00 rcu_sched 08:06:34 0 16 1.00 0.00 ksoftirqd/1 08:06:34 0 471 1.00 0.00 hv_balloon 08:06:34 0 1230 1.00 0.00 iscsid 08:06:34 0 4089 1.00 0.00 kworker/1:5 08:06:34 0 4333 1.00 0.00 kworker/0:3 08:06:34 0 10499 1.00 224.00 pidstat 08:06:34 0 26326 236.00 0.00 kworker/u4:2 08:06:34 1000 26784 223.00 0.00 sshd
从 pidstat 的输出可以发现,CPU 使用率的升高果然是 sysbench 导致的,它的 CPU 使用率已经达到了 100%。但上下文切换则是来自其他进程,包括非自愿上下文切换频率最高的 pidstat ,以及自愿上下文切换频率最高的内核线程 kworker 和 sshd。
另外可以看到,pidstat 输出的上下文切换次数,加起来也就几百,比 vmstat 的 139 万明显小了太多。
Linux 调度的基本单位实际上是线程,而场景 sysbench 模拟的也是线程的调度问题,那么,是不是 pidstat 忽略了线程的数据呢?通过运行 man pidstat ,pidstat 默认显示进程的指标数据,加上 -t 参数后,才会输出线程的指标。
在第三个终端里再加上 -t 参数,重试一下看看:
# 每隔1秒输出一组数据(需要 Ctrl+C 才结束) # -wt 参数表示输出线程的上下文切换指标 pidstat -wt 1 08:14:05 UID TGID TID cswch/s nvcswch/s Command ... 08:14:05 0 10551 - 6.00 0.00 sysbench 08:14:05 0 - 10551 6.00 0.00 |__sysbench 08:14:05 0 - 10552 18911.00 103740.00 |__sysbench 08:14:05 0 - 10553 18915.00 100955.00 |__sysbench 08:14:05 0 - 10554 18827.00 103954.00 |__sysbench
现在就能看到虽然 sysbench 进程(也就是主线程)的上下文切换次数看起来并不多,但它的子线程的上下文切换次数却有很多。上下文切换罪魁祸首,还是过多的sysbench 线程。
标签:文件表 context and 重试 stack loading 性能 函数实现 处理机
原文地址:https://www.cnblogs.com/kongwy/p/14762798.html