标签:时间 info region 语句 paper 没有 log bsp tin
在搜索领域,索引是一项非常重要的技术,直接影响到查询的效率,其基本的流程是:文章先进行分词、计算权重,然后利用词和文档的信息建立倒排索引,在查询的时候,得到符合条件的文档的id集合,然后利用正排索引返回文档的详细信息。
在计算广告中,广告主通常会定义广告投放的条件,例如下面有3个广告,每个广告都有自己的定向条件
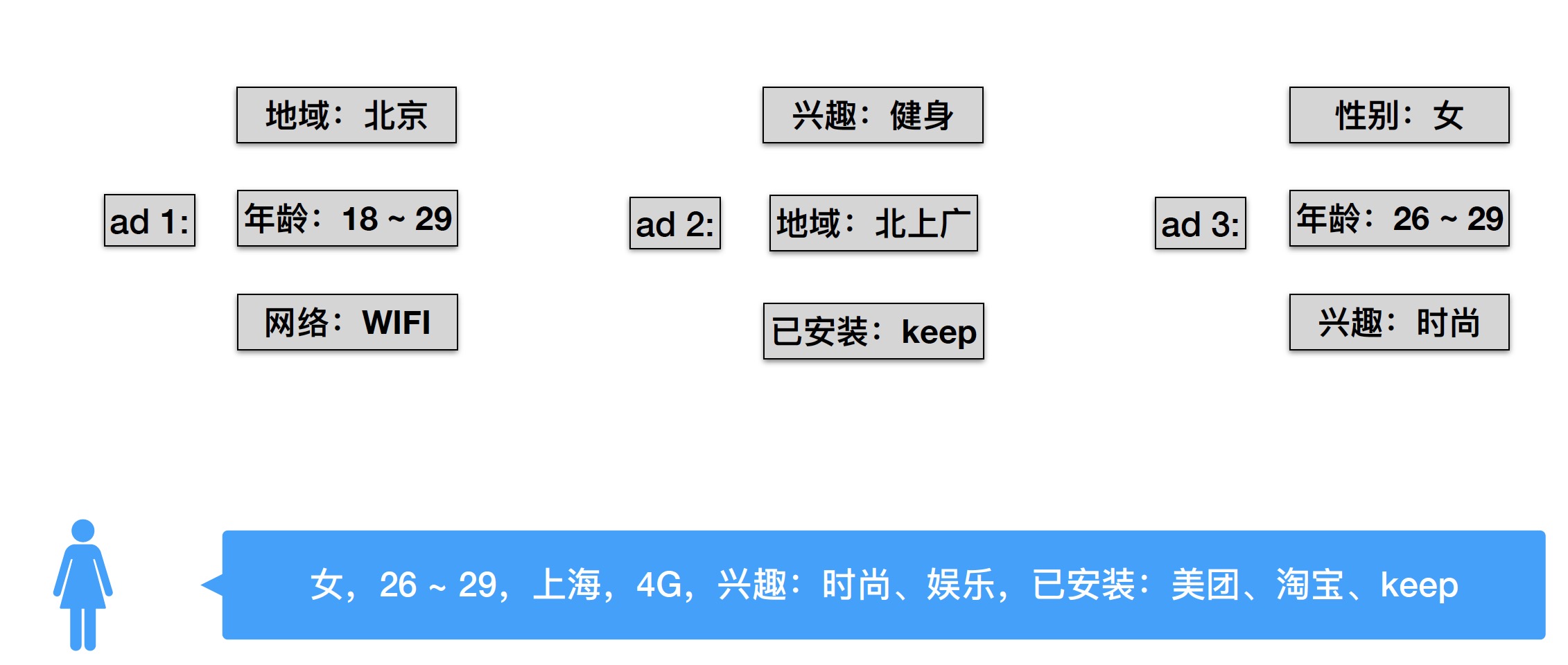
如果此时有一个用户来访问(后面称为query ),该用户的画像如上面蓝色部分。那么这3个 ad 应该给她返回哪个更合理呢?
我们可以把这个用户每个维度的特征去与每个 ad 进行匹配,会发现只有 ad3 的定向投放条件都符合。
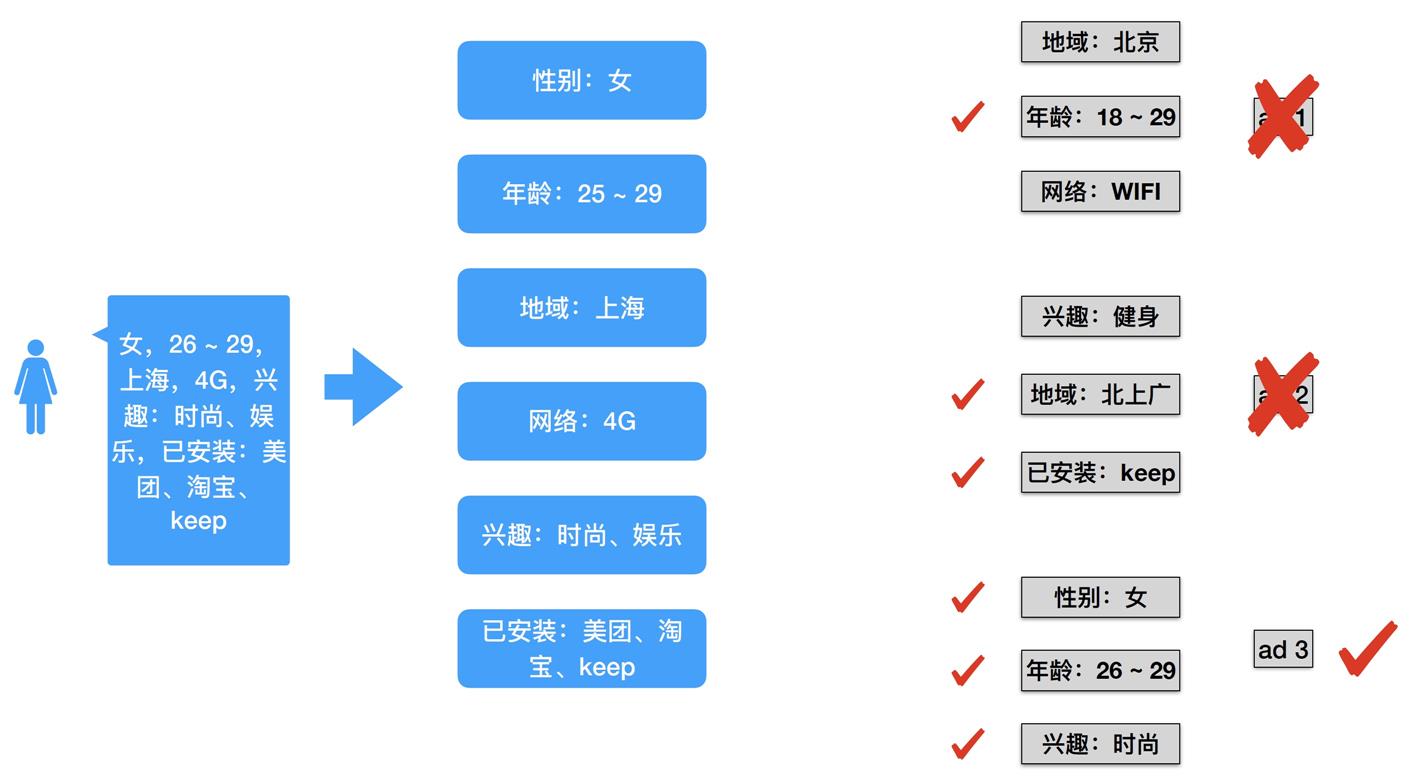
实际的广告平台可能有几十万条广告,就需要一个方案来高效检索符合给当前请求的用户投放的广告。
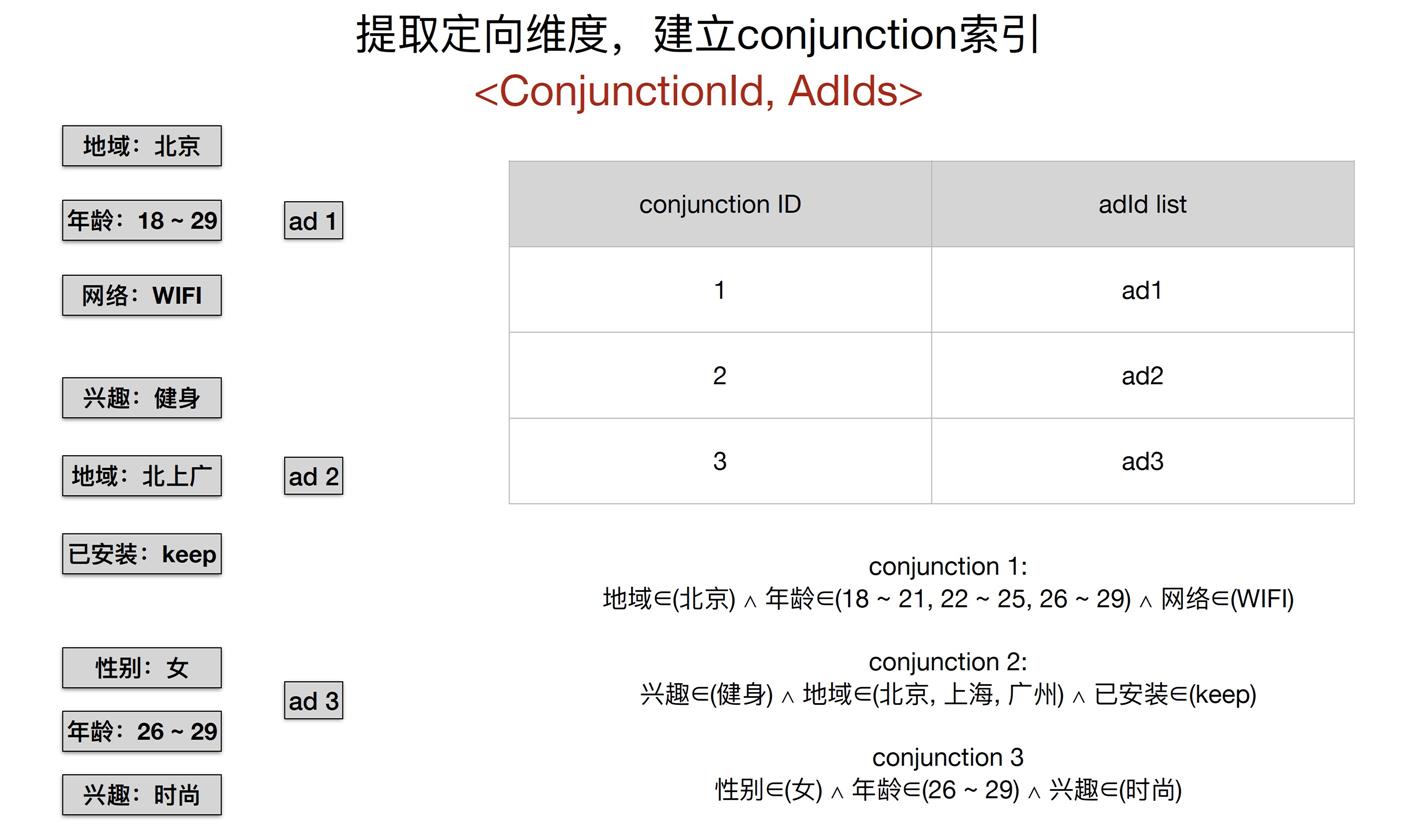
用 Conjunction 表示某条广告的广告主的要求的一类人群。
例如上面的 ad1 的 Conjunction:
age ∈ { 18-29 } ∧ region ∈ { BJ } ∧ network ∈ { WIFI }
这里符号 ∈ 是属于,? 是不属于,∧ 是交, ∨ 是并;
用 Assignment 表示一个维度,例如上面 ad1 的 Conjunction包括如下Assignment
age ∈ { 18-29 }
region ∈ { BJ }
network ∈ { WIFI }
最后,说下 sizeof(Conjunction) 是指 conjunction 中包含非? 的Assignment的个数。
广告的倒排索引包括两层:
当一个用户的请求(query)来之后,我们需要把query的所有维度去 第一层索引 找出所有符合的 ConjunctionIds(这里求交),然后再去 第二层索引 召回广告(这里求并);
这里可以利用 Assignment 约束: 如果 sizeof(query) < sizeof(Conjunction) , 则检索时可以跳过该Conjunction(因为该query肯定不满足该广告的所有定向条件)。
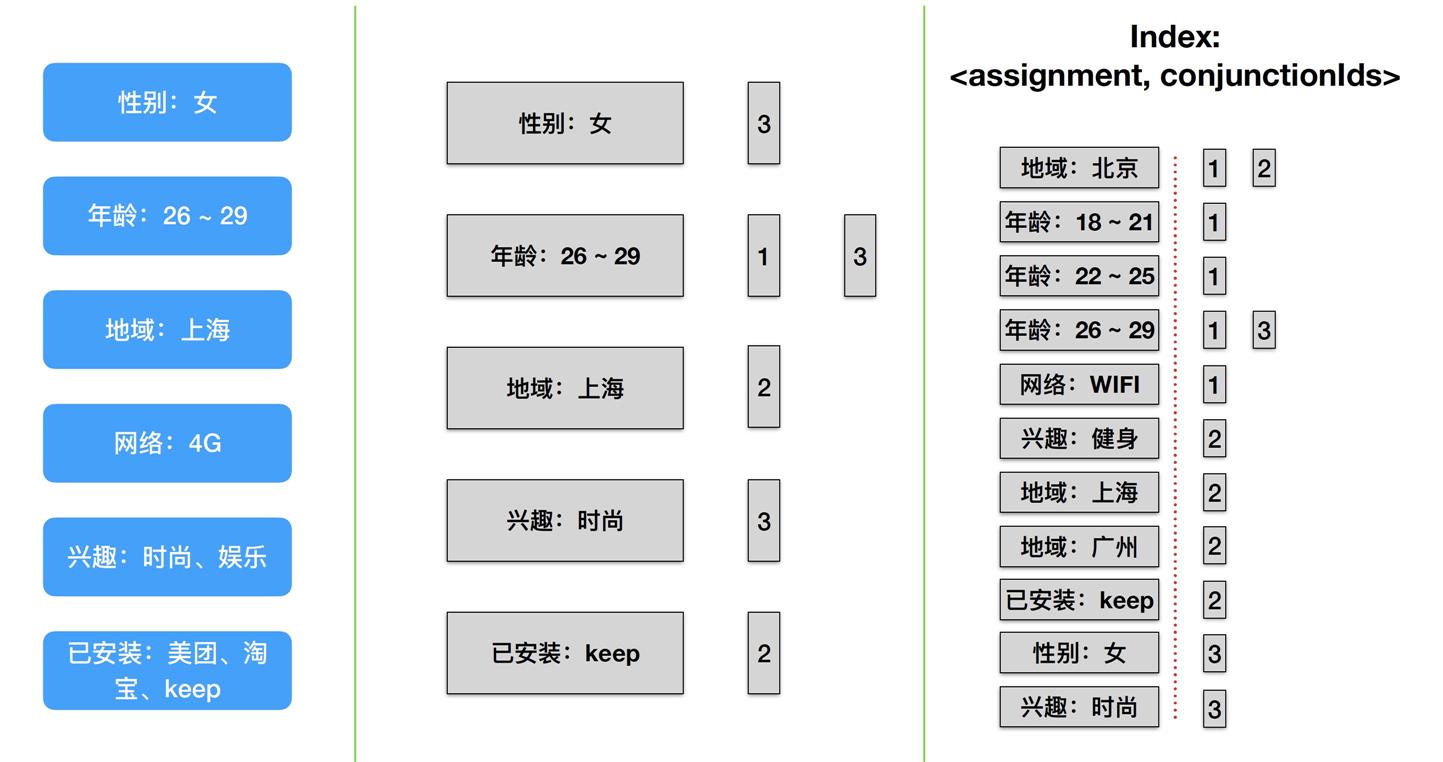
回到前面的例子,ad1 - ad3 的第一层索引:
第二层索引:

可以看到,这里年龄可以切成多个key。
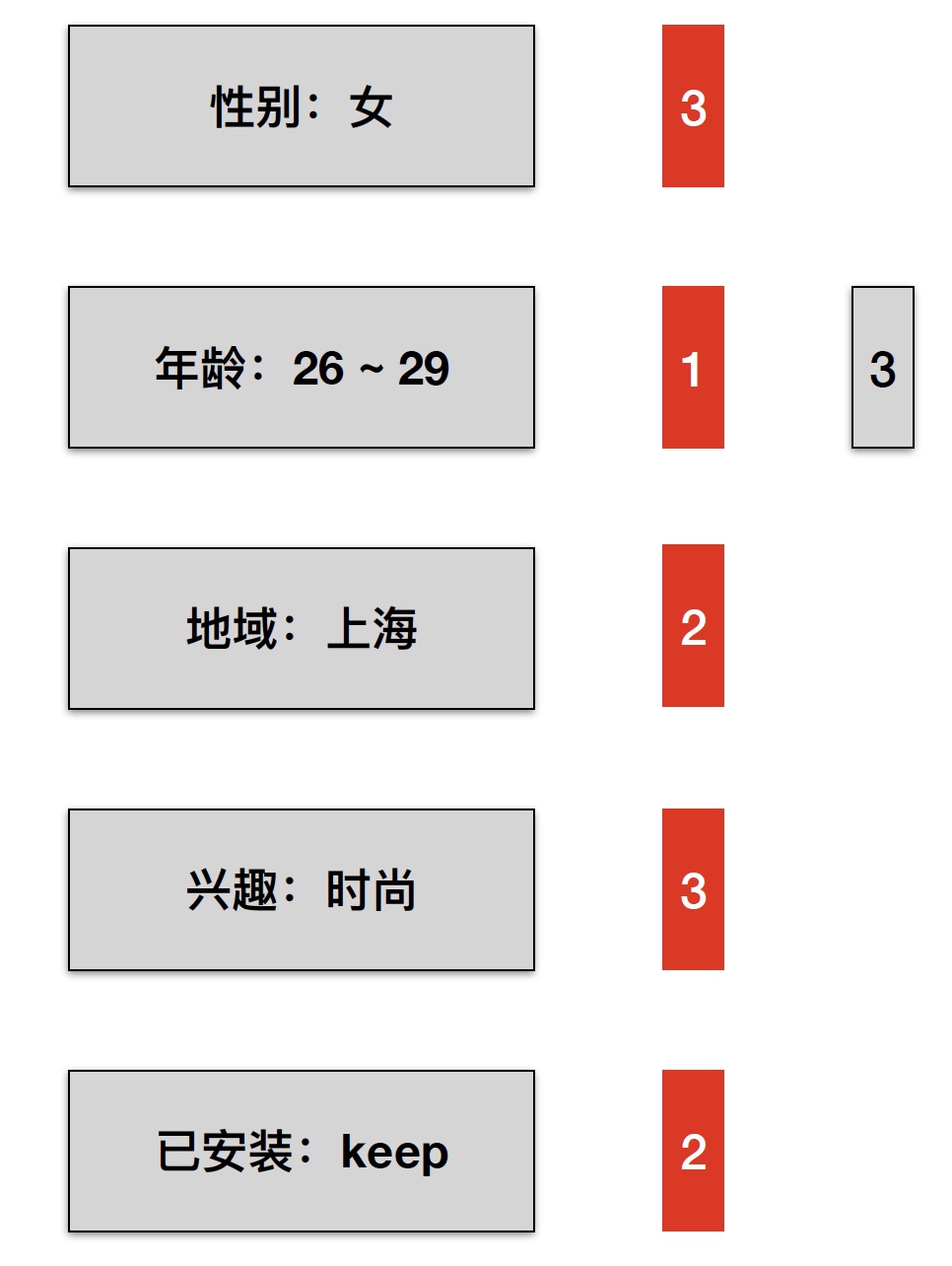
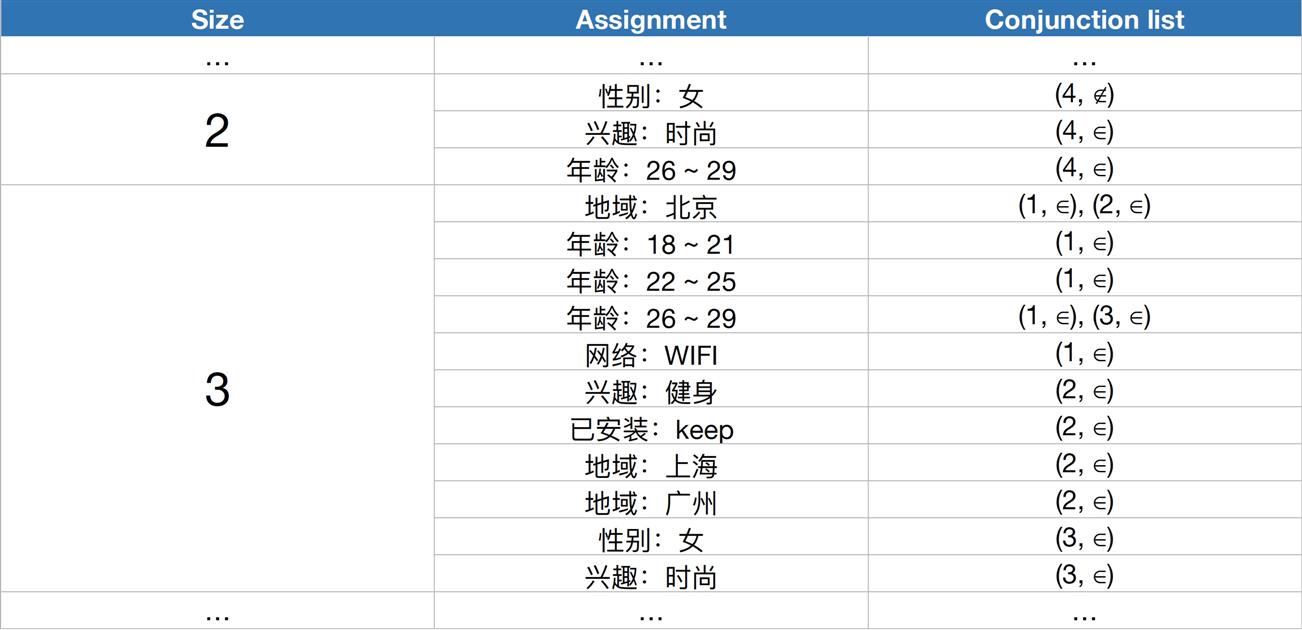
另外,利用上面说的 Assignment 约束规则,第二层索引还可以按照 sizeof(Conjunction) 分成若干部分,提高检索效率。如下图:
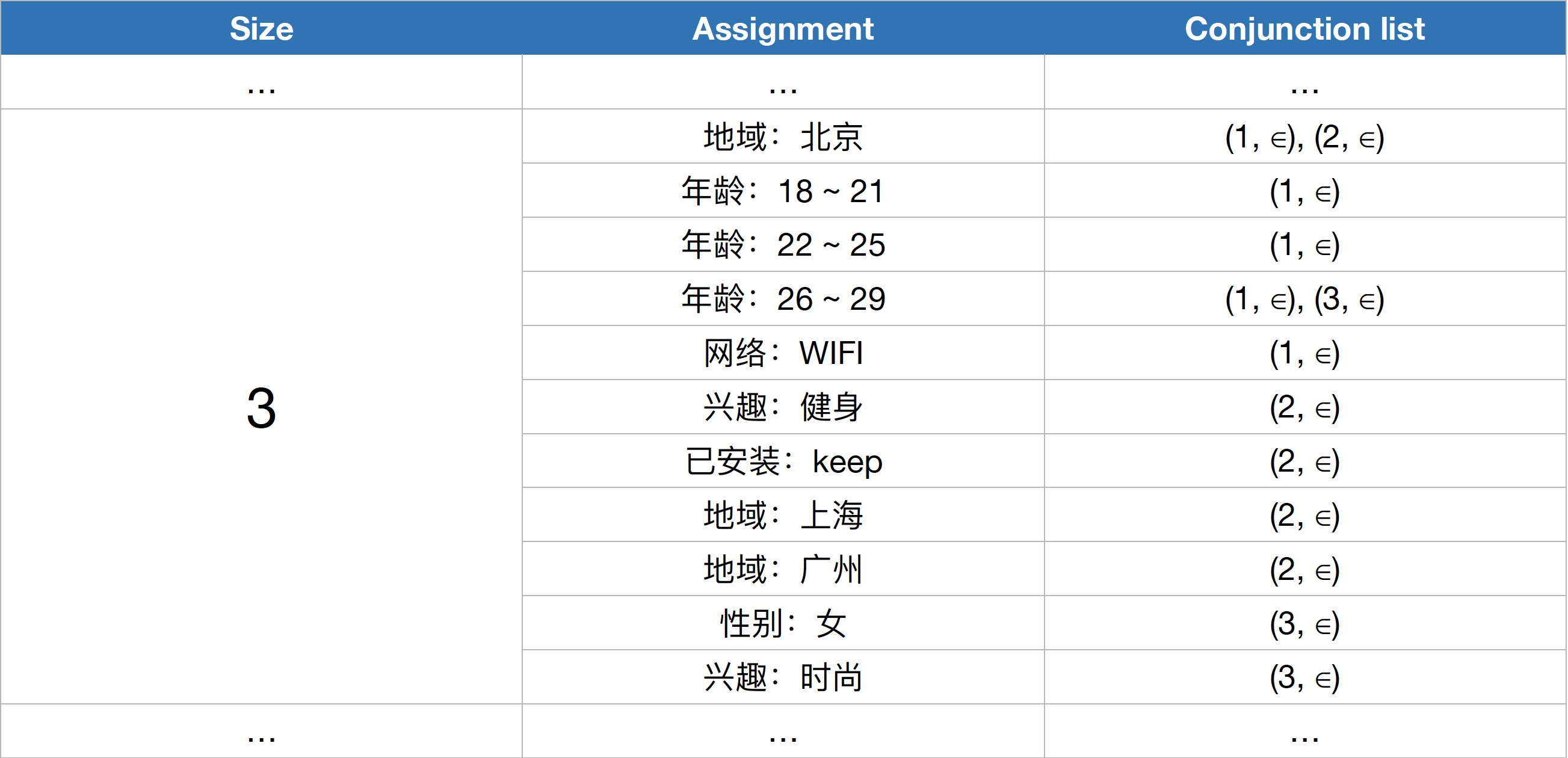
此时,如果请求的 sizeof(query) = 2,那么 sizeof(Conjunction) > 2 的 Key(Assignment) 可以直接跳过不用检索。
再来看请求侧:

检索过程:
这里,query中的“网络”这个维度没有结果,但没关系,其它 Assignment 都有结果,接下来就是看如何匹配了。
为了提高检索效率,在第二层索引,一般遵守如下规则:
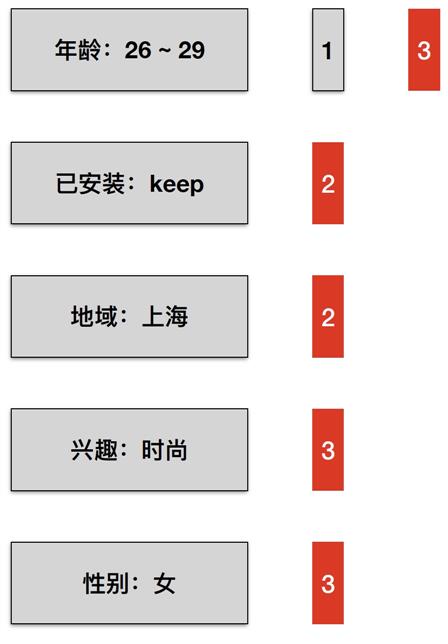
我们看下上面检索的结果, 按上面的规则排序后:
先将每个 Posting list 内部entry排序,然后不停 Posting list 按其第一个 entry (即 Conjunction=1 )排序,可以得到:
这里我们看下 1 这个 entry,只出现了一次,显然不匹配(需要出现在3个key 中才满足所有定向条件);
接下来,每个Posting list 按第2个 entry(即 Conjunction=2 )排序:

第2个 entry出现了2次,也不满足sizeof(Conjunction)=3 的条件;
继续对 第3个 entry(即 Conjunction=3 ) 排序,
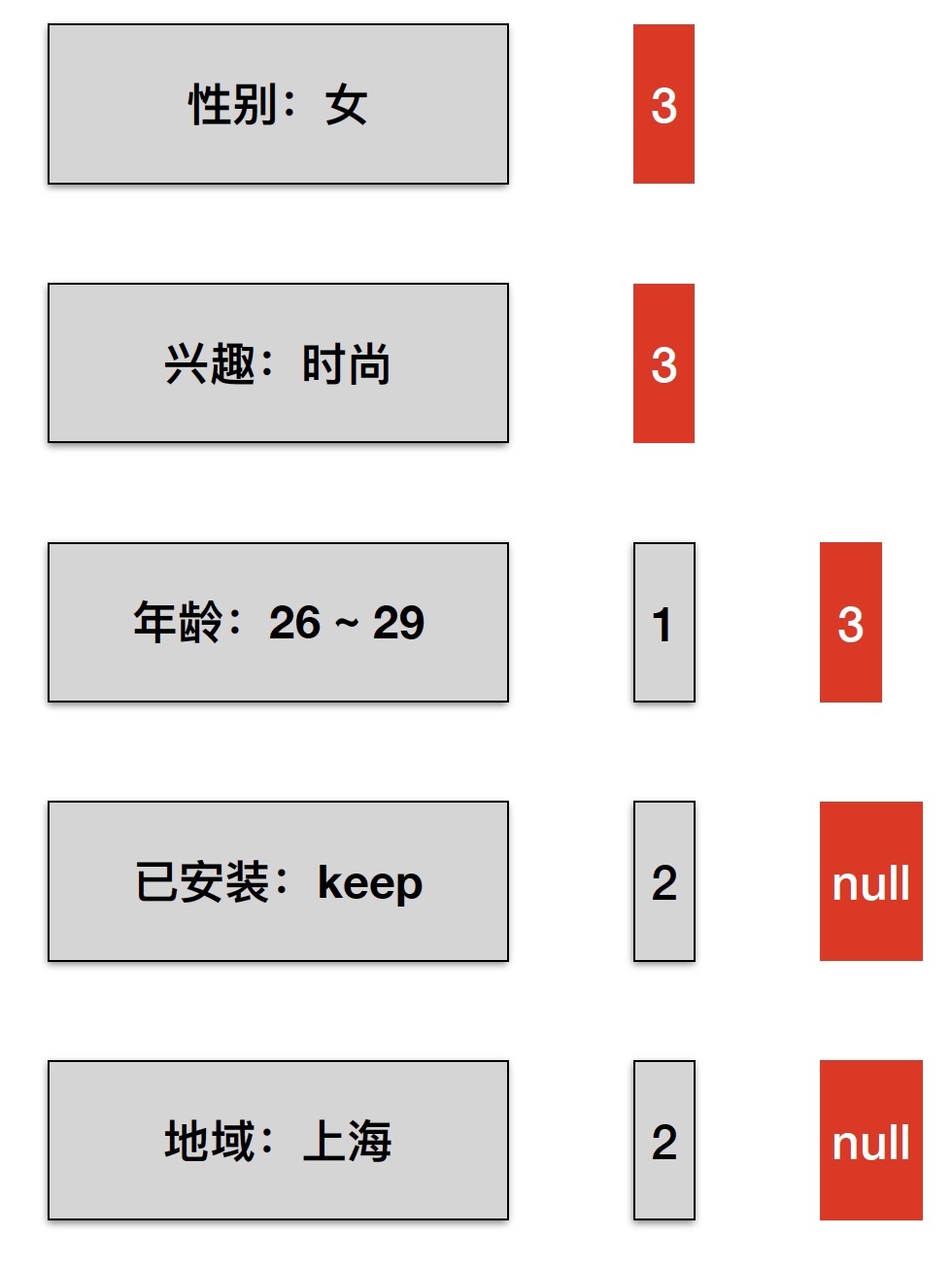
第3个entry出现了3次,条件匹配,可以作为定向结果返回。
如上检索过程,对于 sizeof 为 k 的 Conjunction,需要出现在 k 个Posting list中。
假如有一个广告的定向条件是:
性别 ? { 女 } ∧ 年龄 ∈ { 26-29 } ∧ 兴趣 ∈ { 时尚 }
这个Conjunction的第二层索引结构如下,

这里把它放到 size=2 的部分,前面提到 ? 的 Assignment 不算到 sizeof(Conjunction) 中。
另外,这里用 -4 来表示这个是负定向,在检索的时候,除了满足对于 sizeof 为 k 的 Conjunction,需要出现在 k 个Posting list中,还要满足 conjunction id 不能出现在排除属性对应的 posting list 中。
把 conjunction id = 4 与前面3个广告一起看下索引结构:
O(log(|S|)×|C|×Pavg)
其中:
标签:时间 info region 语句 paper 没有 log bsp tin
原文地址:https://www.cnblogs.com/chenny7/p/14765412.html