标签:inf src lazy href com 价值 强化学习 form 本质
当问题具有下列两个性质时,通常可以考虑使用动态规划来求解:
马尔科夫决策过程具有上述两个属性:贝尔曼方程把问题递归为求解子问题,价值函数相当于存储了一些子问题的解,可以复用。
马尔科夫决策过程需要解决的问题有两种:
动态规划算法的核心是用值函数来构建对最优策略 的搜索,如果最优值函数
和
已知,就能获得最优策略
。其中
和
满足如下方程:
策略评估 (Policy Evaluation) 指计算给定策略下状态价值函数 的过程。
策略评估可以使用同步迭代联合动态规划的算法:从任意一个状态价值函数开始,依据给定的策略,结合贝尔曼期望方程、状态转移概率和奖励,同步迭代更新状态价值函数直至其收敛,得到该策略下最终的状态价值函数。理解该算法的关键在于在一个迭代周期内如何更新每一个状态的价值。
策略迭代一般分成两步:
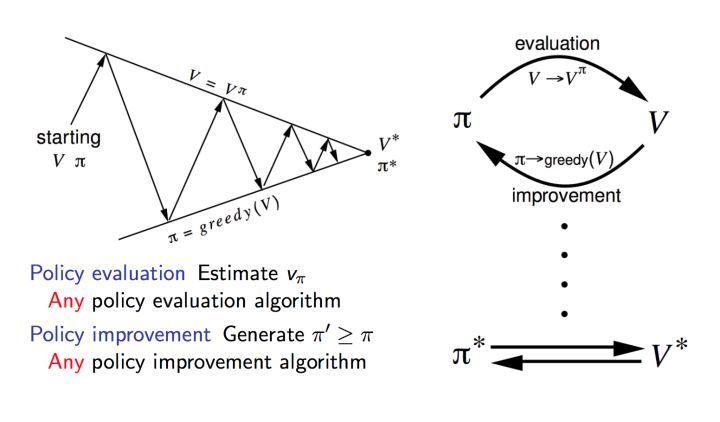 、
、
本质上就是使用当前策略产生新的样本,然后使用新的样本更好的估计策略的价值,然后利用策略的价值更新策略,然后不断反复。由于一个有限的马尔可夫决策过程只有有限个策略,这个过程一定能够在有限的迭代次数后收敛到最优的策略和最优的价值函数。
https://zhuanlan.zhihu.com/p/72360992
标签:inf src lazy href com 价值 强化学习 form 本质
原文地址:https://www.cnblogs.com/Lee-yl/p/14819464.html