标签:stream inpu code 很多 NPU stop 线程安全 时间转换 区别
package cn.edu360
import java.io.{FileInputStream, FileOutputStream, ObjectInputStream, ObjectOutputStream}
/**
* Created by zx on 2017/6/25.
*/
class MapTask extends Serializable{
//以后重哪里了读取数据
//以后该如何执行,根据RDD的转换关系(调用那个方法,传入了什么函数)
def m1(path: String): String = {
path.toString
}
def m2(line: String): Array[String] = {
line.split(" ")
}
}
object SerTask {
def main(args: Array[String]): Unit = {
//new一个实例,然后打印她的hashcode值
//在Driver端创建这个实例
//序列化后发生出去,发生个Executor,Executor接收后,反序列化,用一个实现了Runnable接口一个类包装一下,然后丢到线程池中
val t = new MapTask
println(t)
//输出流,把这个对象写到文件里
val oos = new ObjectOutputStream(new FileOutputStream("./t"))
oos.writeObject(t)
oos.flush()
oos.close()
//读出来
val ois1 = new ObjectInputStream(new FileInputStream("./t"))
val o1 = ois1.readObject()
println(o1)
ois1.close()
//再读出来
val ois2 = new ObjectInputStream(new FileInputStream("./t"))
val o2 = ois2.readObject()
println(o2)
ois2.close()
}
}
把一个对象写到一个文件里,读出来再读出来,是不同的示例,不同的hashCode值
大家在写程序时经常报某个类没有序列化,如果你不知到它的本质,就会经常出现很多问题
下面讲一个SerTest
import java.net.InetAddress
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by zx on 2017/6/25.
*/
object SerTest {
def main(args: Array[String]): Unit = {
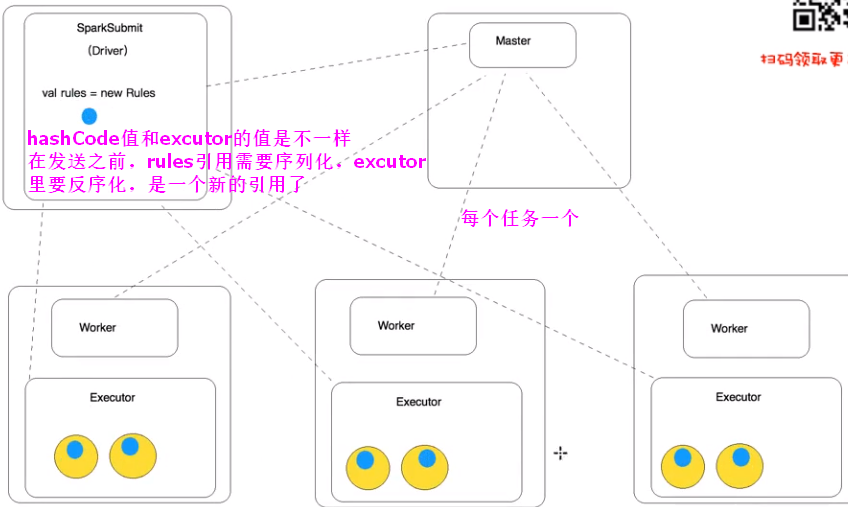
//在Driver端被实例化 方式一,如果在外面直接new,excutor里是拿不到对象引用的,需要实现序列化
//val rules = Rules 实现序列化之后化伴随着Task发送出去,每个Task用一个新的类,如果类再定义成了Object静态类,就可以实现多个Task用同一个类
//println("@@@@@@@@@@@@" + rules.toString + "@@@@@@@@@@@@")
val conf = new SparkConf().setAppName("SerTest")
val sc = new SparkContext(conf)
val lines: RDD[String] = sc.textFile(args(0))
//下面代码在excutor端执行
val r = lines.map(word => {
//val rules = new Rules 如果直接在里面new 示例,在里面使用,每个任务的每个Task都会创建一个实例,浪费空间资源
//函数的执行是在Executor执行的(Task中执行的)
val hostname = InetAddress.getLocalHost.getHostName
val threadName = Thread.currentThread().getName
//Rules.rulesMap在哪一端被初始化的?
//(hostname, threadName, Rules.rulesMap.getOrElse(word, "no found"), Rules.toString)
})
r.saveAsTextFile(args(1))
sc.stop()
}
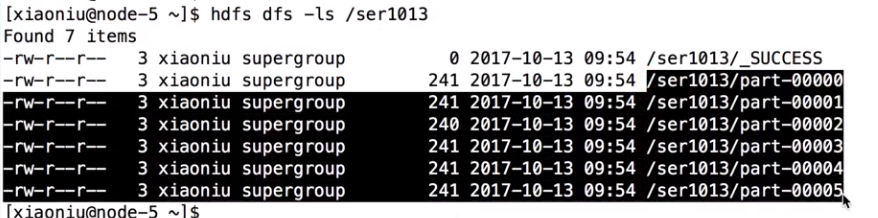
}输入文件有6个,6个分区形成6个Task
直接分区内new数据

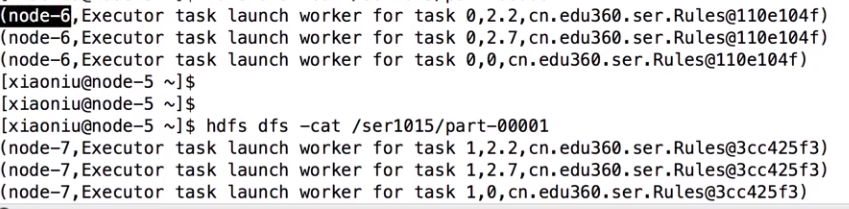
//val rules = Rules 实现序列化之后化伴随着Task发送出去,同一个Task用一同一个类,不同Task用的不用的类,如果类再定义成了Object静态类,就可以实现多个Task用同一个类。和driver端的hashCode值是不一样的,反序化后变成了一个新的类,地址不同
1 只实现序列化
2 实现序列化并静态类
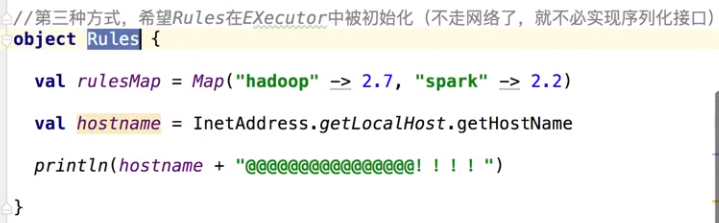

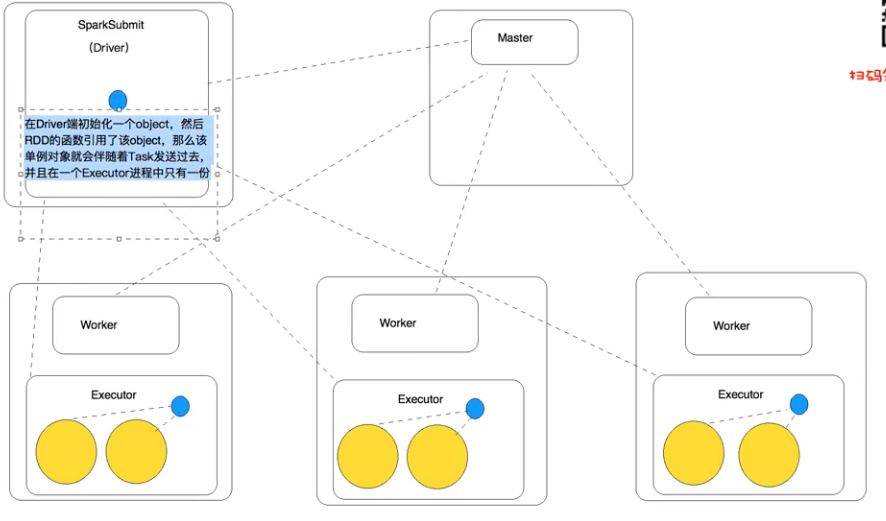
 在excutor端打印
在excutor端打印
和广播变量的区别
广播变量在driver 端收集,然后广播出去,如果我收集过来,依次广播到我的excutor,如果我的excutor比较多,它就广播的特别慢,
现在这个是每个excutor只发送一部分,excutor和excutor之间可以相互的通信传输,以后获取规则的时候更快。
面试:这个广播变量是不是一广播出去,是不是不能更改了?是的。广播的规则一般是不变得规则。
如果我有个需求,每个十分钟重新加载一次,用现在这种方式,写个定时器,10s种把数据读出来,再放进map中,but Task万一同时也要读,就涉及到线程安全中,加锁。
还有一种方式,把规则写入在外部得Redis中,spark经常和redis结合,redis内存读数据,比map更强大。
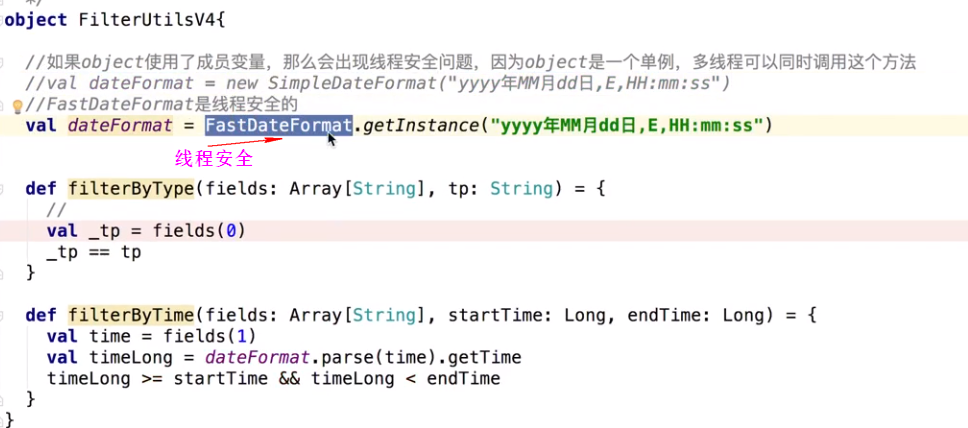
多线程问题
一个excutor里可以多个task同时执行,有可能同时读同一个文件,就出现了多线程安全问题

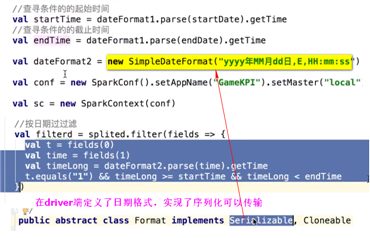
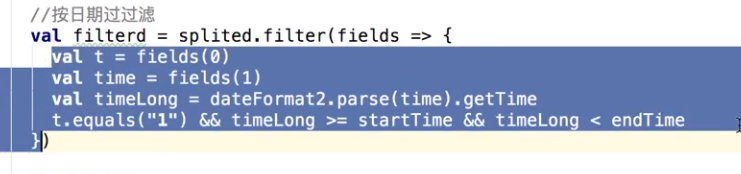
把这个时间转换一下,如何转?

标签:stream inpu code 很多 NPU stop 线程安全 时间转换 区别
原文地址:https://www.cnblogs.com/dali1314/p/14825313.html