标签:性能 使用 调用 决定 tag 理解 实现机制 容器 来源
这一部分基本上都由JML语言给出了程序设计的规格,所以也没啥特别需要交代的。总体上来说,我在编写代码时大致分为这几个步骤:
1.先阅读官方包中所有接口和抽象异常类的定义,关注于整个程序的代码架构并从OO角度理解该类需要实现什么;
2.然后再是较仔细地阅读所有类的JML语言,了解不同类中应有什么对象,应有哪些方法,这些方法实现了什么功能;
4.编写代码时先从“最为基层”的类(如 Person, Message)开始实现,这些类侧重于方法调用时的嵌套;再实现较为复杂的类(如Network),而此部分则开始真正意义上实现方法的功能。在实现过程中,需要关注用何种容器与何种数据结构存储的问题。
虽然本单元课程组推荐我们使用Junit进行测试,本单元的训练题也是学习Junit进行单元测试,但在第一次作业使用Junit后,我觉得此方法并不好用,而且大部分的bug其实都是ctle,来源于算法性能问题,因此在第三次作业中我采用的是对拍测试。
除去性能导致的tle之外,三次作业里我出现了两类bug:第一类是Group没有注意到人数上限为1111,即使满了也给他加进去;而第二类则是群发红包时,没有注意到群发给单人的数量要均分即(money / people.size()),而是直接给每个人都发了money数量的红包。应该说这两个bug都是出于阅读JML不仔细导致的,不存在程序的设计架构问题。因此我认为此单元最合适的测试策略还是仔细阅读JML。
HashMap:最开始我都是使用Arraylist容器来存放,但在第一次作业互测中就因ctle被hack了。通过上网查找HashMap的内部实现机制才发现:HashMap的查找时间复杂度为O(1),而Arraylist的查找为一个for循环,时间复杂度O(n)(我采用的是比较low的遍历查找,其实可以使用二分查找等来优化,降到O(logn),但既然java已经提供了更好的实现机制,何乐而不为呢),因此之后的容器若需要实现使用根据id来查找的功能,就使用HashMap;而不需要按id查找的就直接使用Arraylist容器。
TreeMap:由于我实现isCircle方法使用的是并查集,合并结点时需要比较两个结点对应通路总结点数的大小,因此我使用了能自动排序的TreeMap容器。
PriorityQueue:在求最短路径时我采用的是堆优化的Dijkstra算法,为实现堆优化,我采用了java内部提供的PriorityQueue容器来存取遍历的路径。
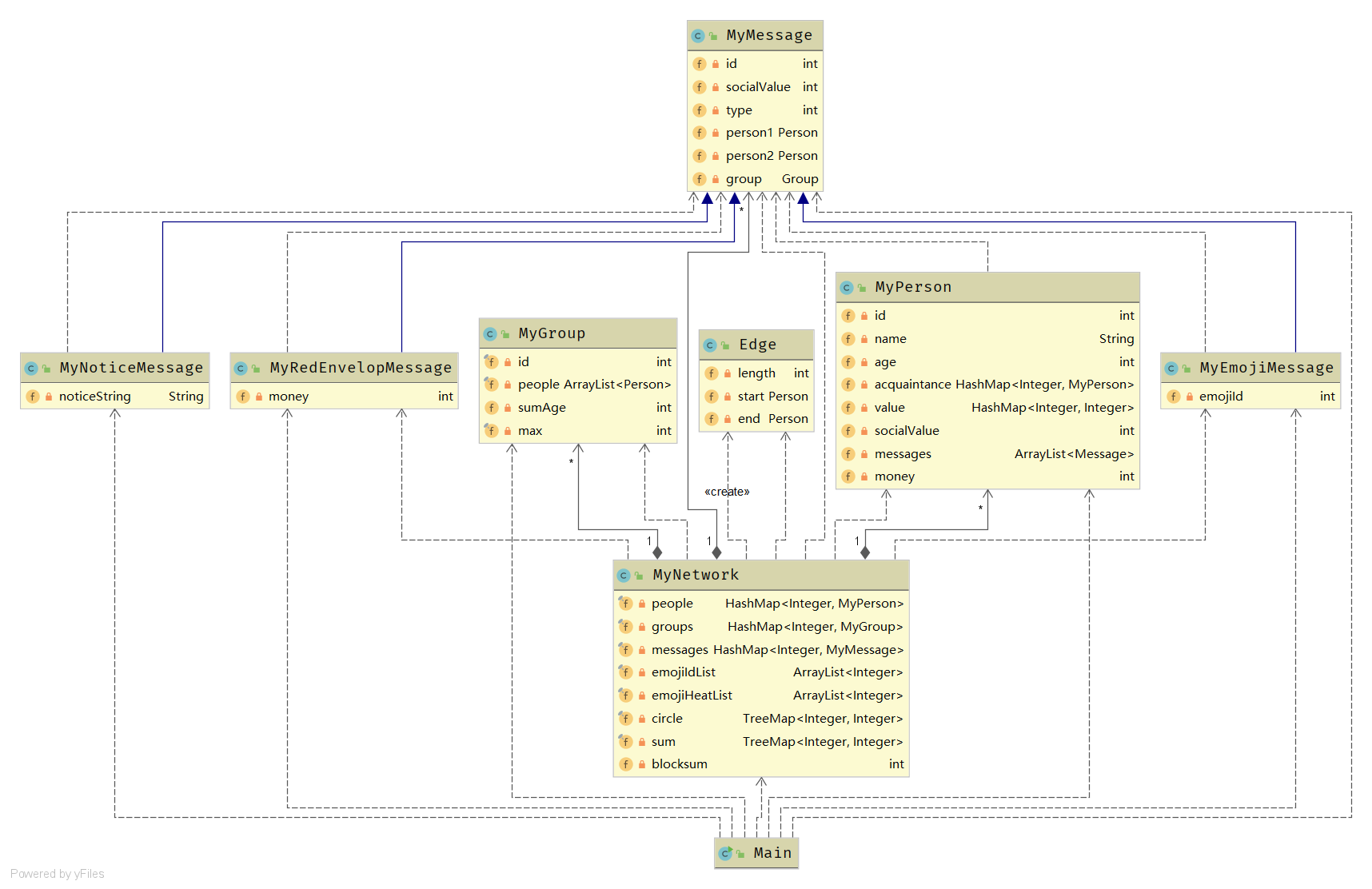
MyPerson
private HashMap<Integer, MyPerson> acquaintance = new HashMap<>(); //存放结识的人 private HashMap<Integer, Integer> value = new HashMap<>(); //存放结识的人对应的value值 private ArrayList<Message> messages = new ArrayList<>(); //存放收到的messages
MyGroup
private final ArrayList<Person> people = new ArrayList<>();
MyNetwork
private final HashMap<Integer, MyPerson> people; private final HashMap<Integer, MyGroup> groups; private final HashMap<Integer, MyMessage> messages; private final ArrayList<Integer> emojiIdList; private final ArrayList<Integer> emojiHeatList; private final TreeMap<Integer, Integer> circle; //用于并查集查找 private final TreeMap<Integer, Integer> sum; //用于并查集查找
本单元出现性能问题都是因为算法的时间复杂度过高,凭经验来说一般时间复杂度在O(n^2)及以上就很可能会出现tle的问题。本单元最可能出现tle的方法有queryBlockSum, sendIndirecetMessage,getValueSum和getAgeVar。
queryBlockSum:最开始是简单暴躁的遍历实现,两个for循环,时间复杂度为O(n^2),所以第一次互测就被人刀傻了。针对第一次被hack的bug,我采用的是采用连通分量来边读入边存储更新结点的连通分量,而queryBlockSum则是在addPerson和addRealtion中直接进行更新计算。但遗憾的是,在第二次作业的强测中又出现了这个bug。在和同学学长交流之后,我决定采用祖传的并查集,最终成功AC了。
public int find(int id) { if (circle.get(id) == id) { return id; } else { circle.put(id, find(circle.get(id))); return find(circle.get(id)); } } ? public boolean isCircle(int id1, int id2) { return find(id1) == find(id2); }
sendIndirectMessage:这个方法中最容易超时的是求最短路径,若直接采用Dijkstra算法,时间复杂度将为O(n^2),由于数据最长可以达到10000行,故直接使用很可能会tle。我采用了堆优化,可以将时间复杂度降低到O(n*logn),极大地提高了性能。而且由于java内部已有优先队列PriorityQueue容器,故堆优化的实现将非常简单。只需要再新增一个Edge类,并实现compareTo方法。
public class Edge implements Comparable<Edge> { private int length; private Person start; private Person end; ? @Override public int compareTo(Edge o) { return Integer.compare(length, o.getLength()); } }
getAgeVar:与前两个不同,这个性能问题没有设计到算法问题,只是单纯的数学知识的优化问题,利用数学知识我们可得到简化的方差公式,只要定义一个sumAge和sumAge2分别用来表示年龄之和与年龄平方数之和,在addPerson和delPerson时注意维护一下即可。
getValueSum:这个方法我最初是两次for循环遍历,时间复杂度为O(n^2),在第三次作业中的强测中出现了一次tle,之后的优化我仅仅是将时间进行折半处理就AC了,但复杂度仍为O(n^2),依然有出现tle的隐患。但对此我也没能想到很好的方法降低其复杂度。
本单元的架构设计已经由官方包给出,因此我们不许考虑太多,只需按照JML规格实现即可。除了官方包给出的类外,在第三次作业实现最短路径时我还新增了Edge类用来表示一条通路。
关于图模型的构建,JML规格大致已为我们实现,Network对应一张图,而Person对应图中的每一个结点,添加一个Person就是添加一个结点,而添加关系就是实现两结点间连线,value则表示这条边的权值。而MyPerson类中的acquaintance用于存放结识的人,在图中其实就是一个邻接表。除此之外,由于使用了并查集算法,故还构建了一个新的图,其结点与Network的结点完全相同。
标签:性能 使用 调用 决定 tag 理解 实现机制 容器 来源
原文地址:https://www.cnblogs.com/buaa19231056/p/14827798.html