标签:平台 类型 cno content 中断处理程序 框架 反馈 根据 遇到的问题
chrome-extension://ikhdkkncnoglghljlkmcimlnlhkeamad/pdf-viewer/web/viewer.html?file=https%3A%2F%2Flink.springer.com%2Fcontent%2Fpdf%2F10.1186%2Fs42400-018-0002-y.pdf
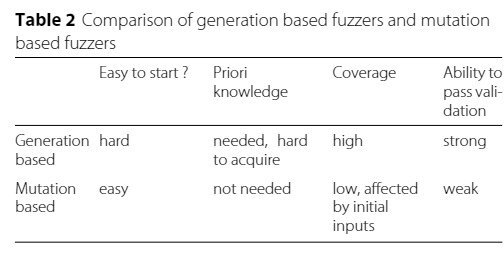
fuzzing分类
(1)基于生成(需要文件格式)
(2)基于变异(不需要文件格式)
fuzzing的挑战:
(1)变异(该在哪里变异)
(2)提高代码覆盖率
代码覆盖率说明
有两种计数法:
(1)基于代码块(节点)
(2)基于代码块跳转(边)
接下来介绍AFL
AFL的代码覆盖计数是基于边的计数法
有两种模式,一种是有源码的模式和没有源码的模式
(1)有源码模式,使用在编译器的技术上实现代码插桩
(2)没有源码的模式,
入手点:
(1)测试用例生成
挑战:
变异的位置
学习输入格式
提高覆盖率
(2)程序执行
挑战:
如何追踪程序
如何为输入文件提供信息
如何提高程序覆盖率
模糊对象:
文件,
内核(1)基于知识的变异(调用内核API)(2)和基于路径(用qemu)
协议
chrome-extension://ikhdkkncnoglghljlkmcimlnlhkeamad/pdf-viewer/web/viewer.html?file=https%3A%2F%2Fwww.usenix.org%2Fsystem%2Ffiles%2Fsec19-zheng_0.pdf
主要讲的是如何对LOT设备的固件进行fuzzing
解决两个问题:
(1)对LOT系统固件进行仿真平台的兼容性问题
(2)仿真平台的效率问题
解决效率问题的方法:
把用户模式仿真和完全系统仿真结合起来
(在用户模式下运行,当需要完全系统仿真时再切换为完全系统仿真)
QEMU技术
是一个基于二进制翻译的程序仿真器
在系统模式中:
主机虚拟地址=客户物理地址+偏移
客户物理地址=客户虚拟地址+偏移
在用户模式中:
主机虚拟地址=客户虚拟地址
所以系统模式中比用户模式的效率低(其中原因之一)
LOT固件测试
直接在硬件测试固件,只把硬件请求定向到硬件,在仿真上测试,发现在仿真上测试的吞吐量(效率)最高(但是效率还是非常的低)
系统模式中比用户模式的效率低原因:
1.地址转换
2.用户模式仿真中的代码翻译过程比全系统模式要快
3.系统调用
主要应用了两种技术:
内存共享映射块来解决用户模式和系统模式的切换
系统调用重定向解决系统调用问题
用户模式和系统模式结合的实现是当遇到分支时通过打开两个子进程:一个运行系统模式的仿真,一个运行用户模式的仿真,并且两个子进程需要相互同步.
其中收集代码覆盖率的信息是在用户模式的仿真中,系统模式的仿真只用于执行系统调用和处理页面故障
总结:该框架针对两个挑战进行了改进,fuzzing的吞吐速度和平台的兼容性做出了改进。
chrome-extension://ikhdkkncnoglghljlkmcimlnlhkeamad/pdf-viewer/web/viewer.html?file=https%3A%2F%2Fnebelwelt.net%2Fpublications%2Ffiles%2F19IOTSP.pdf
设计了一个物联网的fuzzing框架:
(1)和平台无关的特性(利用内存镜像)
(2)静态分析代码,生产测试样例
预处理
&1收集信息,静态审计web端代码,尝试破解密码,找到输入接口(fuzzing点)
&2固件预处理:
(1)虚拟外设,如果固件请求外设,(该框架模拟外设直接返回结果)
(2)动态检测固件(帮助注入,反馈结果)
(3)虚拟网卡
输入生成规则,首先收集漏洞类型,然后根据不同的漏洞进行不同的fuzzing
输入主要时通过web客户端来进行输入
解决了以下问题:
(1)客户端句法上的输入模糊遗传(绘制出各种绕过web客户端的模板)
(2)确定性的bug发现(发现相应类型的bug)(利用固件仿真时产生的日志)
(3)消除模糊带来的副作用(系统崩溃或者无限循环请求)
(4)模糊输入点的确定(通过迭代网页上所有接口元素来形成各种模板,每个模板即输入点)
总结:提出一种针对LOT的fuzzing框架,并且有针对性的对4种类型的漏洞进行对应的变异。
chrome-extension://ikhdkkncnoglghljlkmcimlnlhkeamad/pdf-viewer/web/viewer.html?file=https%3A%2F%2Fwww.ndss-symposium.org%2Fwp-content%2Fuploads%2F2019%2F02%2Fndss2019_04A-1_Song_paper.pdf
核心思想:通过外围设备的输入来对Linux内核进行fuzzing:在驱动和内核之间的数据流通信时添加监视器来监视数据流,并且用于后面的对数据流进行模糊测试
文中设计的框架是一种基于探索外设和内核之间的数据流的框架,只针对两种外设:(1)MMIO(内存映射io)(2)DMA(直接存储器访问,用于外设访问内存的直接接口)
该框架模拟外设对内核进行测试。
背景:
(1)IMMU:管理外设可以访问的物理内存范围
框架分为两部分:
(1)PERISCOPE
通过挂钩内核页面错误处理机制来控制驱动程序对内核的通信
原理:标记监控的目标映像为不在物理块中,以此调用时就会触发缺页中断,缺页后由框架处理,看是否是正常缺页还是框架导致的缺页,如果是后一种,则会传递相应的内存信息,如果后一种,则跳过并且普通执行。
(2)PERIFUZZ
为PERISCOPE的客户端模块,为驱动程序提供和生成输入。并且提出了是在IMMU的基础上进行fuzzing(不进行违规访问)
有以下几个模块:
(1)fuzzer 使用的afl基础
(2)Executor(执行器)是模糊器和注入器的桥梁,用于记录奔溃输入,和提供输入
(3)Injector(注入器)用于连接PERISCOPE的接口
输入和返回保存,防止输入重叠(重复),遇到重复的输入,返回对应的保存的返回值。可以不用大规模的进行执行,而只针对一点进行变异。
使用基于AFL的模糊,使用KCOV来统计代码覆盖率,并且扩展让它支持对中断处理程序的代码覆盖统计,并且让它基于边来进行工作(基于跳转)而不是基于块
当执行器检测到输入被消耗,就会用KCOV记录相关信息。
实现:
【1】在内存中存在一个接口,使用户可以调用所有活动映射,启用或者禁用监视,记录访问情况。
【2】通过随时保存文件来防止崩溃的数据丢失
【3】注入器注册一个设备,用于绑定相应的系统调用,同时映射一个共享内存到外设的输入文件,通过向内存写来注入到内核中,同时使用KCOV来映射文件来计算内存中执行的覆盖率。
总结:这种利用共享内存的形式能够更好的发现ufa漏洞。在发现UFA漏洞方面有显著的优势。同时也是一种针对外设的输入进行fuzzing的通用性框架。
提出了fuzzing算法会遇到的问题:魔术字节和校验和问题。
标签:平台 类型 cno content 中断处理程序 框架 反馈 根据 遇到的问题
原文地址:https://www.cnblogs.com/ring3toring0/p/14814939.html