标签:比较 格式 pat 文件 三分 param 建议 false tle
??redis作为一个高性能内存数据库,在实际业务中应用的非常广泛,虽然redis的性能很好,但是在实际使用过程中,如果使用不当,也会造成一些性能问题,比如数据中存在大key。什么是大key?顾名思义就是单个key中的数据比较大,通常来说,单个key的value值不会很大,这种情况下,key的读取,删除操作不会影响性能,如果value过大,读取或删除会相对耗时,大家都知道,redis是单线程,耗时操作就会阻塞其它请求,给性能上带来一些影响。所以,不管是作为开发还是运维人员,使用redis都应该经常关注数据中有没有大key,今天就说说怎样发现数据中的大key。
1.自带命令redis-cli --bigkeys
该命令是redis自带,但是只能找出五种数据类型里最大的key。很明显,这并不能帮助我们去发现整个数据里的大key,所以一般不使用,执行后如下图: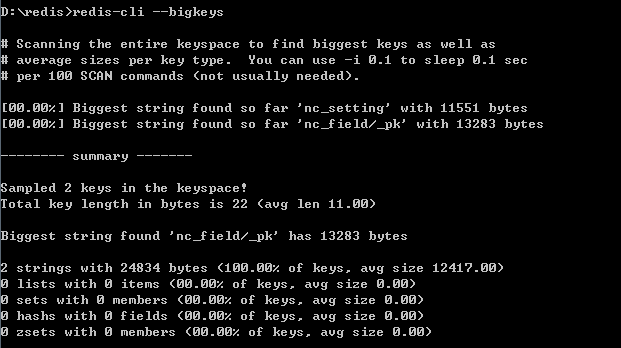
2.python扫描脚本
这是根据脚本去扫描redis中的key,网上一搜就能找到,经实测发现,该脚本获取的大key准确度不高,更确切的说并不是获取的key的大小,而是key值的长度,比如hash类型,获取的是hash中的字段数,string类型,获取的是value的字符串长度,元素个数多并不能代表占用内存多。
find_bigkeys.py文件内容:
import sys
import redis
def check_big_key(r, k):
bigKey = False
length = 0
try:
type = r.type(k)
if type == "string":
length = r.strlen(k)
elif type == "hash":
length = r.hlen(k)
elif type == "list":
length = r.llen(k)
elif type == "set":
length = r.scard(k)
elif type == "zset":
length = r.zcard(k)
except:
return
if length > 102400: #key的长度条件,可更改该值
bigKey = True
if bigKey :
print db,k,type,length
def find_big_key_normal(db_host, db_port, db_password, db_num):
r = redis.StrictRedis(host=db_host, port=db_port, password=db_password, db=db_num)
for k in r.scan_iter(count=1000):
check_big_key(r, k)
def find_big_key_sharding(db_host, db_port, db_password, db_num, nodecount):
r = redis.StrictRedis(host=db_host, port=db_port, password=db_password, db=db_num)
cursor = 0
for node in range(0, nodecount) :
while True:
iscan = r.execute_command("iscan",str(node), str(cursor), "count", "1000")
for k in iscan[1]:
check_big_key(r, k)
cursor = iscan[0]
print cursor, db, node, len(iscan[1])
if cursor == "0":
break;
if __name__ == ‘__main__‘:
if len(sys.argv) != 4:
print ‘Usage: python ‘, sys.argv[0], ‘ host port password ‘
exit(1)
db_host = sys.argv[1]
db_port = sys.argv[2]
db_password = sys.argv[3]
r = redis.StrictRedis(host=db_host, port=int(db_port), password=db_password)
nodecount = 1
keyspace_info = r.info("keyspace")
for db in keyspace_info:
print ‘check ‘, db, ‘ ‘, keyspace_info[db]
if nodecount > 1:
find_big_key_sharding(db_host, db_port, db_password, db.replace("db",""), nodecount)
else:
find_big_key_normal(db_host, db_port, db_password, db.replace("db", ""))
使用方法: python find_bigkey.py IP PORT redis密码,例如: python find_bigkey.py 127.0.0.1 6379 123456,执行后如图: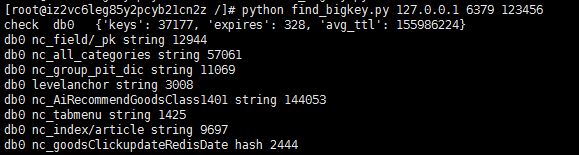
3.rdb_bigkeys工具
这是用go写的一款工具,分析rdb文件,找出文件中的大key,实测发现,不管是执行时间还是准确度都是很高的,一个3G左右的rdb文件,执行完大概两三分钟,直接导出到csv文件,方便查看,个人推荐使用该工具去查找大key。
工具地址: https://github.com/weiyanwei412/rdb_bigkeys
编译方法:
mkdir /home/gocode/
export GOPATH=/home/gocode/
cd GOROOT
git clone https://github.com/weiyanwei412/rdb_bigkeys.git
cd rdb_bigkeys
go get
go build
执行完成生成可执行文件rdb_bigkeys。
使用方法: ./rdb_bigkeys --bytes 1024 --file bigkeys.csv --sep 0 --sorted --threads 4 /home/redis/dump.rdb
/home/redis/dump.rdb修改为实际的文件路径
上述命令分析dump.rdb文件中大于1024bytes的KEY, 由大到小排好序, 以CSV格式把结果输出到bigkeys.csv的文件中,文件格式如图: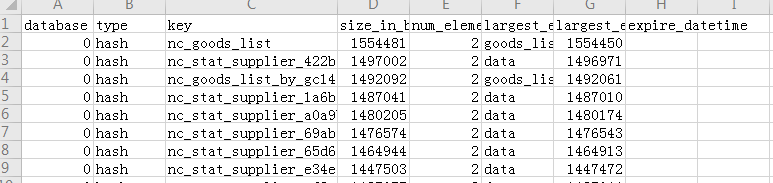
每列分别为数据库编号,key类型,key名,key大小,元素数量,最大值元素名,元素大小,key过期时间。
通过比较发现,第三种方式的数据内容更丰富,更准确,个人建议采用第三种方式。各位如果觉得还有点意义,烦请点一下推荐,加个关注,互相交流。
标签:比较 格式 pat 文件 三分 param 建议 false tle
原文地址:https://www.cnblogs.com/shoshana-kong/p/14832329.html