标签:需求 接口 信息 直接 puts 数据 struct 获取 cpu
首先 Java 中的 IO 都是依赖〈操作系统内核〉进行的,我们程序中的 IO 读写其实调用的是〈操作系统内核〉中的 read&write 两大系统调用。
那内核是如何进行 IO 交互的呢?
对应抽象到 Java 的 Socket 代码简单示例如下:
public class SocketServer {
public static void main(String[] args) throws Exception {
// 监听指定的端口
int port = 8080;
ServerSocket server = new ServerSocket(port);
// server 将一直等待连接的到来
Socket socket = server.accept();
// 建立好连接后,从 socket 中获取输入流,并建立缓冲区进行读取
InputStream inputStream = socket.getInputStream();
byte[] bytes = new byte[1024];
int len;
while ((len = inputStream.read(bytes)) != -1) {
//获取数据进行处理
String message = new String(bytes, 0, len, "UTF-8");
}
// socket、server、流关闭操作,省略不表 ...
}
}
可以看到这个过程和底层内核的网络 IO 很类似,主要体现在 accept() 等待从网络中的请求到来,然后 bytes[] 数组作为缓冲区等待数据填满后进行处理。而 BIO、NIO、AIO 之间的区别就在于这些操作是同步还是异步,阻塞还是非阻塞。
所以我们引出同步异步,阻塞与非阻塞的概念。
同步和异步指的是一个执行流程中每个方法是否必须依赖前一个方法完成后才可以继续执行。假设我们的执行流程中:依次是方法一和方法二。
同步与异步关注的是方法的执行方是主线程还是其他线程,主线程的话需要等待方法执行完成,其他线程的话无需等待立刻返回方法调用,主线程可以直接执行接下来的代码。
同步与异步是从多个线程之间的协调来实现效率差异。
为什么需要异步呢?笔者认为异步的本质就是为了解决主线程的阻塞,所以网上很多讨论把同步异步、阻塞非阻塞进行了四种组合,其中一种就有异步阻塞这一情形,如果异步也是阻塞的?那为什么要特地进行异步操作呢?
阻塞与非阻塞指的是单个线程内遇到同步等待时,是否在原地不做任何操作。
阻塞与非阻塞关注的是线程是否在原地等待。
笔者认为阻塞和非阻塞仅能与同步进行组合。而异步天然就是非阻塞的,而这个非阻塞是对主线程而言(可能有人认为异步方法里面放入阻塞操作的话就是异步阻塞,但是思考一下,正是因为是阻塞操作所以才会将它放入异步方法中,不要阻塞主线程)。
例子讲解:海底捞很好吃,但是经常要排队。我们就以生活中的这个例子进行讲解。
哪种方式更有效率呢?是不是一目了然呢?
BIO 全称是 Blocking IO,是 JDK1.4 之前的传统 IO 模型,本身是〈同步阻塞模式〉。线程发起 IO 请求后,一直阻塞 IO,直到缓冲区数据就绪后,再进入下一步操作。针对网络通信都是一请求一应答的方式,虽然简化了上层的应用开发,但在性能和可靠性方面存在着巨大瓶颈,试想一下如果每个请求都需要新建一个线程来专门处理,那么在高并发的场景下,机器资源很快就会被耗尽。
NIO 也叫 Non-Blocking IO 是〈同步非阻塞的 IO 模型〉。线程发起 IO 请求后,立即返回(非阻塞IO)。同步指的是必须等待 IO 缓冲区内的数据就绪,而非阻塞指的是,用户线程不原地等待 IO 缓冲区,可以先做一些其他操作,但是要定时轮询检查 IO 缓冲区数据是否就绪。
Java 中的 NIO 是 New IO 的意思。其实是 NIO 加上 IO 多路复用技术。普通的 NIO 是线程轮询查看一个 IO 缓冲区是否就绪,而 Java 中的 New IO 指的是线程轮询地去查看一堆 IO 缓冲区中哪些就绪,这是一种“IO 多路复用”的思想。IO 多路复用模型中,将检查 IO 数据是否就绪的任务,交给系统级别的 select/epoll 模型,由系统进行监控,减轻用户线程负担。
NIO 主要有 buffer、channel、selector 三种技术的整合,通过零拷贝的 buffer 取得数据,每一个客户端通过 channel 在 selector(多路复用器)上进行注册。服务端不断轮询 channel 来获取客户端的信息。channel 上有 connect、accept(阻塞)、read(可读)、write(可写)四种状态标识。根据标识来进行后续操作。所以一个服务端可接收无限多的 channel,不需要新开一个线程,大大提升了性能。
AIO 是真正意义上的〈异步非阻塞 IO 模型〉。上述 NIO 实现中,需要用户线程定时轮询,去检查 IO 缓冲区数据是否就绪,占用应用程序线程资源,其实轮询相当于还是阻塞的,并非真正解放当前线程,因为它还是需要去查询哪些 IO 就绪。而真正的理想的异步非阻塞 IO 应该让内核系统完成,用户线程只需要告诉内核,当缓冲区就绪后,通知我或者执行我交给你的回调函数。
AIO 可以做到真正的异步的操作,但实现起来比较复杂,支持纯异步 IO 的操作系统非常少,目前也就 Windows 是 IOCP 技术实现了,而在 Linux 上,底层还是使用的 epoll 实现的。
为了讲多路复用,当然还是要跟风,采用鞭尸的思路,先讲讲传统的网络 IO 的弊端,用拉踩的方式捧起多路复用 IO 的优势。
服务端为了处理客户端的连接和请求的数据,写了如下代码。
listenfd = socket(); // 打开一个网络通信端口
bind(listenfd); // 绑定
listen(listenfd); // 监听
while(1) {
connfd = accept(listenfd); // 阻塞建立连接
int n = read(connfd, buf); // 阻塞读数据
doSomeThing(buf); // 利用读到的数据做些什么
close(connfd); // 关闭连接,循环等待下一个连接
}
这段代码会执行得磕磕绊绊,就像这样。
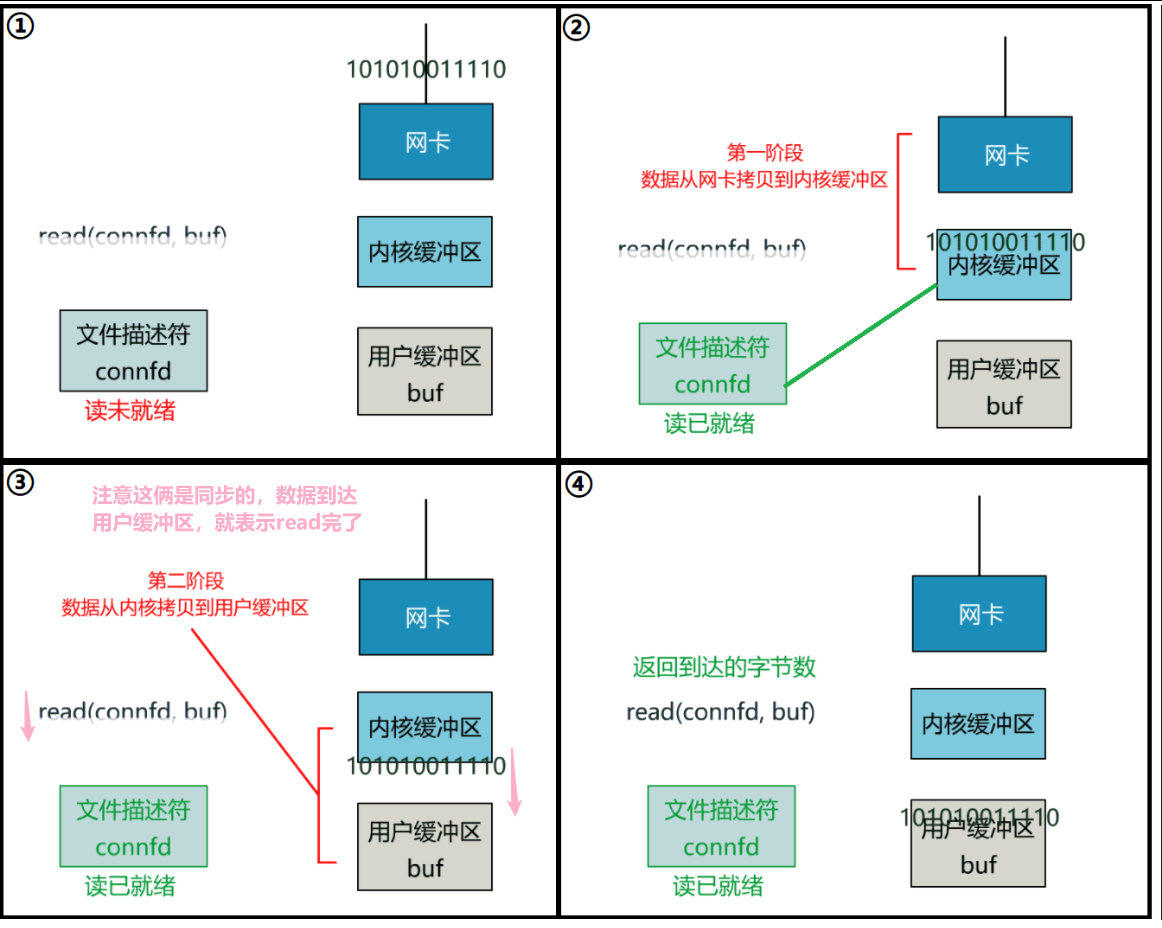
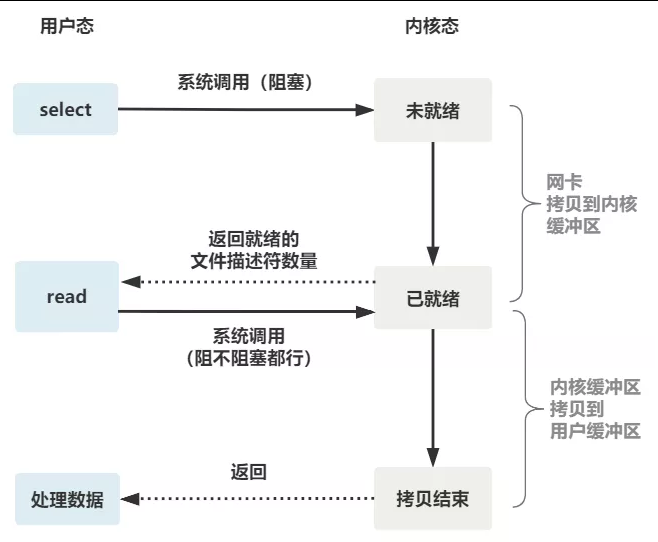
这就是传统的阻塞 IO。整体流程如下图。

所以,如果这个连接的客户端一直不发数据,那么服务端线程将会一直阻塞在 read 函数上不返回,也无法接受其他客户端连接。
这肯定是不行的。
为了解决上面的问题,其关键在于改造这个 read 函数。
有一种聪明的办法是,每次都创建一个新的进程或线程,去调用 read 函数,并做业务处理。
while(1) {
connfd = accept(listenfd); // 阻塞建立连接
pthread_create(doWork); // 创建一个新的线程
}
void doWork() {
int n = read(connfd, buf); // 阻塞读数据
doSomeThing(buf); // 利用读到的数据做些什么
close(connfd); // 关闭连接,循环等待下一个连接
}
这样,当给一个客户端建立好连接后,就可以立刻等待新的客户端连接,而不用阻塞在原客户端的 read 请求上。
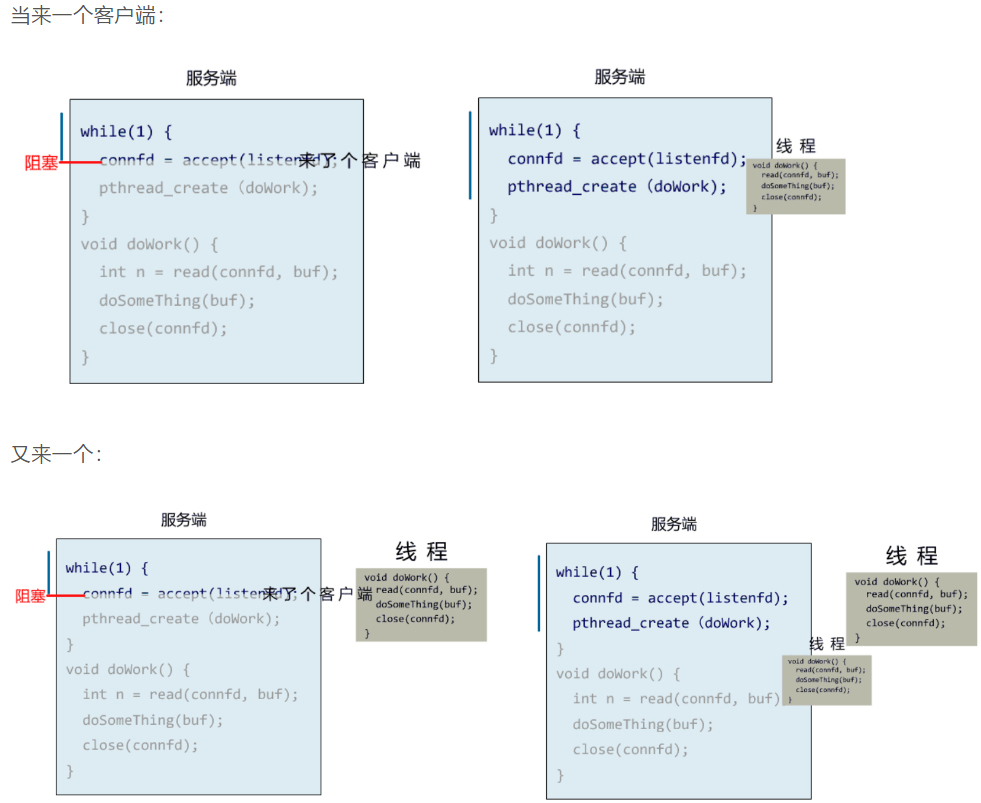
你以为上面就是非阻塞 IO?不是的,这只不过是用了多线程的手段使得主线程没有卡在 read 函数上不往下走罢了。操作系统为我们提供的 read 函数仍然是阻塞的。
所以真正的非阻塞 IO,不能是通过我们用户层的小把戏,而是要恳请操作系统为我们提供一个非阻塞的 read 函数。
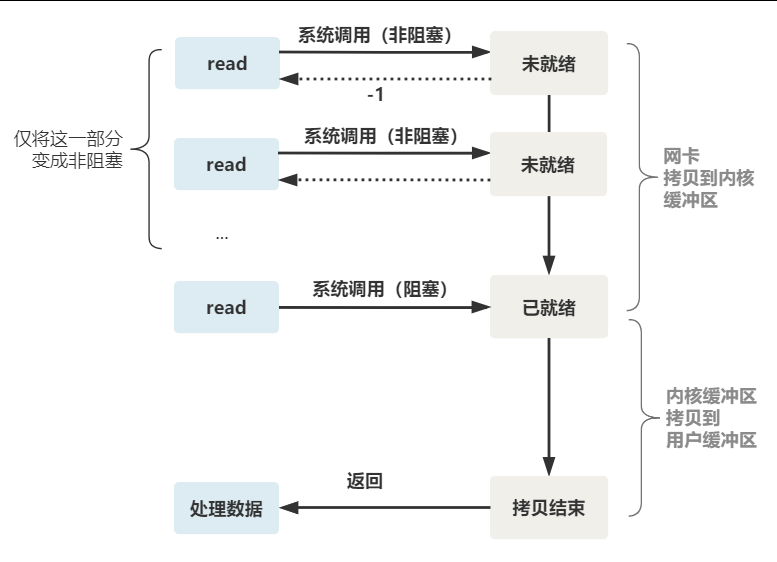
这个 read 函数的效果是,如果没有数据到达时(到达网卡并拷贝到了内核缓冲区),立刻返回一个错误值(-1),而不是阻塞地等待。
操作系统提供了这样的功能,只需要在调用 read 前,将文件描述符设置为非阻塞即可。
fcntl(connfd, F_SETFL, O_NONBLOCK);
int n = read(connfd, buffer) != SUCCESS);
这样,就需要用户线程循环调用 read,直到返回值不为 -1,再开始处理业务。
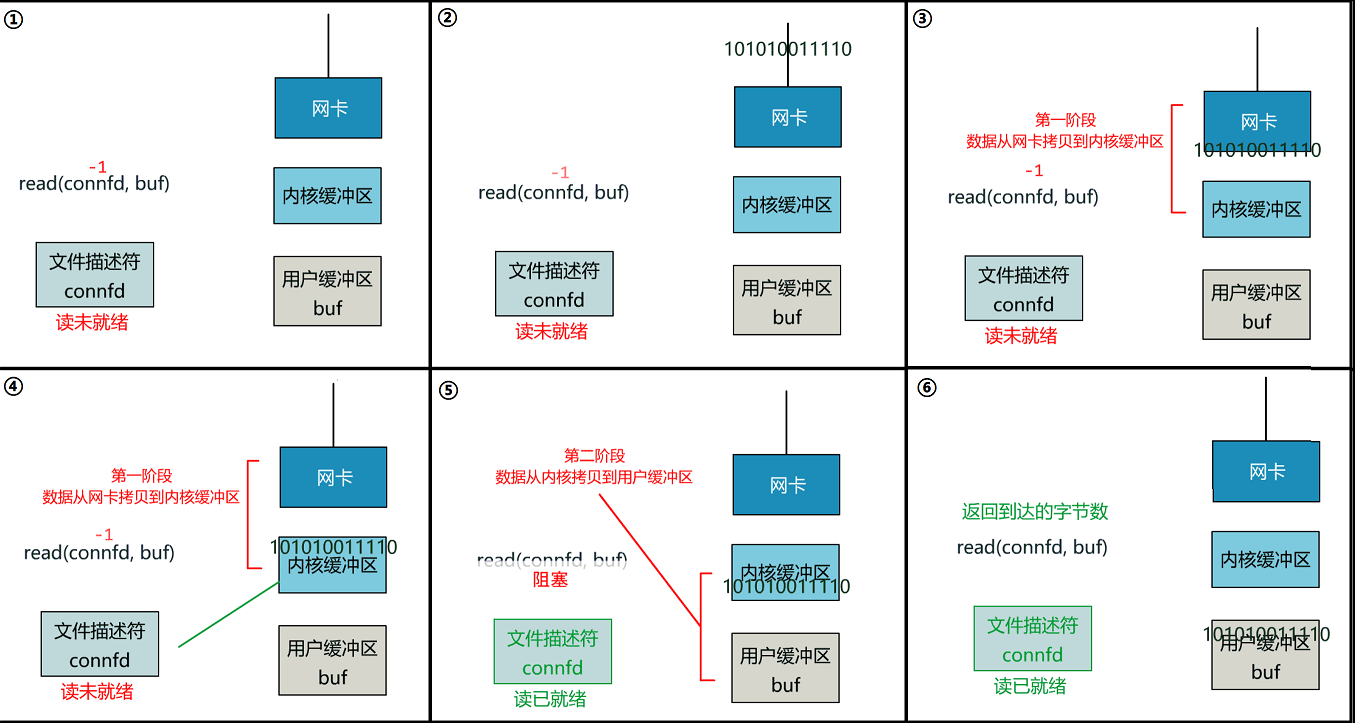
这里注意一个细节!
整体流程如下图:
为每个客户端创建一个线程,服务器端的线程资源很容易被耗光。
当然还有个聪明的办法,我们可以每 accept 一个客户端连接后,将这个文件描述符(connfd)放到一个数组里。
fdlist.add(connfd);
然后弄一个新的线程去不断遍历这个数组,调用每一个元素的非阻塞 read 方法。
while(1) {
for (fd <-- fdlist) {
if (read(fd) != -1) {
doSomeThing();
}
}
}
这样,我们就成功用一个线程处理了多个客户端连接。
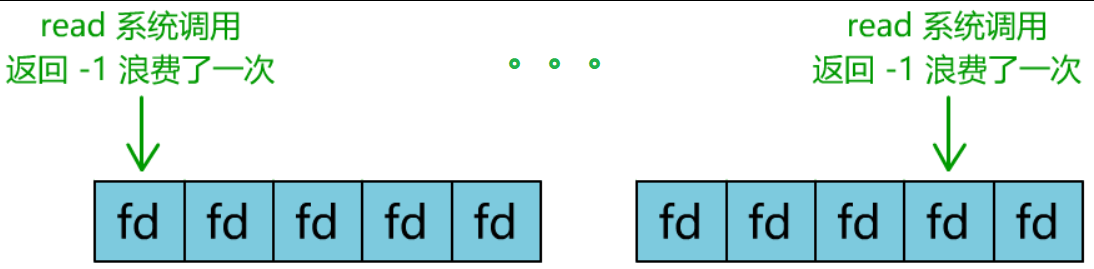
你是不是觉得这有些多路复用的意思?
但这和我们用多线程去将阻塞 IO 改造成看起来是非阻塞 IO 一样,这种遍历方式也只是我们用户自己想出的小把戏,每次遍历遇到 read 返回 -1 时仍然是一次浪费资源的系统调用。
在 while 循环里做系统调用,就好比你做分布式项目时在 while 里做 rpc 请求一样,是不划算的。
所以,还是得恳请操作系统老大,提供给我们一个有这样效果的函数,我们将一批文件描述符通过一次系统调用传给内核,由内核层去遍历,才能真正解决这个问题。
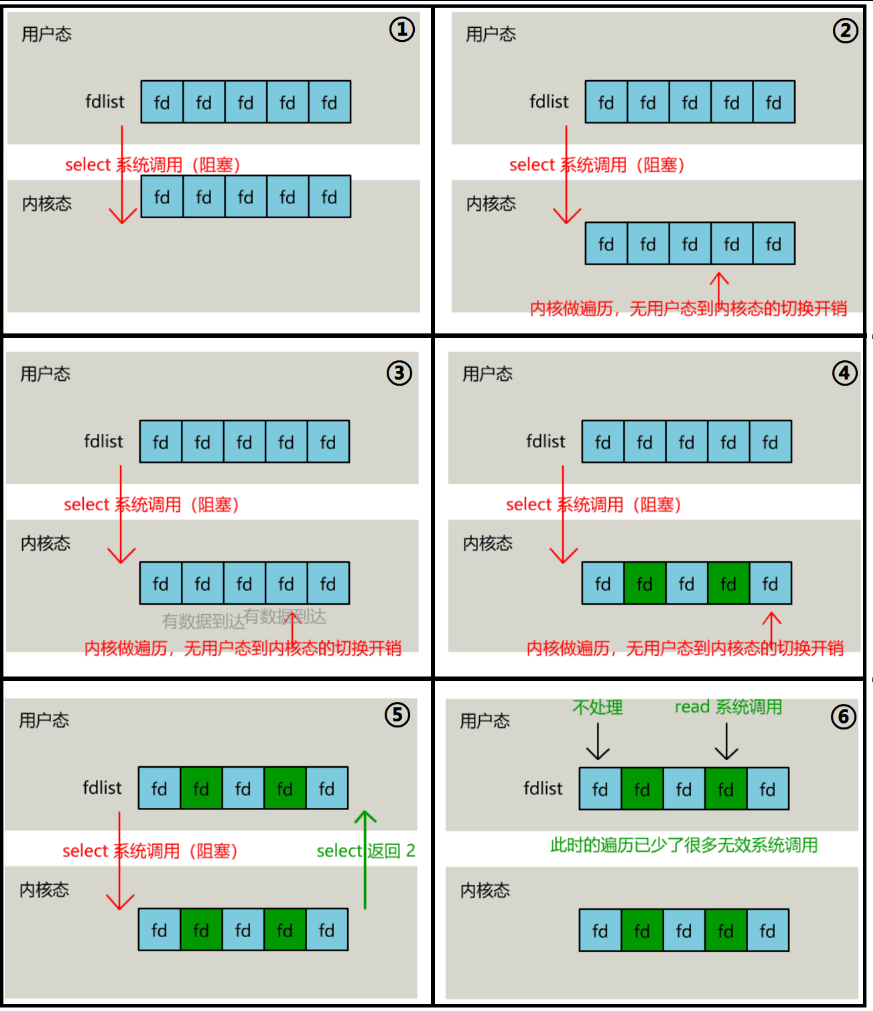
select 是操作系统提供的系统调用函数,通过它,我们可以把一个文件描述符的数组发给操作系统, 让操作系统去遍历,确定哪个文件描述符可以读写, 然后告诉我们去处理:
select 系统调用的函数定义如下。
int select(
int nfds, // nfds 监控的文件描述符集里最大文件描述符+1
fd_set *readfds, // readfds 监控有读数据到达文件描述符集合,传入传出参数
fd_set *writefds, // writefds 监控写数据到达文件描述符集合,传入传出参数
fd_set *exceptfds, // exceptfds 监控异常发生达文件描述符集合,传入传出参数
struct timeval *timeout);
// timeout 定时阻塞监控时间,3 种情况
// 1) NULL,永远等下去
// 2) 设置 timeval,等待固定时间
// 3) 设置 timeval 里时间均为 0,检查描述字后立即返回,轮询
服务端代码,这样来写:
while(1) {
connfd = accept(listenfd);
fcntl(connfd, F_SETFL, O_NONBLOCK);
fdlist.add(connfd);
}
while(1) {
// 把一堆文件描述符 list 传给 select 函数
// 有已就绪的文件描述符就返回,nready 表示有多少个就绪的
nready = select(list);
...
}
while(1) {
nready = select(list);
// 用户层依然要遍历,只不过少了很多无效的系统调用
for(fd <-- fdlist) {
if(fd != -1) {
// 只读已就绪的文件描述符
read(fd, buf);
// 总共只有 nready 个已就绪描述符,不用过多遍历
if(--nready == 0) break;
}
}
}
可以看出几个细节:
整个 select 的流程图如下:
可以看到,这种方式,既做到了一个线程处理多个客户端连接(文件描述符),又减少了系统调用的开销(多个文件描述符只有一次 select 的系统调用 + n 次就绪状态的文件描述符的 read 系统调用)。
poll 也是操作系统提供的系统调用函数。
int poll(struct pollfd *fds, nfds_tnfds, int timeout);
struct pollfd {
intfd; /* 文件描述符 */
shortevents; /* 监控的事件 */
shortrevents; /* 监控事件中满足条件返回的事件 */
};
它和 select 的主要区别就是,去掉了 select 只能监听 1024 个文件描述符的限制。
epoll 是最终的大 boss,它解决了 select 和 poll 的一些问题。
还记得上面说的 select 的 3 个细节么?
所以 epoll 主要就是针对这 3 点进行了改进:
具体,操作系统提供了这 3 个函数。
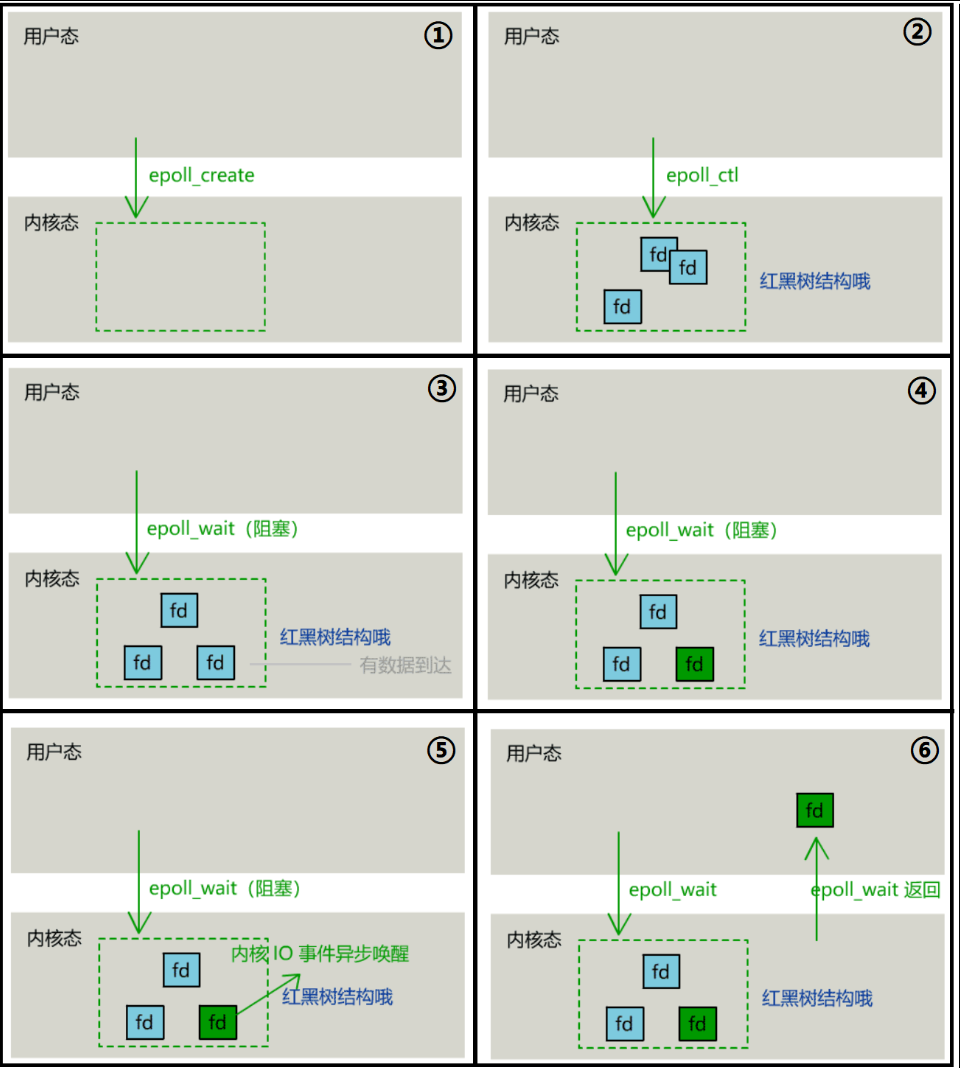
int epoll_create(int size);
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
int epoll_wait(int epfd, struct epoll_event *events, int max events, int timeout);
使用起来,其内部原理就像如下一般丝滑:
一切的开始,都起源于这个 read 函数是操作系统提供的,而且是阻塞的,我们叫它「阻塞 IO」。
为了破这个局,程序员在用户态通过多线程来防止主线程卡死(异步)。
后来操作系统发现这个需求比较大,于是在操作系统层面提供了非阻塞的 read 函数,这样程序员就可以在一个线程内完成多个文件描述符的读取,这就是「非阻塞 IO」。
但多个文件描述符的读取就需要遍历,当高并发场景越来越多时,用户态遍历的文件描述符也越来越多,相当于在 while 循环里进行了越来越多的〈系统调用〉。
后来操作系统又发现这个场景需求量较大,于是又在操作系统层面提供了这样的遍历文件描述符的机制,这就是「IO 多路复用」。
多路复用有 3 个函数,最开始是 select,然后又发明了 poll 解决了 select 文件描述符的限制,然后又发明了 epoll 解决 select 的三个不足。
所以,IO 模型的演进,其实就是时代的变化,倒逼着操作系统将更多的功能加到自己的内核而已。
如果你建立了这样的思维,很容易发现网上的一些错误。比如好多文章说:“多路复用之所以效率高是因为用一个线程就可以监控多个文件描述符”。
这显然是知其然而不知其所以然,多路复用产生的效果,完全可以由用户态去遍历文件描述符并调用其非阻塞的 read 函数实现。而多路复用快的原因在于,操作系统提供了这样的系统调用,使得原来的 while 循环里多次系统调用,变成了〈一次系统调用 + 内核层遍历〉这些文件描述符。
就好比我们平时写业务代码,把原来 while 循环里调 HTTP 接口进行批量,改成了让对方提供一个批量添加的 HTTP 接口,然后我们一次 RPC 请求就完成了批量添加。这是一个道理。
标签:需求 接口 信息 直接 puts 数据 struct 获取 cpu
原文地址:https://www.cnblogs.com/liujiaqi1101/p/14855322.html