标签:image 状态 info net inf 经历 智能 通过 谷歌
因工作需要遇到了DQN和DDPG。在这里详细介绍下这两种强化学习方法。
首先先说DQN。
DQN就是deep q network,谷歌设计的很多智能玩游戏的机器人基于这个算法,用表格存储每个状态的state以及这个state下每个action所拥有的q值实在太多了,需要占用太大的内存并不合理。我们可以通过神经网络来学习并生成q值。
DQN有一个记忆库用来学习之前的经历,q learning是一种离线学习法,它能够学习当前经历的,也能够学习过去经历的,每次DQN更新的时候我们可以随机抽取一些之前的经历进行学习。
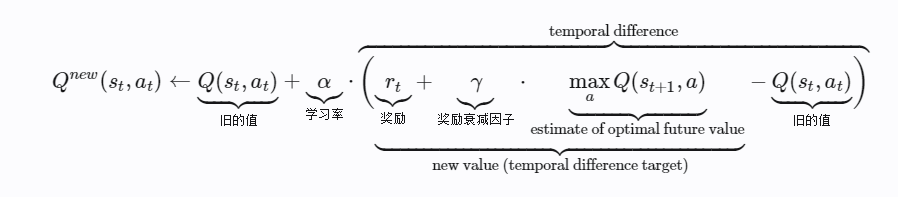
q值里面代表着状态和对应的action。我们通过“价值函数近似”来适用一个函数表示Qsa 而不是通过一个巨大的表格,
未完待续
标签:image 状态 info net inf 经历 智能 通过 谷歌
原文地址:https://www.cnblogs.com/snailbuster/p/14858521.html