标签:专业 2017年 nat photo 一段 除了 deferred 高级 手机应用
Deepfake是指基于深度学习等机器学习方法创建或合成视听觉内容,如图像、音视频、文本等。AI换脸 (face-swap)是指用另一个人脸来替换一张图片或视频中的一个人脸,合成新的媒体物,它是Deepfake(“深度伪造”)技术最广为人知的一种应用形式。Deepfake的制作和检测研究自2017年以来,相关论文数从3篇增加到150篇以上(2018-19年)。本报告以Deepfake技术为主线索,重点阐述AI换脸技术的发展、原理及其应用。
2014.06:提出生成对抗网络(GAN),在图片创建方面取得重大突破,之前的AI算法可以较好的分类图片但创建图片困难;
2017.07:提出一种使用RNN 的LSTM(Long Short-Term Memory)学习口腔形状和声音之间关联性的方法,仅通过音频即可合成对应的口部特征;
2017.10:提出一种基于 GAN 的自动化实时换脸技术;
2017.12:出现deepfake色情视频,名人的面孔被换成色情演员的面孔,由Reddit用户使用自动编码器-解码器配对结构开发(FakeApp前身);
2018.04:出现美国前总统奥巴马的deepfake演讲,将声优的口型(含模仿的配音)替换到奥巴马演讲视频中,使用了FakeApp;
2018.08:提出一种将源视频中的运动转移到另一个视频中目标人的方法,而不仅是换脸(效果imperfect);
2019.03:提出一种控制图片生成器并能编辑造假图片各方面特性的方法,比如肤色、头发颜色和背景内容,不同于之前的假人图片生成方法,这是一种重大突破;
2019.05:提出一种真实头部说话神经模型的少样本对抗学习,基于GAN元学习,该模型基于少量图像(few-shot)训练后,向其输入一张人物头像,可以生成人物头像开口说话的动图;
2019.06:出现“一键式”智能脱衣软件 Deepnude,迫于舆论压力,开发者快速下架。
2020:主要进展在提高原生分辨率、提升deepfake制作效果方面。
DeepFake 的危险性早在 2018 年初就已经被认识到,奥巴马总统的 DeepFake 视频已经制作并发布,并发布了公益公告以引起人们的注意。DeepFake 视频似乎是从那个时候开始制作的,名人和政客发送虚假信息。
虽然它是一种基于 DeepFake 的技术,存在误用的风险,但它非常有用并不断发展。例如,在 2020 年 9 月的日本,EmbodyMe启动了xpression相机必须交付的应用程序调用。有了这个,即使你穿着睡衣醒来,你也可以穿着西装和适当的化妆参加在线会议,或者你甚至可以隐藏你的真面目来表达在线视频。
此外,您还可以通过智能手机应用程序REFACE将您的脸替换为名人视频,从而享受使用乐趣。两者都是高度技术性的,并且在大多数情况下进行非常自然的合成。对于专业用途,它有望用于多种用途,例如模拟化妆、美容和整形手术,以及创建已故女演员的视频场景。
用Deepfakes生成的假脸主要包括以下两大类:
NVIDIA 的 StyleGAN 是人脸合成的先驱吗?可以在1024x1024的足够高的分辨率下生成,已经达到了一眼难以分辨的程度。
并且在 2019 年 12 月,发布了StyleGAN2的改进版本。在之前的版本中,它克服了可能会出现波尔卡圆点等不自然的斑点以及眼睛和牙齿等小部分在与面部方向不同的方向上产生的问题
Style GAN 是基于 Progressive Growing 和 Ada IN 等 GAN 和风格转换的现有技术,通过使用一种叫做 Stochastic Variation 的新技术,可以在没有标签的情况下提取人类的面部特征并根据它们进行恢复. 这是一篇划时代的论文。
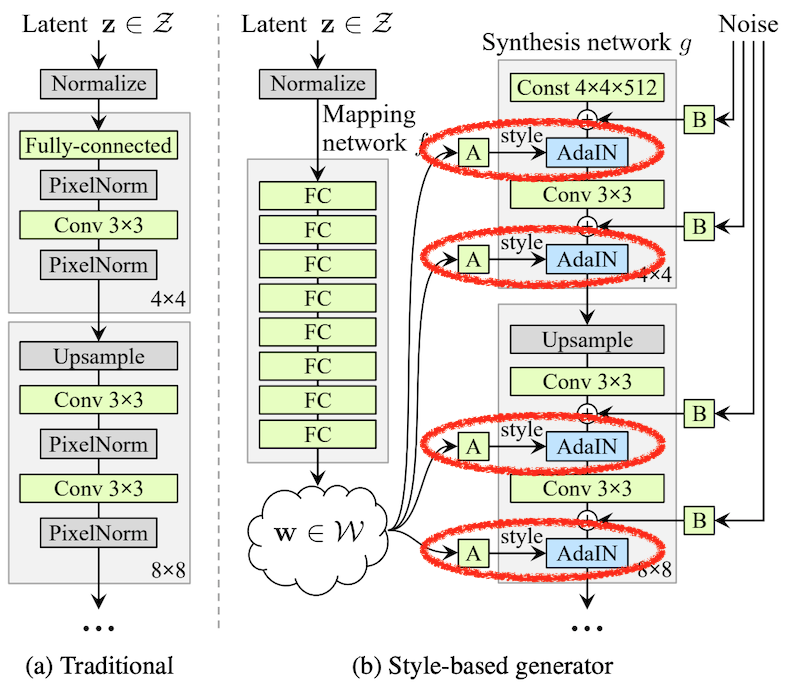
这是第二点。我认为这是这篇论文中最新颖的部分。
人脸图像特征有两种类型:高级(大)特征,如面部朝向和脸的大小;低级(精细)特征,如毛发生长、皮肤皱纹和雀斑,我们分开吧。例如,假设无论低级特征如何变化,如果高级特征不发生变化,则可以将它们识别为同一个人。最大的一点是,可以使用 GAN 无监督地学习仅提取此高级特征,而无需人工标记。
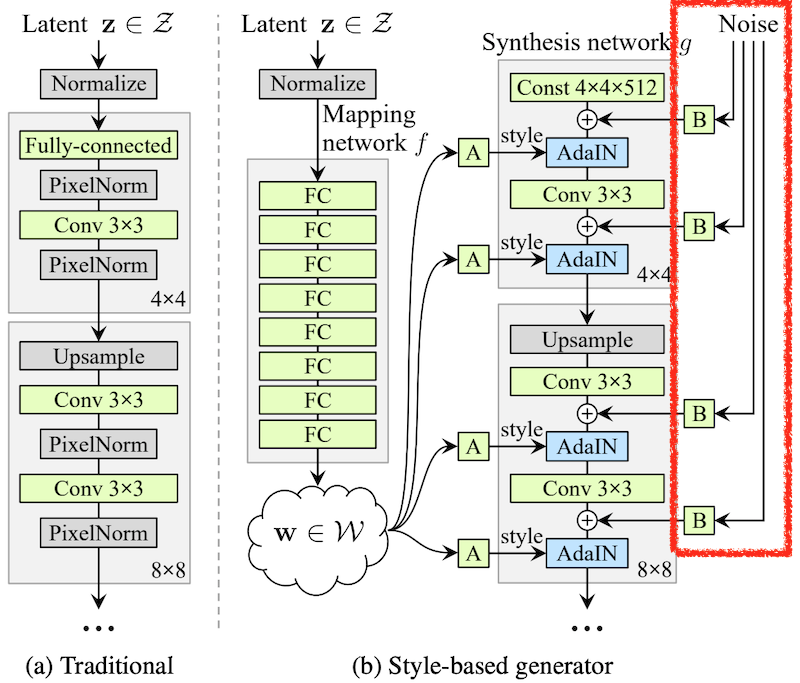
除了潜在向量 z 之外,由于正态分布产生的噪声作为图最右侧的噪声输入到每一层 + 每个像素。这种噪声充当低级特征的输入,并且生成器始终经过训练以创建自然图像,无论每次的值如何变化。这意味着只有高级特征将从潜在向量 z 中生成,并且来自噪声的输入将被优化以负责定位。有趣的!!!
渐进式增长的想法是生成器和鉴别器首先创建和训练一个 4x4 块的最小网络。而当训练结束时,添加 8x8 块并训练,逐渐增加层数和学习。(但是,与微调不同的是,始终可以学习所有层的权重)
看这个官方视频,技术解释很容易理解,但我们也在这里介绍一下。
处理流程:人脸检测、人脸对齐、人脸识别、人脸分割
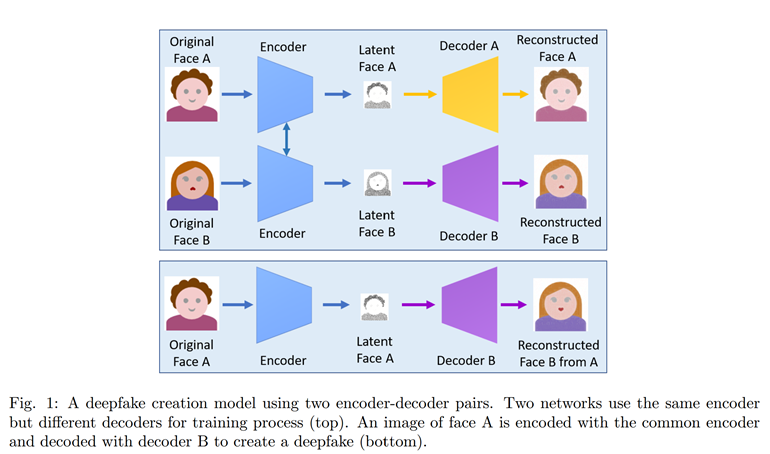
该方法使用两对encoder-decoder,但在训练时两个encoder共享参数,但分别训练decoder。使用时将原始脸A输入Encoder,再连接B的Decoder,解码即可实现将B的脸换为A的脸。
缺点:劳动密集和消耗大量计算资源。该方法只有在拥有大量目标人物图片和视频素材(300到2000张)作为训练数据的前提下才能达到相对理想的效果。
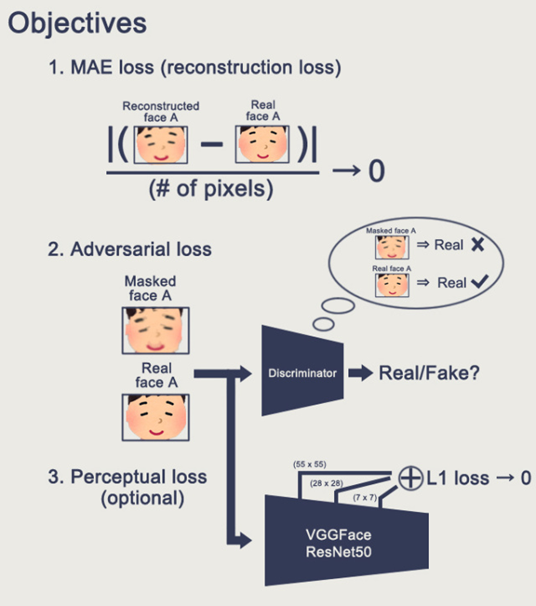
在上一个基于Autoencoder的方法上加入adversarial loss和perceptual loss便可用GAN实现换脸。
该方法通过检测人脸landmarks提取人脸区域,通过这些landmarks用blendshapes可以fit一个3D模板模型,用输入图像的纹理最小化投影形状和定位landmarks的差异,这个模型可以反映射到目标图像上,最后,将渲染模型与图像混合,并进行颜色校正。这个实现在计算上是轻量级的,并且可以在CPU上有效地运行。
受图像风格迁移(artistic style transfer)的影响,该方法将A的人脸姿态和表情作为content,B的身份作为style,生成时保持A的content的同时学习B的style。训练时输入单张content image,首先进行face alignment(人脸对齐)和人脸分割,转换网络是一个带不同分支操作的图像金字塔结构,每个分支里进行zero-padded的 convolution。Loss function 是在pre-trained VGG19网络中的特征空间定义的,主要包含content loss,style loss和light loss,并且定义了Total variation regularization来保证空间平滑。训练时,使用200,000张content image,120张style image,计算VGG-19中间层的activations的欧氏距离计算loss,可实现几乎实时的换脸。
该方法基于一个全卷积神经网络(FCN)人脸分割算法来实现换脸。为此,作者利用2D人脸landmarks来fit一个3D shape,然后经过一个pre-trained FCN从背景和遮挡分割人脸,并且cover到对应的3D face上,最后blending到target上实现换脸。并使用了LFW 数据集来测试,并测试了Inter-subject 和Intra-subject的换脸对识别的影响。
该方法基于一个全卷积神经网络(FCN)人脸分割算法来实现换脸。为此,作者利用2D人脸landmarks来fit一个3D shape,然后经过一个pre-trained FCN从背景和遮挡分割人脸,并且cover到对应的3D face上,最后blending到target上实现换脸。并使用了LFW 数据集来测试,并测试了Inter-subject 和Intra-subject的换脸对识别的影响。
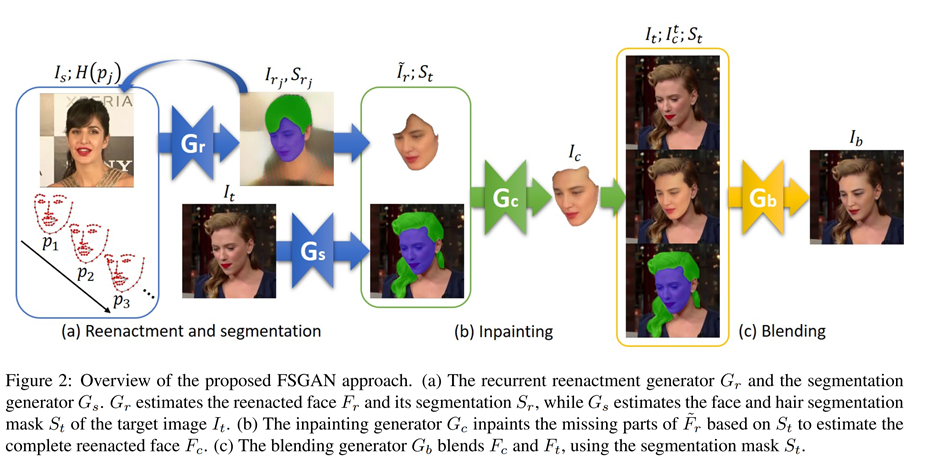
FSGAN同样出自上一个实验室,与之前的工作不同,FSGAN是subject agnostic(不可知的),可以应用于成对的脸,而不需要对这些面孔进行训练。该网络采用了一种新的Poisson blending loss (泊松混合损耗),将Poisson optimization (泊松优化)与perceptual loss相结合。最后,作者进行了定性和定量的比较,结果表明FSGAN的方法在质量和数量上都比他们上一篇论文好。
DeepFaceLab is a tool that utilizes machine learning to replace faces in videos. Includes prebuilt ready to work standalone Windows 7,8,10 binary.
Face2Face实现了实时面部重建,它的目标是通过a source actor使目标视频的面部表情动起来,并以逼真的方式重新渲染处理后的输出视频。它借助 dlib 和 OpenCV,首先人脸检测器检测出源图片中的人脸、找到人脸上的关键标记点,然后fit两个3D模型,再使用针对人脸的pix2pix转换模型把关键标记点转换为目标人脸图像。也许是因为这个方法没有给深度学习留下足够的发挥空间,所以它的效果也一般般,但是后面很多论文都拿它来做对比实验。
出自推出Face2Face的同一个实验室。给定目标演员的短RGB-D视频,可以自动构建一个个性化的几何agent,该agent嵌入参数化的头部,眼睛和运动学躯干模型,使用密集的面部跟踪器和model-to-frame 迭代最近点(ICP)方法对源参与者进行实时跟踪,然后渲染成实时视频.

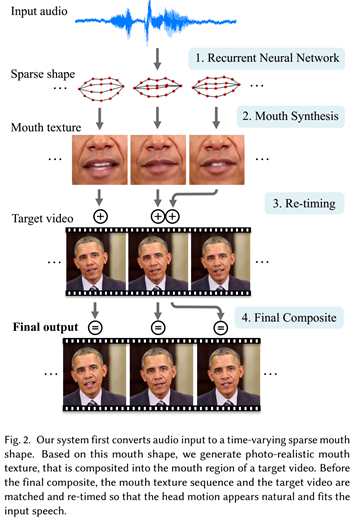
论文主要是学习一个从音频到视频的序列映射,为了简化问题,论文只关注合成嘴周围区域的内容,其他眼睛、头部、上半身、背景等都完全保留。给定一段音频序列,作者首先提取特征作为RNN的输入,RNN输出一个稀疏的嘴型对应于每一帧输出的视频,对于每一个稀疏的嘴型,合成嘴和人脸下部的纹理,再将它们blend到原视频中作为输出。
StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation (CVPR2018)

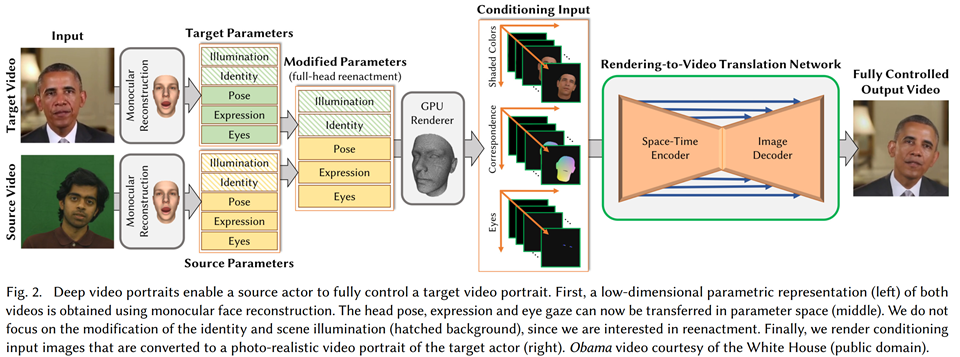
提出了一种新的方法来合成目标在一般静态背景下的全真实感视频portraits。首先,通过单目人脸重建得到了两个视频的低维参数表示。头部姿势,表情和眼睛注视现在可以转移到参数空间(中间)。在此不关注身份和场景照明(阴影背景)的修改,因为我们只对重现感兴趣。最后,对输入图像渲染条件输入图像,将其转换为目标演员的真实感视频肖像(右)。
特点:学习新的头部模型仅需要少量训练素材(8帧图像甚的至至单帧图像)和少量训练时间。该系统不需要大量的训练示例,而且系统只需要看一次图片就可以运行。
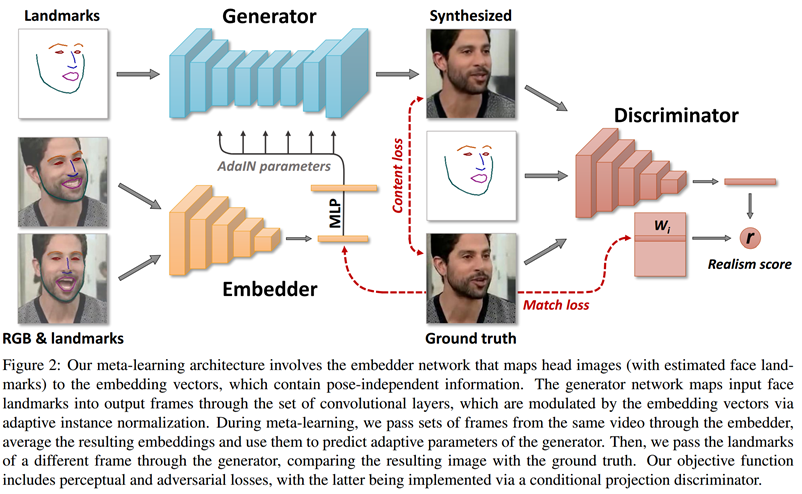
获得一个输入源图像,模拟目标输出视频中某个人的运动,从而将初始图像转换为人物正在说话的短视频。采用 “元学习” 架构,首先,嵌入式网络映射输入图像中的眼睛、鼻子、嘴巴大小等信息,并将其转换为向量;其次,生成式网络通过绘制人像的face landmarks来复制人在视频中的面部表情;第三,鉴别器网络将来自输入图像的嵌入向量粘贴到目标视频的 landmark 上,使输入图像能够模拟视频中的运动。最后,计算 “真实性得分”。该分数用于检查源图像与目标视频中的姿态的匹配程度。
给定一个输入视频和一个文本,作者进行基于文本的面部编辑。首先将音素与输入音频对齐,并跟踪每个输入帧来构建参数化的头部模型。然后,对于给定的文本编辑操作(比如将spider更改为fox),作者找到输入视频中与新单词具有相似发音嘴型的片段。在上面的例子中,作者使用viper和ox来构建fox。作者使用来自相应视频帧的混合头部参数,以及一个重新计时的背景序列,来生成一个复合图像,该图像被用来生成一个使用人脸绘制方法的逼真的框架。在最终的视频中,这位女演员似乎在说fox,尽管在最初的录音中她从未说过这个词。
Deferred Neural Rendering: Image Synthesis using Neural Textures
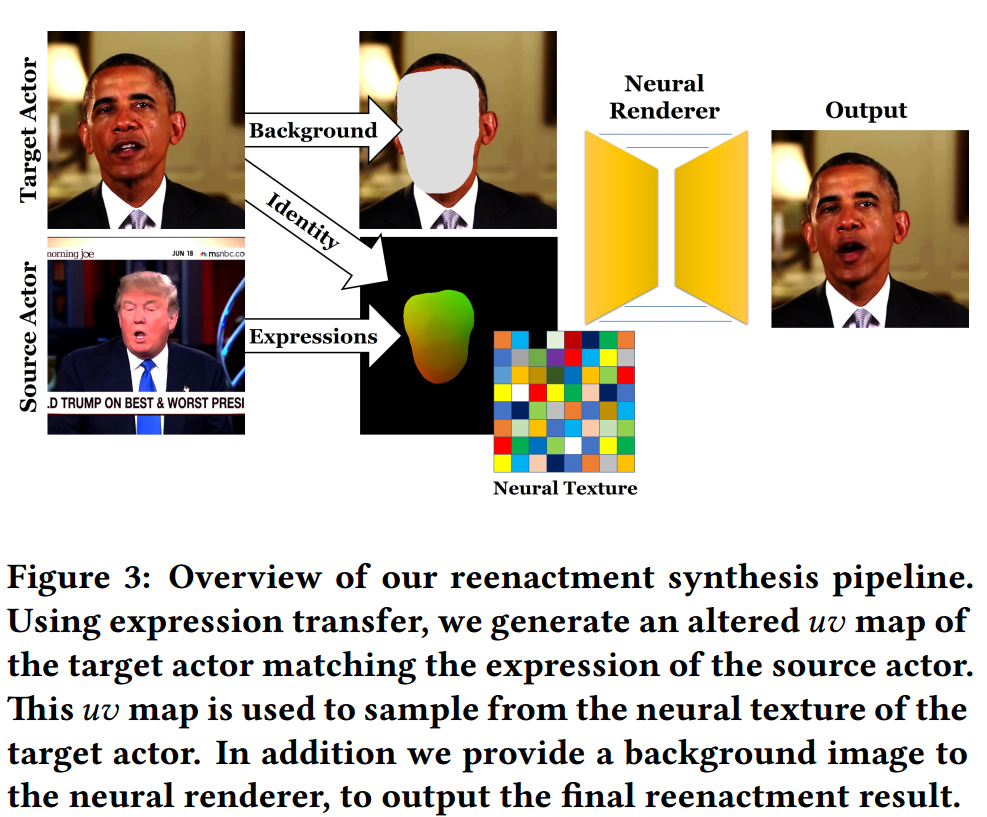
Image-to-image translation is a class of vision and graphics problems where the goal is to learn the mapping between an input image and an output image using a training set of aligned image pair
have achieved impressive results in image generation, image editing, and representation learning
idea: adversarial loss that forces the generated images to be, in principle, indistinguishable from real photos
我们来解释一下CycleGAN,它是一种应用在StarGAN机制中的域转换技术。 CycleGAN 是一项成为热门话题的技术,因为它可以将马和斑马、莫奈风格的山水画和真人图像相互转换。
Cycle-consistency loss
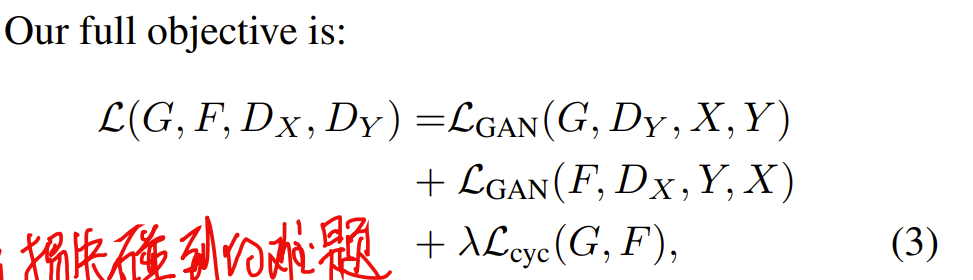
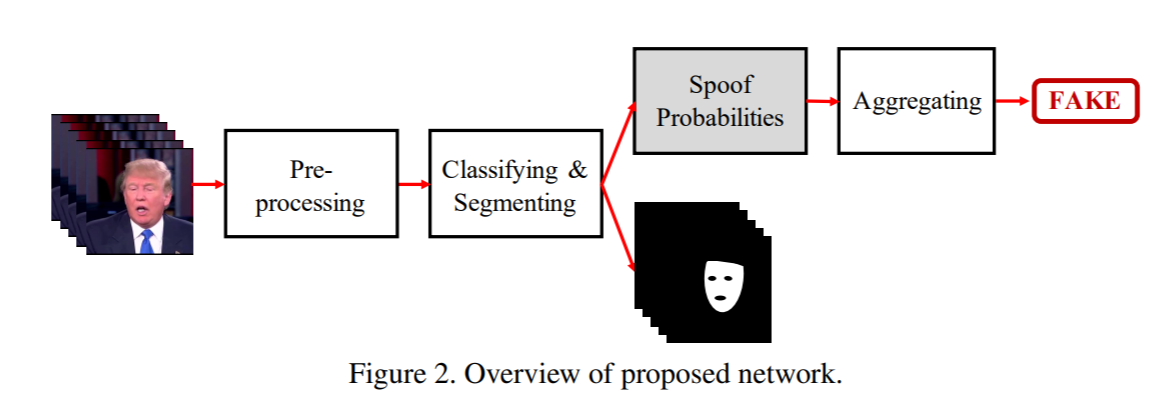
Deepfakes检测方法根据文章可分为假图像检测和假视频检测,这是因为大多数的图像检测算法不能直接用于视频检测,因为视频压缩带来的强烈degradation。而且,视频具有随着不同帧变化的时间特性,因此很难被静态的图片检测到。针对我的研究方向,仅讨论假图像检测。
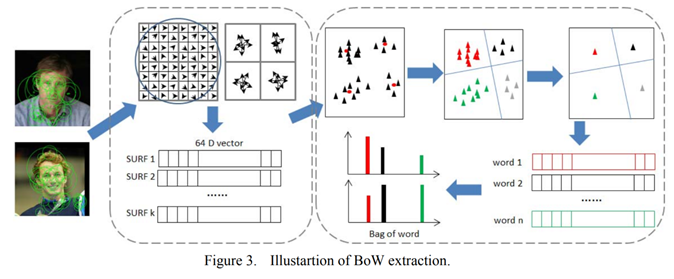
17年的这篇文章是第一篇利用经典机器学习方法解决换脸图片检测问题的论文。作者用栅格划分或者SURF提取关键点描述子,用K-means方法生成bag of words特征,得到codebook直方图,再通过SVM、随机森林(RF)、MLP等分类器进行2分类。在自己建立的基于LFW的假脸数据集中最好的实验结果达到了92%的准确率。
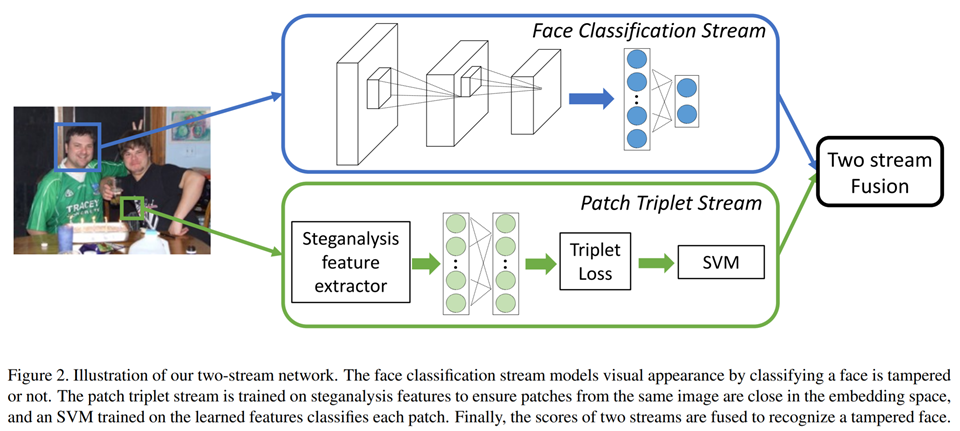
为了避免专注于特定的篡改取证,实现鲁棒的篡改检测,作者提出了一种双流网络结构来捕获篡改伪迹证据和局部噪声残差证据,其中一个stream是一个基于CNN的人脸分类stream,另一个是基于隐藏特征的triplet stream 。第一个基于GoogleNet的人脸分类stream,通过真实的和篡改的图像训练作为一个二分类器,第二个基于patch level隐藏特征的patch triplet stream可以捕捉到像CFA模式和局部噪声残差这样的low-level的相机特征。作者没有直接利用隐写分析特征,而是在提取隐写分析特征后训练一个triplet 网络,使模型能够refine隐写分析特征。将这两种stream结合起来,既可以发现high-level的篡改伪迹的证据,又可以发现low-level的噪声残差特征,为人脸篡改检测提供了很好的性能。作者最后通过两个换脸App自己创建新的数据集来训练和测试。
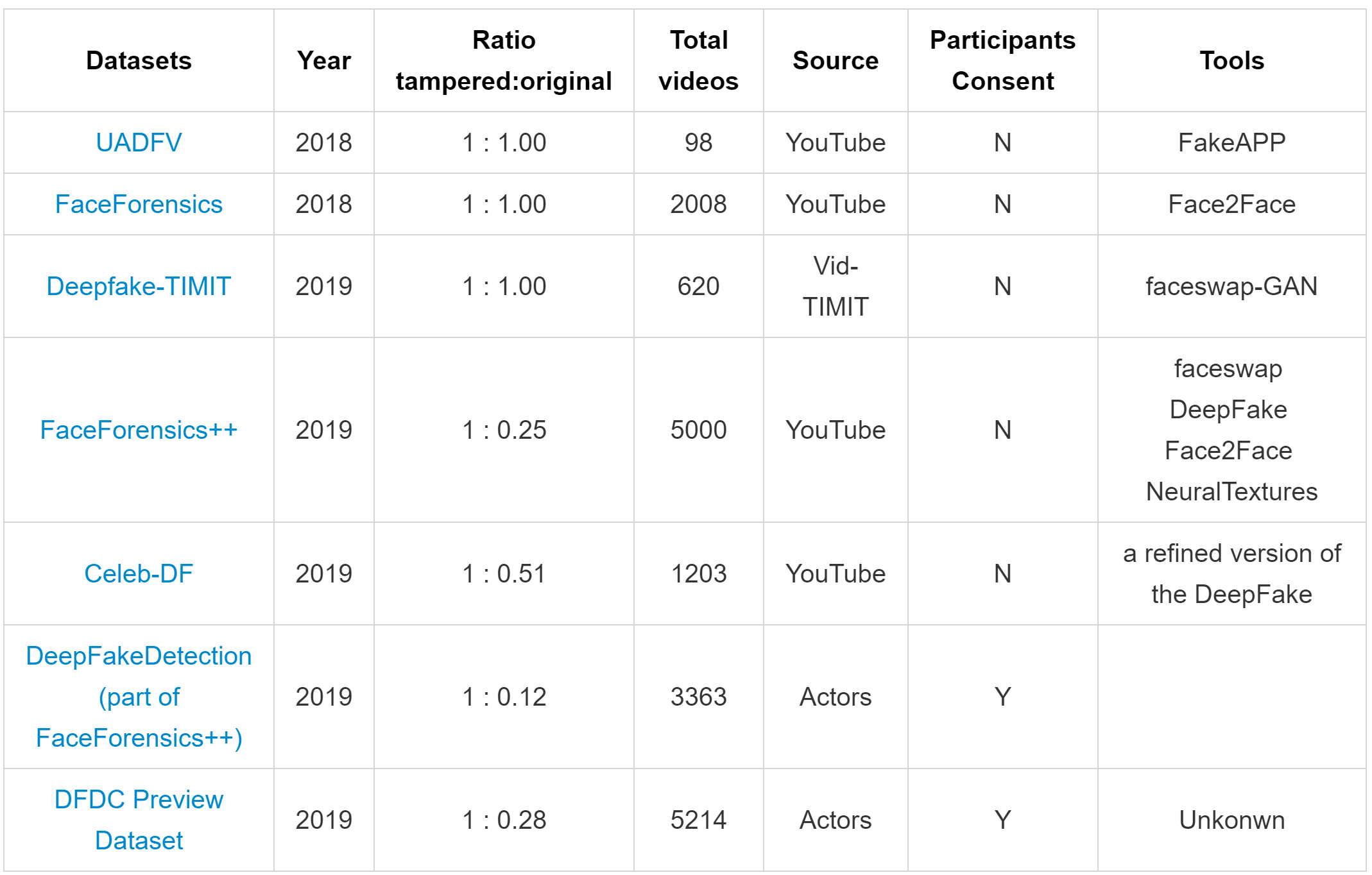
A literature review of deepfakes
A literature review of deepfakes detection
标签:专业 2017年 nat photo 一段 除了 deferred 高级 手机应用
原文地址:https://www.cnblogs.com/icodeworld/p/14849438.html