标签:sea 删除 知乎 数据 网络模型 之间 我不知道 lap 利用
基于序列到序列(seq2seq)的神经网络模型在开放领域对话生成的任务上经常会出现低丰富度(low-diversity)的问题,即生成的回复无趣且简单。因此,作者提出利用非对话的文本语料去提高对话模型的多样性。相比于传统的对话语料,非对话的文本语料不仅容易获得而且主题包罗万象,因此作者从论坛、书籍和谚语中搜集了大量的非对话语料,结合迭代的回译(back translation)方法将非对话语料融入到对话模型的语义空间内。在豆瓣和微博的数据集上,新模型在保持相关度的同时极大提高了生成回复的多样性。
seq2seq 模型已经在很多语言生成任务上取得了很好地效果。然而,当把它应用到通用领域的闲聊生成上时,一个很大的问题就是它倾向于生成像“我不知道”、“好的”这样的通用回复。原因就在于在日常生活中,这些通用回复大量存在于我们的对话里面。Seq2seq模型会很容易得学习到用通用回复就可以处理大部分对话场景。
目前降低seq2seq模型生成通用回复的方法主要有两点:(1)改变seq2seq的目标函数本身来让非通用回复获得更高权重。但是模型依然在有限的对话语料上训练,限制了包含广泛主题的能力。(2)用结构化信息、情感、个性等来增强训练语料。但是,这需要昂贵的人工标注,很难应用到大规模的语料。
在这篇文章里,作者提出利用非聊天语料来丰富通用的闲聊模型。与双边成对的聊天语料相比,非聊天语料往往更容易获得,同时也更多样、涵盖不同主题、不需要进一步人工标注。作者从各种数据源收集了超过一百万条非聊天语料,包括论坛评论、谚语俗语、书籍片段等等。基于此作者提出了基于迭代的回译( iterative back translation)的训练方法来利用这些非聊天语料,实验结果显示模型可以生成更多样而且不失一致性的回复。
收集的非聊天语料每个句子长度不宜过长或者过短,可以跟日常聊天主题和风格贴近。作者考虑从以下三个来源收集:
进一步对收集的语料做过滤处理,删除了含有攻击性和歧视性语言的句子。最后语料总数超过一百万,其中有78万论坛评论、5万谚语俗语和20万书籍片段。
作者用{x,y}来表示聊天语料D中的上文和回复{context, response}对。t代表非聊天语料DT中的句子。作者首先考虑几个baseline系统:
除此以外,作者提出利用iterative back translation来利用非聊天语料。Iteractive back translation在机器翻译上已经获得了广泛的使用,但是还没有被用到聊天系统中。模型首先有一个初始化阶段。初始化完成之后会不断重复反向(backward)和前向(forward)阶段。
在初始化阶段,作者在聊天预料D上同时训练一个forward模型pf(y|x)和backward模型pb(x|y),训练目标如下:
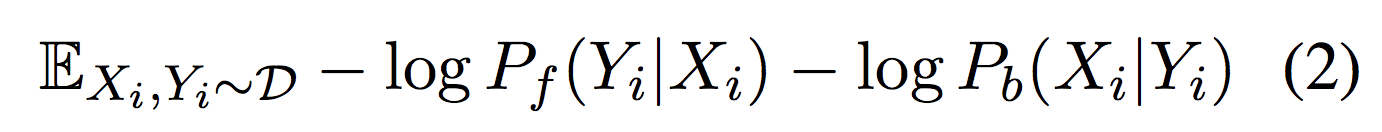
在backward阶段,作者用backward模型创建伪对(pseudo pair)来训练forward模型。目标函数为:
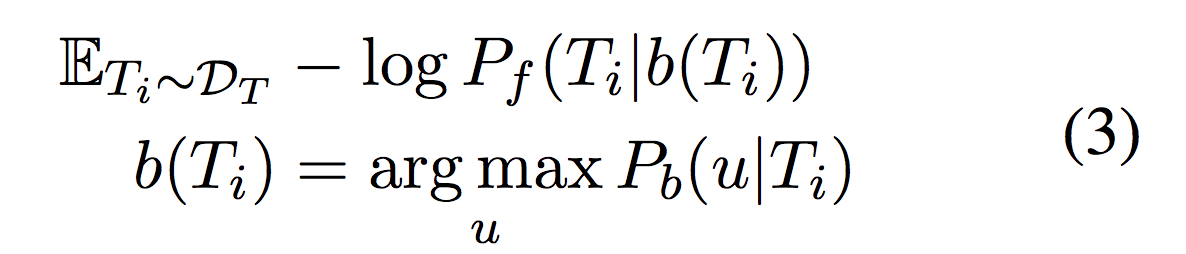
同理,在forward阶段,作者用forward模型创建伪对(pseudo pair)来训练backward模型。目标函数为:
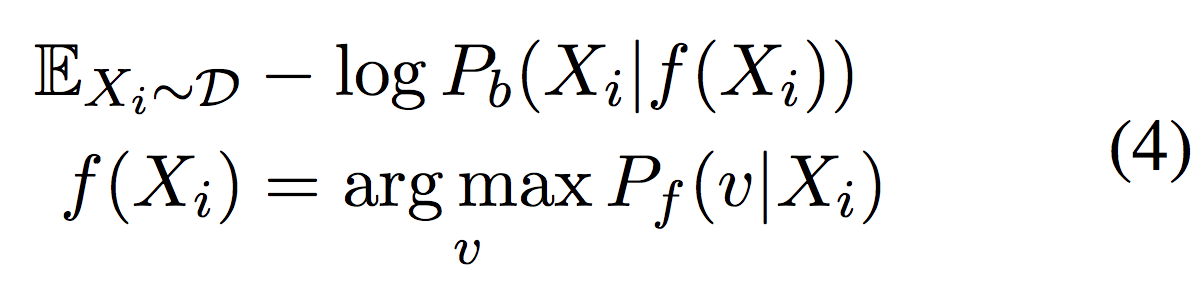
具体的算法如下所示:

作者在两个中文对话任务上进行了实验:豆瓣和微博。作者还对比了standard seq2seq with beam search、MMI、diverse sampling、nucleus sampling和CVAE模型。这些模型都只在聊天语料上进行训练,用了不同目标函数的改进来促进回复的多样化生成。
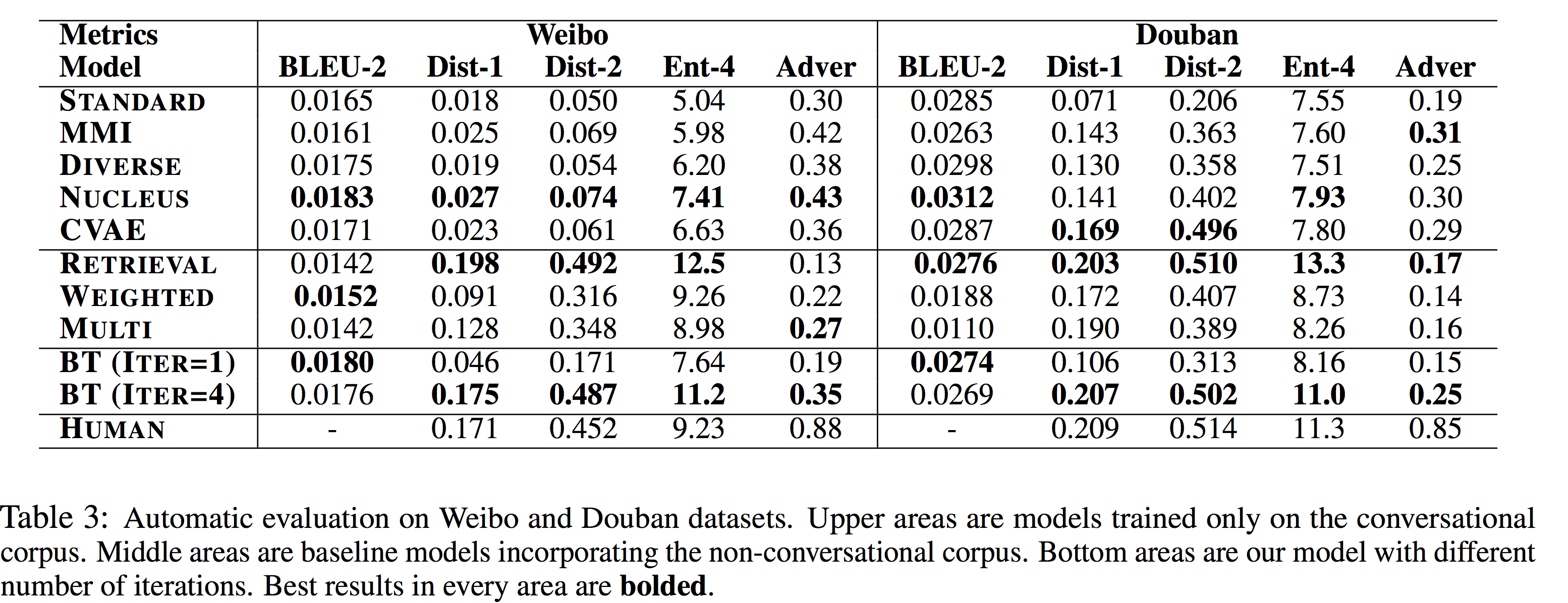
作者首先进行了自动化评论。在表3中,作者汇报了各个模型的BLEU-2分数来测量跟ground-truth的overlap;dist-1、dist-2和ent-4来测量生成回复的多样性;adver来测量回复和上下文的一致性。对于back translation (BT)模型,汇报了模型在第一个和第四个iteration的结果。考虑到模型引入了非聊天语料信息,生成的回复很可能跟原始聊天语料中的词频率、主题有所不同,这样在机器指标自动化评论中会有一个天然的劣势。但是,可以看到模型除了在多样性指标上获得了显著提高之外,在BLEU-2和Adver指标上也并没有下降,说明模型在学习到多样性的同时并没有丢失其它方面的性能。
除了自动化评论,作者也进行了人工评价,结果如表4。作者随机从每个语料中sample了500个实例,让人工去评价每个模型生成的回复的流畅性、多样性和与上下文的一致性。实验结果跟机器指标基本一致。
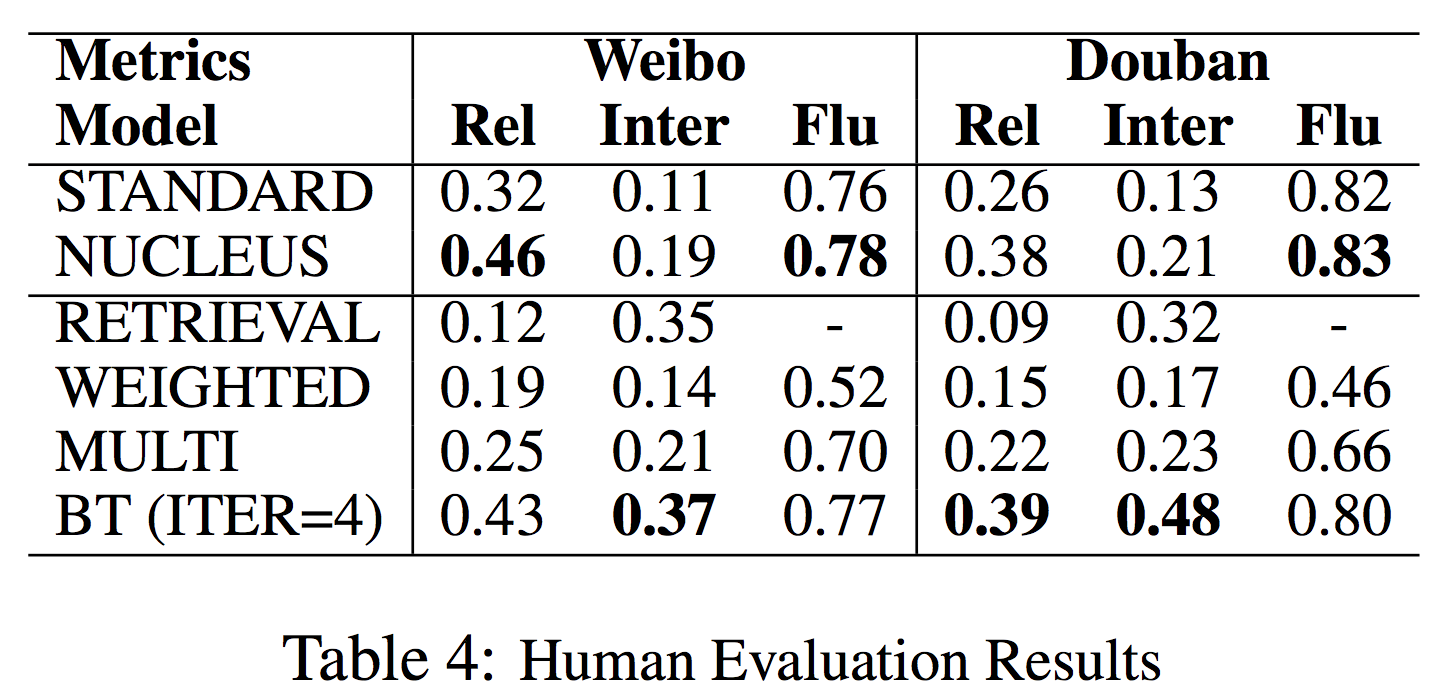
通过对生成回复的结果分析,发现back translation可以学到非聊天语料重的新词和句式,这样就可以通过不同上下文生成在原有非聊天语料中不存在的回复。
在这篇文章里,作者提出了一个新的方式来丰富通用领域的闲聊模型。通过用iterative back translation来有效利用非聊天语料,显示模型可以从词法和语义两个层面都有效地丰富聊天回复。在跟几个基准模型对比后发现,模型显著提高回复的多样性而不降低其它方面的性能。目前的工作迈出了利用非聊天语料来丰富聊天模型的第一步,未来可以结合更加精细化的过滤、筛选来针对不同领域来自适应地选择利用的非聊天语料。
标签:sea 删除 知乎 数据 网络模型 之间 我不知道 lap 利用
原文地址:https://www.cnblogs.com/juncre/p/14865424.html