标签:助教 end view coding beef 方法 pen load 可变
助教补充一:ASCII编码这个部分的内容有一点抽象,大家如果不理解只要大概知道如下意思:计算机存储数据是用0、1存储的,为了存储英文字符等,所以出现了一个ASCII编码表,通过这个表就是把对应的英文转换对应为相应的0、1数据存储到计算机,但是英文只有26个字母,中文有6万多汉字啊,ASCII编码不够,所以,根据需要就出现了unicode、utf-8等编码,实际可以理解为它们把全球的文字编码对应到计算机的0、1来存储识别,归根到底,我们只要记住:我们写python程序的时候使用utf-8编码格式来存储编码格式就可以了,网页里面同样的也声明utf-8即可,utf-8是中文、英文、日文等全球文字都可以使用的编码格式,通用性很强。 你使用PyCharm创建一个.py文件的时候,它会帮你自动使用utf-8格式的哦,如下:
助教补充二:在Python中字节和字符串很类似,很多方法相似,他们的关系其实是这样的:字符串是给人类可以看的懂的,字节是给计算机读懂的,字符串需要存储在计算机中或者在计算机中传播就会转换为字节,平常的字符串存储操作,Python解释器会帮我们自动转换,所以才会有字节可以和字符串互相转换。我们后面用到爬虫的时候,会去目标网站上面爬取数据回来,那么那些数据就是字节数据流,我们需要把这些数据流解码为字符串才能进行处理利用哦。
ASCII编码表
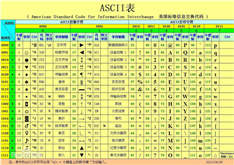
(来自百度百科)
1:计算机只能处理0和1,那么计算机如果需要识别字符,就需要有一套编码机制,ASCII编码由此诞生了。8个bit为一个byte, 11111111 = 255, 那么一个字节最大能够表示255(十进制)。 2:对于英文字母来说,A~Z,a~z 一共才 26 * 2 = 52个,因此,一个字节表示所有的英文字符是满足需要的。但是对于中文来说,是远远不够的。那么GB2312因此诞生了,11111111 11111111 = 65535, 那么按照GB2312就可以表示65535个汉字字符,基本可以满足现代汉字 3:不同国家有不同的字符编码表,例如,在中国,假如 10101011 11010110 表示 “中”, 如果你在日本,使用日本的编码表,对应的10101011 11010110,可能表示的就是“日”。那么,中文写好的文字,按照日文编码表编码,就会出现乱码,这就是为什么,有时候打开某些页面的时候,显示的是乱码,是因为编码表引入错误,没有引入正确的编码表 4:unicode编码的出现,解决了所有语言编码的问题。 但是使用Unicode编码英文字母,本来只需要一个字节的存储空间,变为了两个字节,那么在数据传输的过程中,消耗了更多的带宽 5:utf-8变长编码的出现,解决了这个存储过多的问题,将英文字符使用一个字节编码,中文字符使用三个字节编码。
Python3中引入了两个新的数据类型
bytes
bytearray
bytes是字节组成的,有序的,不可变序列
bytearray是字节组成的,有序的,可变序列
1:编码 字符串按照指定的字符集进行编码,encode方法,返回字节序列bytes str.encode(encoding=‘utf-8‘, errors=‘strict‘) -> bytes 2: 解码 字节按照指定的字符集进行解码,decode方法,返回字符串str bytes.decode(encoding="utf-8", errors="strict") -> str bytearray.decode(encoding="utf-8", errors="strict") -> str
# 定义 bytes() bytes(9) # b‘\x00\x00\x00\x00\x00\x00\x00\x00\x00‘ 被0填充 bytes(‘hello‘, encoding=‘utf-8‘) # 返回 b‘hello‘ ,等价于:‘hello‘.encode() bytes(‘中国‘, encoding=‘utf-8‘) # 返回 b‘\xe4\xb8\xad\xe5\x9b\xbd‘ # 表现形式 bytes使用b前缀定义 只有基本的ASCII可以使用字符表示,例如: ‘xkd‘ 的字节码为 b‘xkd‘ 其他的字符,例如中文,使用十六进制表示, 例如:‘中国‘ 的字节码为:b‘\xe4\xb8\xad\xe5\x9b\xbd‘,每个汉字是3个字节组成 b‘\xe4\xb8\xad‘.decode() 返回 ‘中‘
# 概念 1: bytes的方法与str类似,两者都是不可变类型 2: str输入输出都是str,bytes输入输出都是bytes # 举例 b‘xkd‘.startswith(b‘x‘) 返回 True # 字节可以与十六进制的字符串相互转化 b‘\xde\xad\xbe\xef‘.hex() # 返回16进制表示的字符串deadbeef bytes.fromhex(‘deadbeef‘) # 返回 b‘\xde\xad\xbe\xef‘
# bytearray(string, encoding[, errors]) -> bytearray bytearray(‘hello‘, encoding=‘utf-8‘) 返回 bytearray(b‘hello‘)
# 由于bytearray可变,其操作类似于列表 b = bytearray() b.append(100) b.append(99) b.insert(1,98) b.extend([65,66,67]) b.remove(66) print(b) # 打印出:bytearray(b‘dbcAC‘) b.pop() b.reverse() b.clear()
# 什么是可迭代 可以通过for循环遍历对象中的元素,那么就是可迭代对象 # 如何判断一个对象是可迭代对象 from collections import Iterable isinstance(‘abc‘, Iterable) # 返回 True # 可迭代对象切片, [1,4] 从数学区间概念理解为: [1,4), 且左边一定要小于右边,与之前的概念类似,左边开始值取相等,右边取小于 print(‘abcdefg‘[1:4]) 返回:bcd print([1,2,3,4,5][1:3]) 返回 [2, 3] # 步长 [start:stop:step] print(‘abcdefg‘[1:6:2]) 返回 bdf
本节课主要讲解了Python中的bytes和bytearray两种基本的数据类型,详细说明了如何判断一个对象是否是可迭代对象,和如何对可迭代对象进行切片操作等。
bytes和bytearray是Python3中两个新引入的数据类型;
bytes是字节组成,有序的,不可变的序列;
bytearray和bytes一样,也是字节组成的,也是有序的,但它是可变的序列;
编码:使用encode方法,返回字节序列bytes;
解码:使用decode方法,返回字符串str;
字符串转为字节有两种方式:指明编码格式encoding=‘utf-8‘,或者是用encode方法;
只有基本的ASCII可以使用字符表示,其他的字符,例如中文,则使用十六进制表示;
bytes的方法与str类似,两者都是不可变类型;
str输入输出都是str,bytes输入输出都是bytes;
可以通过for循环遍历对象中的元素,就是可迭代对象;
判断一个对象是可迭代对象,首先导入collections模块下的Iterable类型,然后通过isinstance返回boolean值,可迭代返回True,不可迭代返回False;
可迭代对象的切片:类似与数学区间的概念,左边闭区间,右边开区间,且左边一定要小于右边;
标签:助教 end view coding beef 方法 pen load 可变
原文地址:https://www.cnblogs.com/zhongguiyao/p/14870357.html