标签:lse class col div clust offset RKE producer 数值
kafka 使用日志文件的方式来保存生产者和发送者的消息,每条消息都有一个 offset 值来表示它在分区中的偏移量。Kafka 中存储的一般都是海量的消息数据,为了避免日志文件过大,一个分片 并不是直接对应在一个磁盘上的日志文件,而是对应磁盘上的一个目录,这个目录的命名规则是<topic_name>_<partition_id>。
比如创建一个名为firstTopic的topic,其中有3个partition,那么在 kafka 的数据目录(/tmp/kafka-log)中就有 3 个目录,firstTopic-0~3
多个分区在集群中多个broker上的分配方法
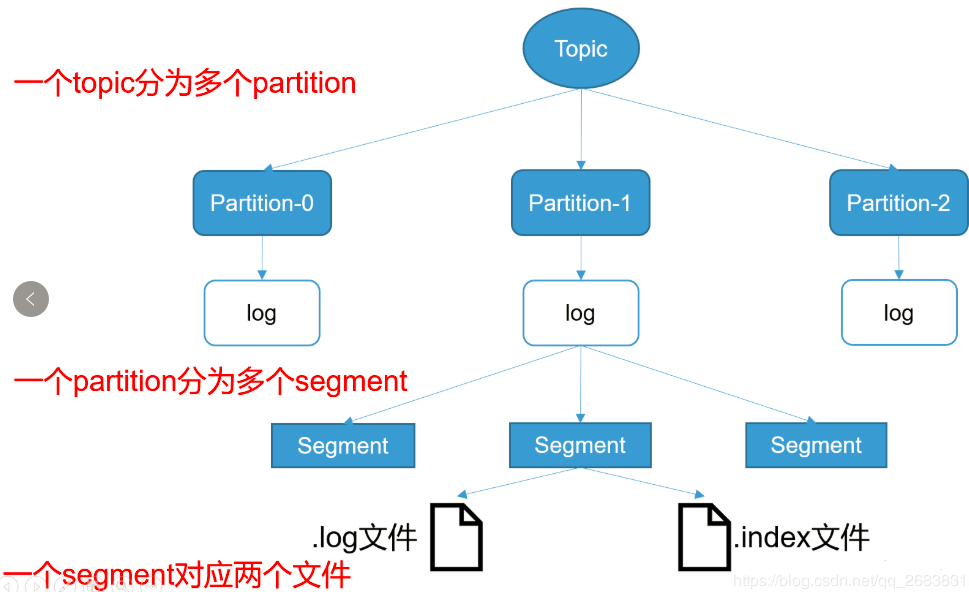
由于生产者生产的消息会不断追加到log文件末端,为防止log文件过大导致数据定位效率低,kafka采取了分片和索引机制,将每个partition分为多个segment(逻辑上的概念,index+log文件)
在Kafka文件存储中,同一个topic下有多个不同partition,每个partition为一个目录,partiton命名规则为topic名称+有序序号,第一个partiton序号从0开始,序号最大值为partitions数量减1。

每个partion(目录)相当于一个巨型文件被平均分配到多个大小相等segment(段)数据文件中。但每个段segment file消息数量不一定相等,这种特性方便old segment file快速被删除。
每个partiton只需要支持顺序读写就行了,segment文件生命周期由服务端配置参数决定。
这样做的好处就是能快速删除无用文件,有效提高磁盘利用率。
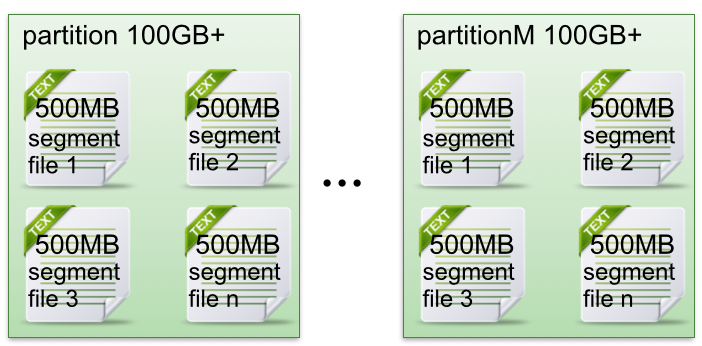
segment file组成:由2大部分组成,分别为index file和data file,此2个文件一一对应,成对出现,后缀”.index”和“.log”分别表示为segment索引文件、数据文件.
segment文件命名规则:partion全局的第一个segment从0开始,后续每个segment文件名为上一个segment文件最后一条消息的offset值。数值最大为64位long大小,19位数字字符长度,没有数字用0填充。
下面文件列表是笔者在Kafka broker上做的一个实验,创建一个topicXXX包含1 partition,设置每个segment大小为500MB,并启动producer向Kafka broker写入大量数据,如下图2所示segment文件列表形象说明了上述2个规则

说明segment中index<—->data file对应关系物理结构如下:

数据文件存储大量消息,索引文件中元数据指向对应数据文件中message的物理偏移地址。 其中以索引文件中元数据3,497为例,依次在数据文件中表示第3个message(在全局partiton表示第368772个message)、以及该消息的物理偏移地址为497。
从上述图了解到segment data file由许多message组成,下面详细说明message物理结构如下

| 关键字 | 解释说明 |
|---|---|
| 8 byte offset | 在parition(分区)内的每条消息都有一个有序的id号,这个id号被称为偏移(offset),它可以唯一确定每条消息在parition(分区)内的位置。即offset表示partiion的第多少message |
| 4 byte message size | message大小 |
| 4 byte CRC32 | 用crc32校验message |
| 1 byte “magic” | 表示本次发布Kafka服务程序协议版本号 |
| 1 byte “attributes” | 表示为独立版本、或标识压缩类型、或编码类型。 |
| 4 byte key length | 表示key的长度,当key为-1时,K byte key字段不填 |
| K byte key | 可选 |
| value bytes payload | 表示实际消息数据。 |
查看".index"索引文件
[root@H__D kafka_2.13-2.6.0-cluster]# sh ./bin/kafka-run-class.sh kafka.tools.DumpLogSegments --files ./data/test-1/00000000000000000016.index --print-data-log Dumping ./data/test-1/00000000000000000016.index offset: 16 position: 0
查看".log"数据文件
[root@H__D kafka_2.13-2.6.0-cluster]# sh ./bin/kafka-run-class.sh kafka.tools.DumpLogSegments --files ./data/test-1/00000000000000000016.log --print-data-log Dumping ./data/test-1/00000000000000000016.log Starting offset: 16 baseOffset: 16 lastOffset: 16 count: 1 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 9 isTransactional: false isControl: false position: 0 CreateTime: 1623255516293 size: 72 magic: 2 compresscodec: NONE crc: 238920327 isvalid: true | offset: 16 CreateTime: 1623255516293 keysize: -1 valuesize: 4 sequence: -1 headerKeys: [] payload: aaaa baseOffset: 17 lastOffset: 17 count: 1 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 9 isTransactional: false isControl: false position: 72 CreateTime: 1623255857294 size: 71 magic: 2 compresscodec: NONE crc: 1925342702 isvalid: true | offset: 17 CreateTime: 1623255857294 keysize: -1 valuesize: 3 sequence: -1 headerKeys: [] payload: mmm
例如读取offset=368776的message,需要通过下面2个步骤查找。
第一步查找segment file 上述图2为例,其中00000000000000000000.index表示最开始的文件,起始偏移量(offset)为0.第二个文件00000000000000368769.index的消息量起始偏移量为368770 = 368769 + 1.同样,第三个文件00000000000000737337.index的起始偏移量为737338=737337 + 1,其他后续文件依次类推,以起始偏移量命名并排序这些文件,只要根据offset **二分查找**文件列表,就可以快速定位到具体文件。 当offset=368776时定位到00000000000000368769.index|log
第二步通过segment file查找message 通过第一步定位到segment file,当offset=368776时,依次定位到00000000000000368769.index的元数据物理位置和00000000000000368769.log的物理偏移地址,然后再通过00000000000000368769.log顺序查找直到offset=368776为止。
从上述图3可知这样做的优点,segment index file采取稀疏索引存储方式,它减少索引文件大小,通过mmap可以直接内存操作,稀疏索引为数据文件的每个对应message设置一个元数据指针,它比稠密索引节省了更多的存储空间,但查找起来需要消耗更多的时间。
参考:https://tech.meituan.com/2015/01/13/kafka-fs-design-theory.html
标签:lse class col div clust offset RKE producer 数值
原文地址:https://www.cnblogs.com/h--d/p/14871852.html