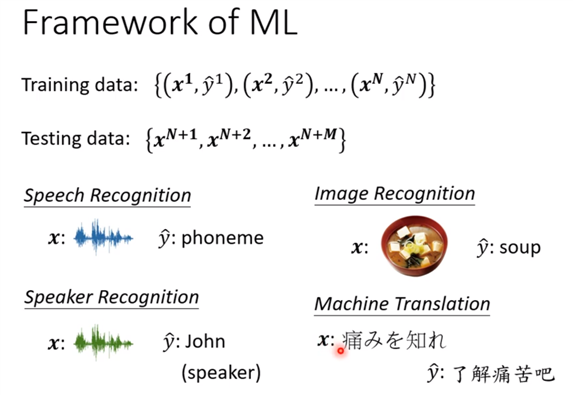
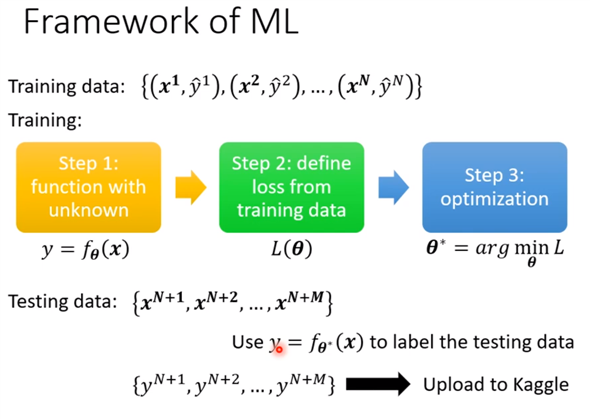
标签:其他 baseline width 努力 function alt data info 接下来
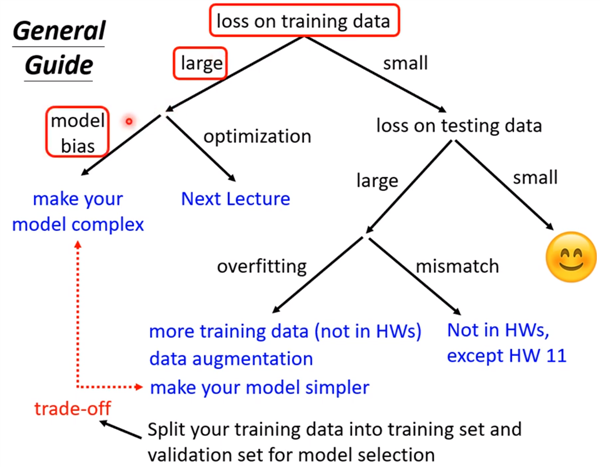

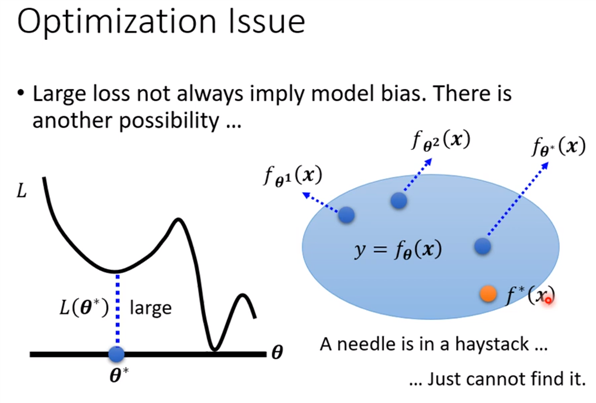

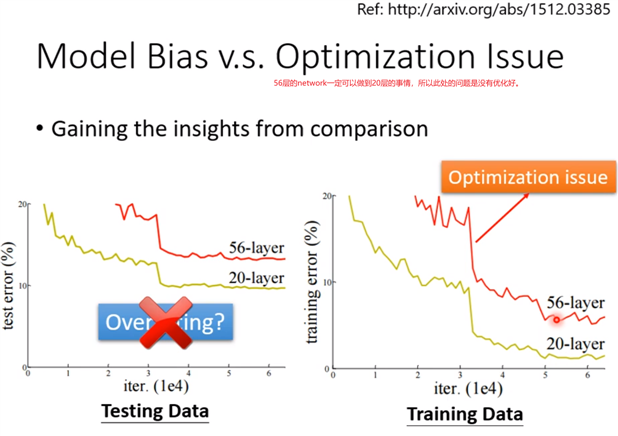
56层只要把前20层参数河这个20层的参数一样,后面36层就什么都不做,只复制前一层的输出就好;所以56层一定可以做大20层的network做的事情;56层比20层的弹性更大,多以没有道理做的没有20层的好。所以此处不是overfitting,也不是model bias,因为56层network弹性是够的,问题是optimization不给力,做的不够好。当你不确定你的优化是否做好使,建议是当你遇到你没有做过的问题,也许你可以先跑一些比较小的或比较浅的network model或比较简单的model,甚至可以用一些不是deep learning的方法,比如linear model,SVM,这些可能是比较容易做optimize,比较不会有optimization失败的问题,这些model会竭尽全力的在他们的能力范围内找一组最好的参数,比较不会有失败的问题。在这些简单的model结果上,可以知道到底能够得到什么样的loss,接下来再train一个深的model,

e.g.,
比如上图,5层反而在训练数据上的loss比4层大,这说明是optimization的problem,那optimization做的不好怎么办呢?有更强大的技术在下一次课讲解。
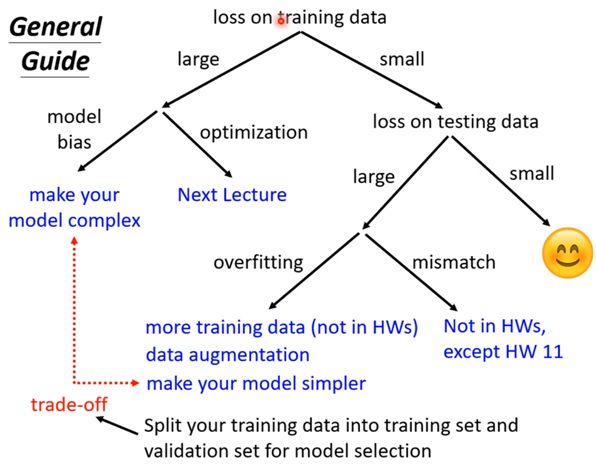
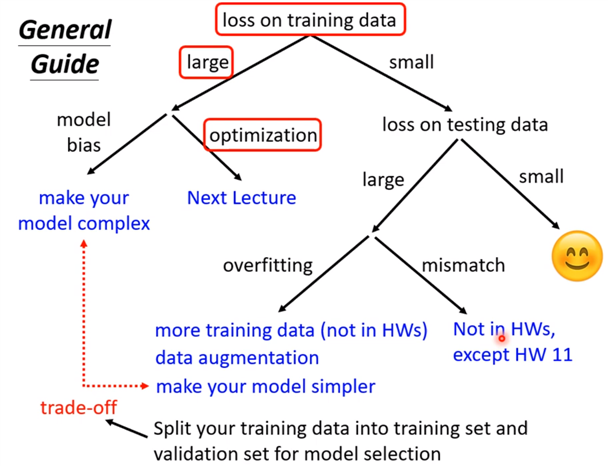
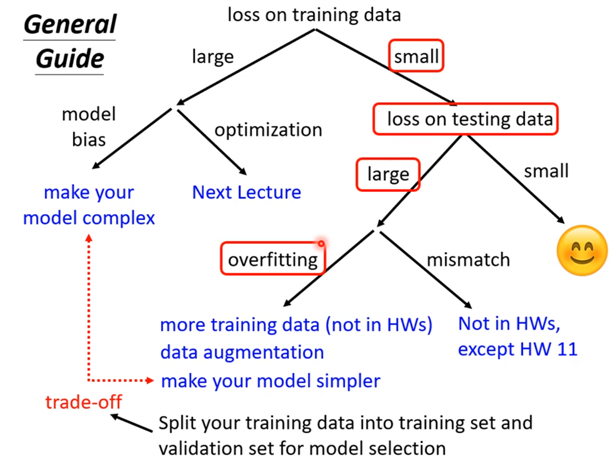
现在先知道如果你的training的loss大,到底是model bias还是optimization问题,前者只需要把model变大,后者则有其他的方法。
假设现在经过一番努力,已经可以把training data的loss变小了,那么看一下在testing data上的loss是否也小,如果小,比strong baseline还小,那就没什么好做的,就结束了;
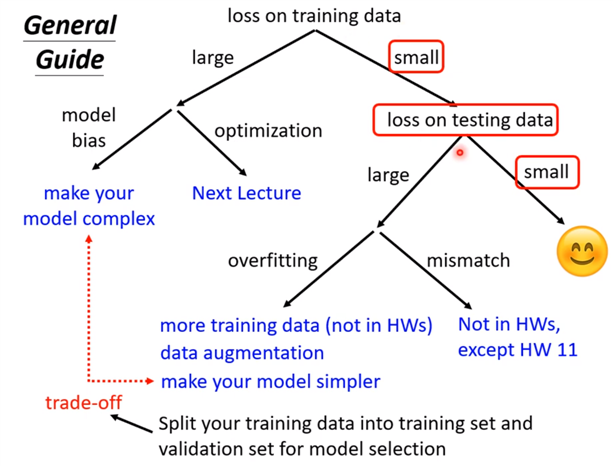
如果在测试集testing上的loss较大,而在training上的loss小,可能就真的遇到over fitting 了。不要一遇到在testing上的结果不好就说是overfitting,而是训练集loss小,测试机loss大,才是overfintting。
所以一定要先把training data上的loss记下来,并要确定你的optimization没有问题,且你的model够大了,接下来再看看是不是testing的问题。接下来如果是训练集loss小,测试集loss大,才有可能是overfitting。
那为何会有overfitting呢?举个极端的例子:
某个很差的机器学习方法,找到了一个一无是处的function,这个方程式,如果某个样本x当作输入时,我们就比对这个x是否出现在训练资料里面,如果有的话,就把他对应的y当作输出;如果没有出现在训练资料里,那么就输出一个随机的数值;
可以看到,这个方程任何事情都没做,但是他在training上的loss确是0;因为你把training的data输入这个方程里面,他的输出和你训练资料的label是一模一样的,所以在training data 上面,这个很差的function的loss是0;只是在testing data上他的loss会变得很大,因为他上面都没有学;此为比较极端的例子,但是在一般状况下,也有可能发生类似的事情,e.g.:
标签:其他 baseline width 努力 function alt data info 接下来
原文地址:https://www.cnblogs.com/Li-JT/p/14871379.html