标签:src lazy learning enc 技术 relay tab programs titan
TVM 各个模块总体架构


Deploy Deep Learning Everywhere

Existing Deep Learning Frameworks
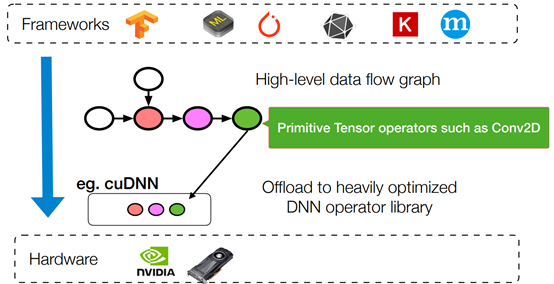
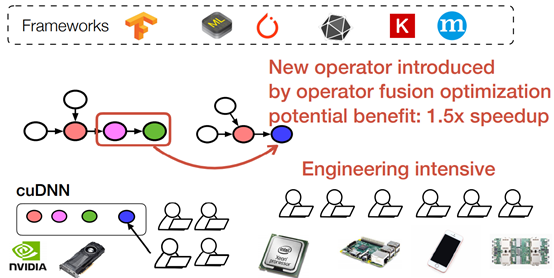
Limitations of Existing Approach
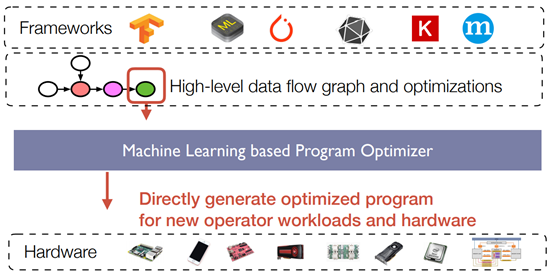
Learning-based Learning System
Problem Setting
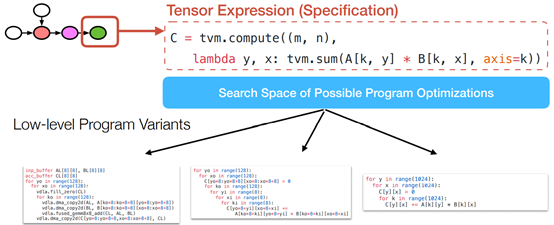
Example Instance in a Search Space
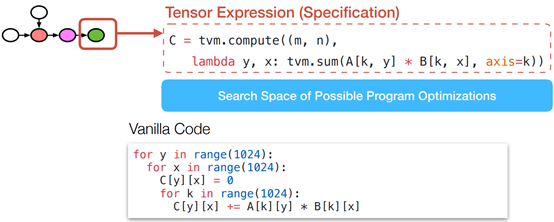
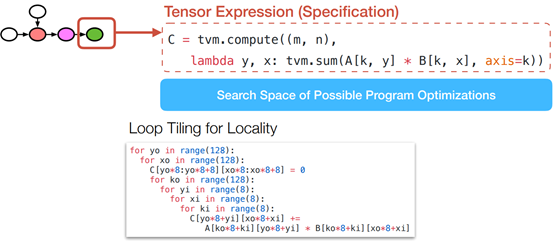
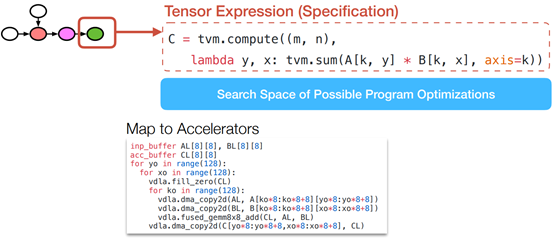
Optimization Choices in a Search Space
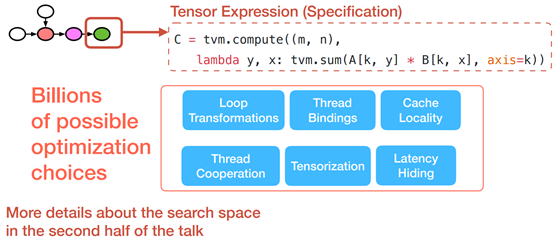
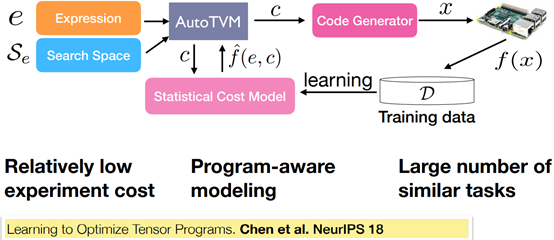
Problem Formalization
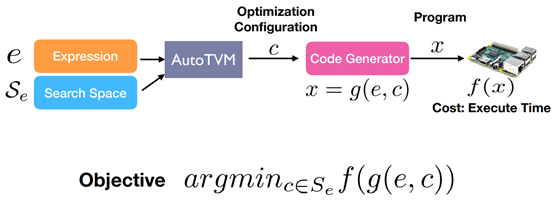
Black-box Optimization
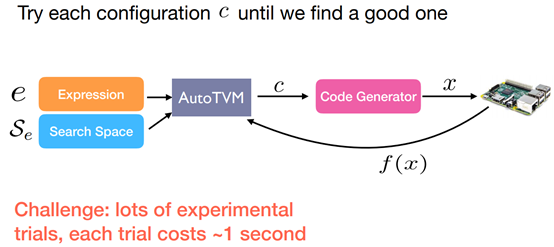
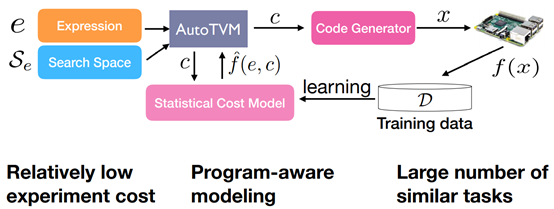
Cost-model Driven Approach
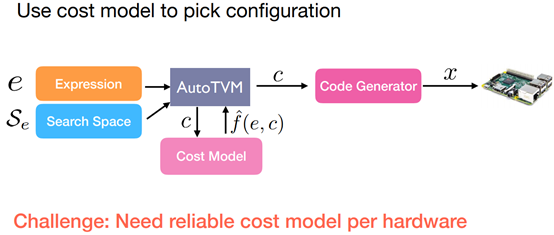
Statistical Cost Model
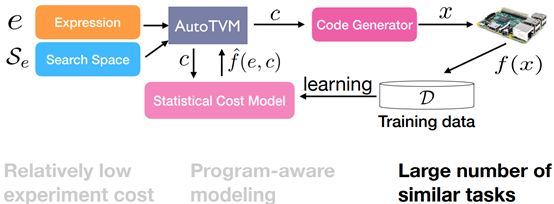
Unique Problem Characteristics
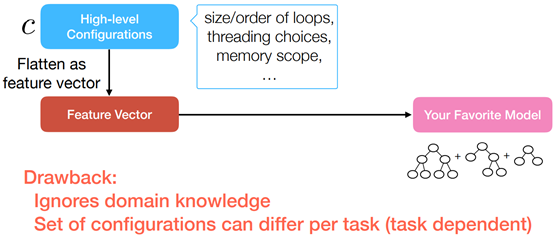
Vanilla Cost Modeling
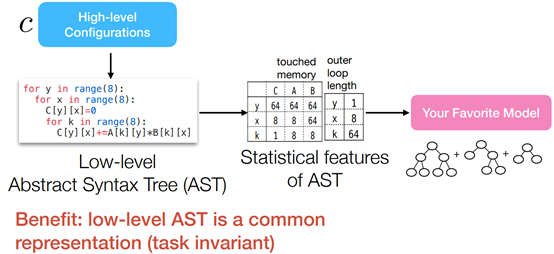
Program-aware Modeling: Tree-based Approach
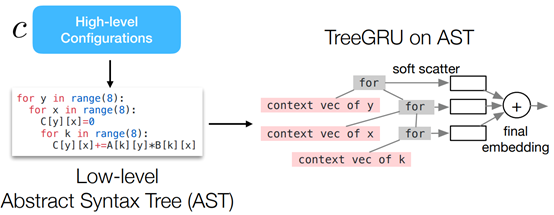
Program-aware Modeling: Neural Approach
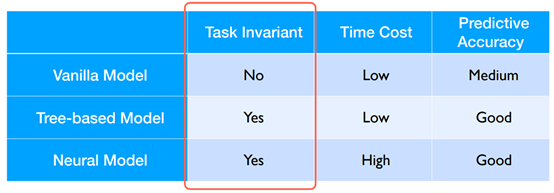
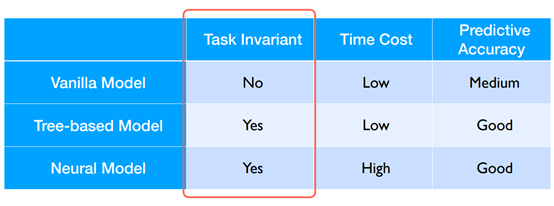
Comparisons of Models
Unique Problem Characteristics
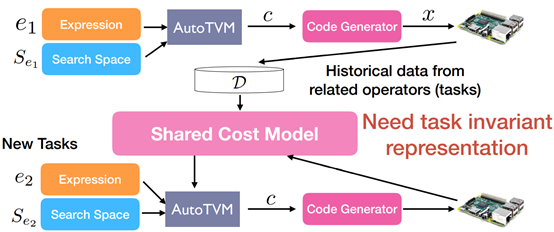
Transferable Cost Model
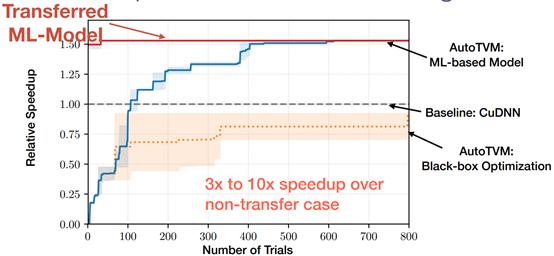
Impact of Transfer Learning
Learning to Optimize Tensor Programs
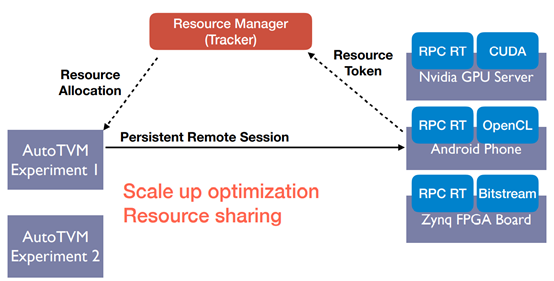
Device Fleet: Distributed Test Bed for AutoTVM
TVM: End to End Deep Learning Compiler

Tensor Expression and Optimization Search Space

Search Space for CPUs
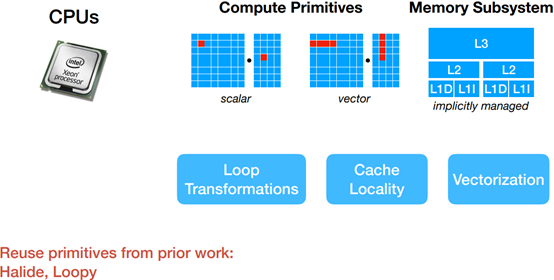
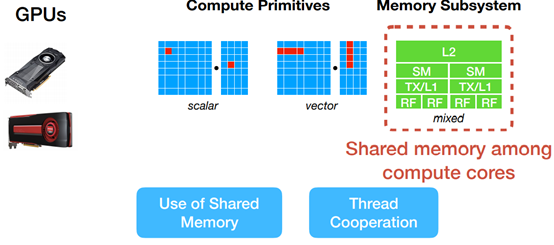
Hardware-aware Search Space

Search Space for GPUs
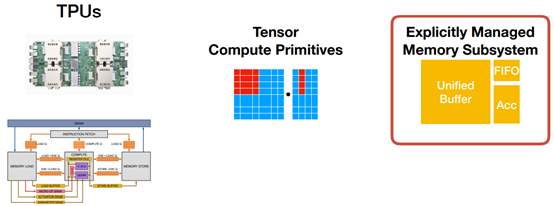
Search Space for TPU-like Specialized Accelerators
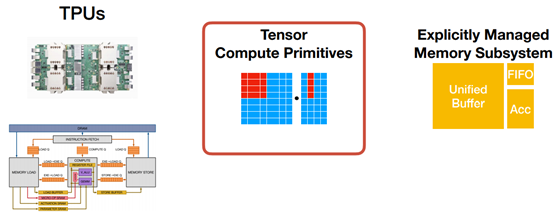
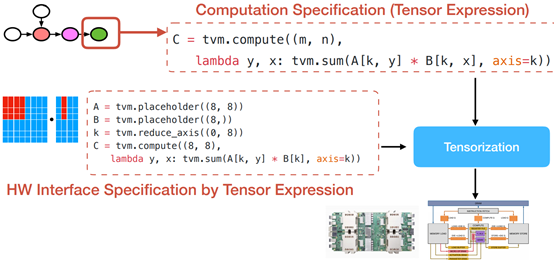
Tensorization Challenge
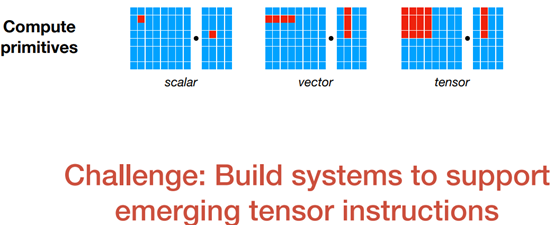
Tensorization Challenge
Search Space for TPU-like Specialized Accelerators
Software Support for Latency Hiding
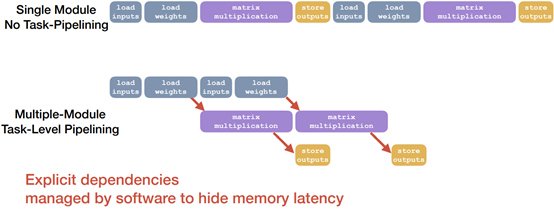
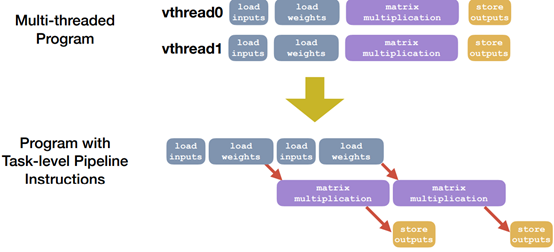
Summary: Hardware-aware Search Space
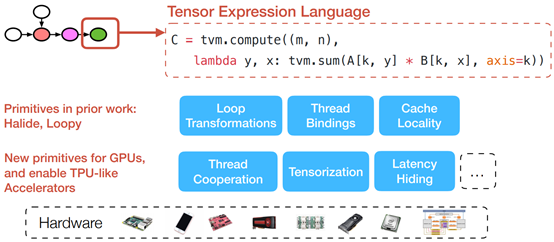
VTA: Open & Flexible Deep Learning Accelerator
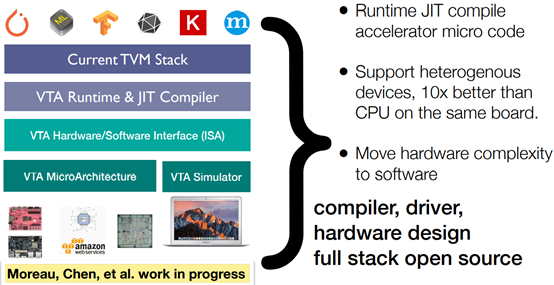
TVM: End to End Deep Learning Compiler

Need for More Dynamism
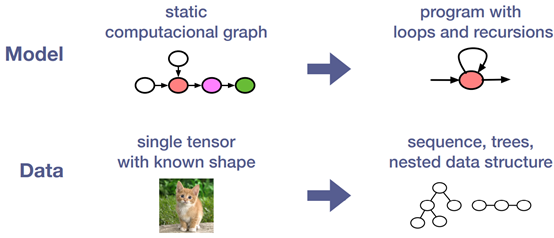
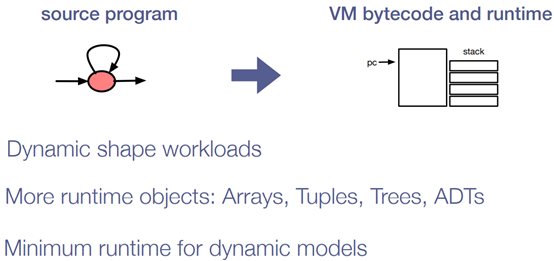
Relay Virtual Machine
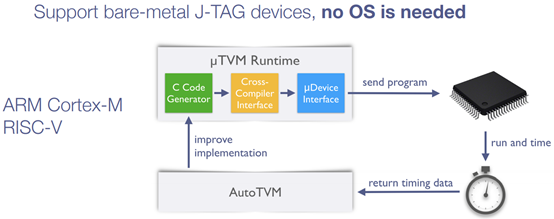
uTVM: TVM on bare-metal Devices
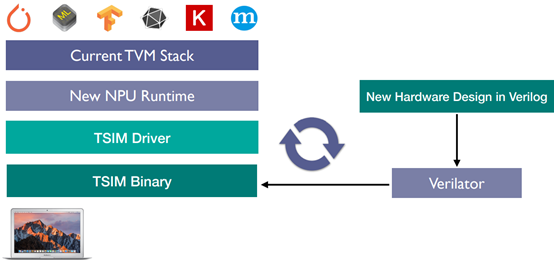
Core Infrastructure

TSIM: Support for Future Hardware
Unified Runtime For Heterogeneous Devices
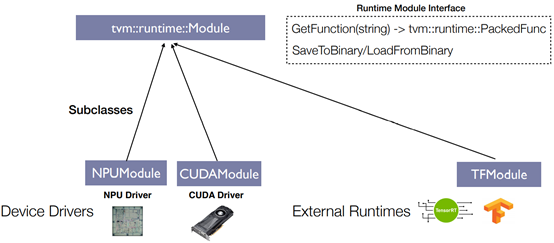
Unified Runtime Benefit

Effectiveness of ML based Model
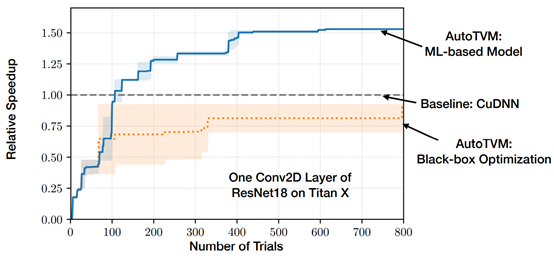
Comparisons of Models
Device Fleet in Action

End to End Inference Performance (Nvidia Titan X)
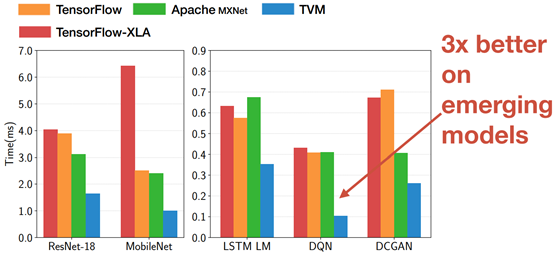
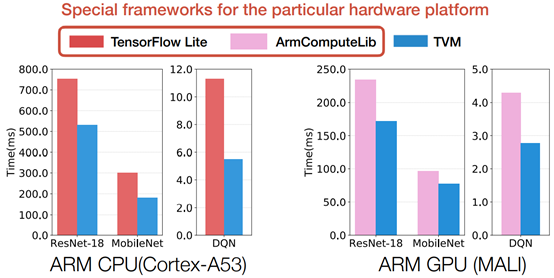
Portable Performance Across Hardware Platforms
标签:src lazy learning enc 技术 relay tab programs titan
原文地址:https://www.cnblogs.com/wujianming-110117/p/14878746.html