标签:loading 标签 训练 计算 模型 mbed 语义 根据 相似度
首先试验了以下三个预训练模型在语义相似度任务上的效果:
处于效率的考虑,进行语义相似度任务的时候不是将两个语句拼接传入模型再通过[CLS]位置对应的值作为其相似度,而是通过计算两个语句的特征向量,然后通过余弦相似度作为他们的相似度表征。
最后根据测试的效果使用了hfl-chinese-roberta-wwm-ext作为我们的预训练模型
我们参考Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks这个论文中使用孪生网络的训练方法来训练BERT,使其能在语义相似度任务上取得较好的成绩。
我们首先根据论文中的训练方法将roberta模型在lcqmc以及nli语料库上进行了微调,微调后的模型在语义相似度任务上已经具有较好的效果。
接着我们考虑减小模型的体积,为此,我从模型中抽出了1,4,7,10层来构成一个新的模型,接着使用模型蒸馏的方法来使得这个小模型能具有与原先模型差不多的效果。模型蒸馏过程中使用到的数据集包括lcqmc、nli以及tnews。
对于训练好的模型,我们将语句传入模型得到输出再经过一层mean pooling作为其特征向量。然后通过计算两个特征向量之间的余弦相似度来表示两个语句之间的相似度。
在训练过程中一共使用了一下语料库

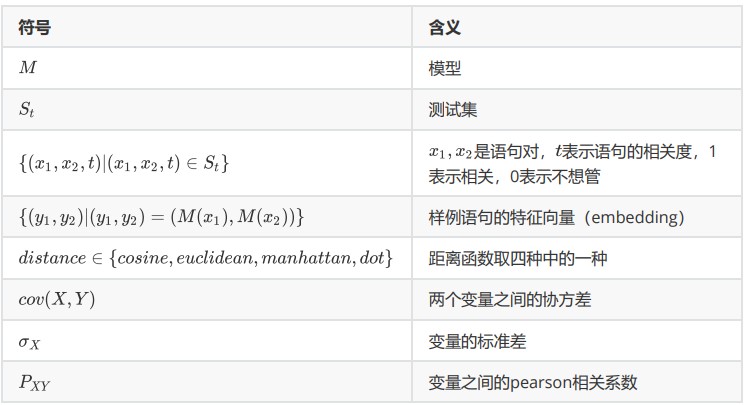
通过计算距离与标签相关系数作为模型的评价指标。
在以下部分,通过distance表示上面所示四个距离中的某一个
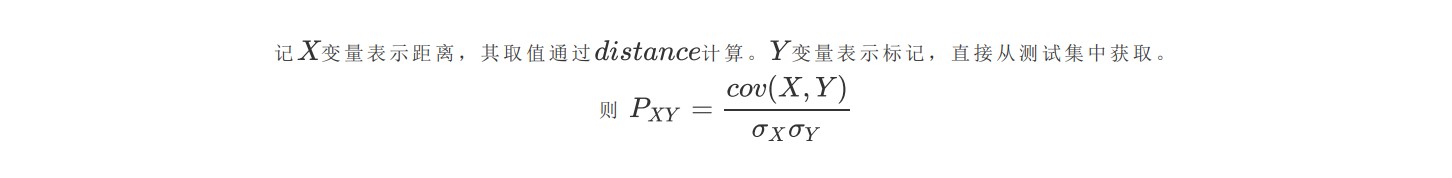
distillation-sts_2021-05-28_17-33-59
| 评价指标 | 分数 |
|---|---|
| cosine_pearson | 0.7560853342352258 |
| euclidean_pearson | 0.790755951697049 |
| manhattan_pearson | 0.7905980256878025 |
| dot_pearson | 0.7500113350858096 |
roberta-zh-nli-sts-2021-05-27_12-43-40
| 评价指标 | 分数 |
|---|---|
| cosine_pearson | 0.7666978395294516 |
| euclidean_pearson | 0.804099045672043 |
| manhattan_pearson | 0.8039674474113313 |
| dot_pearson | 0.7645833655053875 |
标签:loading 标签 训练 计算 模型 mbed 语义 根据 相似度
原文地址:https://www.cnblogs.com/DQSJ2021/p/14887388.html