标签:代码 red child pool eve code The 图像 ima
两个将transformer用于图像分类任务的尝试.
其实将transformer用于图像分类任务, 关键的问题是如果生成tokens.
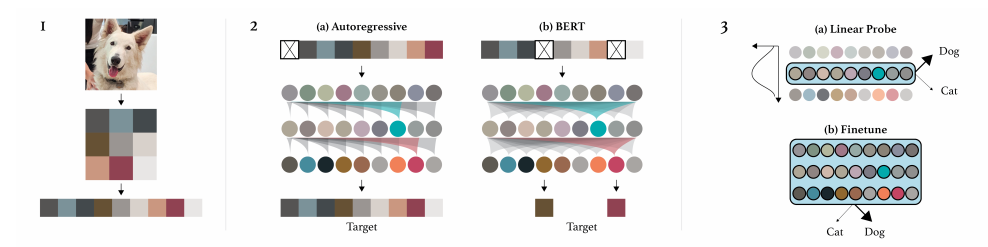
iGPT生成tokens方式很粗暴, 将图片拉成向量, 每一个element对应一个token, 然后根据‘字典’获得相应的embeddings. 但是普通的图片, 比如224x224x3, 由于transformer的memory需求是四次方的, 显然这个tokens数目无法计算, 所以本文会首先对图片进行压缩, 比如至32x32x3, 但是这样依然不够.
但是32往下的size对于人来说已经不易辨别了, 虽然本文采取的策略是将3通道压缩为1通道. 通过对图片进行k均值分类(k=512), 然后为每个像素点分配中心, 作者发现这么做效果不错.
注: 因此字典的大小也应该是长度也应该是512.
注: 在fine-tuning的时候, 因为最后的输出是(B, S, D), 也没法直接加全连接层分类, 故首先通过average pooling 变成(B, D), 再通过\(W^{K \times D}\)获得logits.
ViT则不这么粗暴, 其首先将图片分割成一个个patch, 然后通过一个线性投影\(W\)变成embeddings, 注意这里不再是NLP中的通过字典索取了.
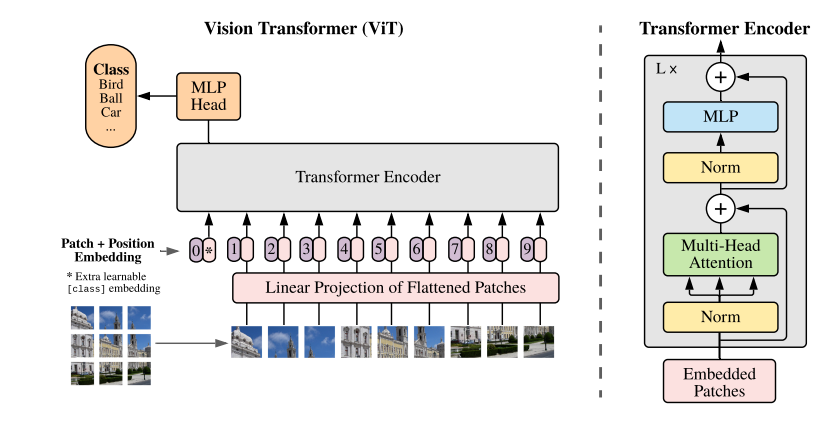
需要特别注意的是, 第一个embedding对应的是类别的embedding, 其对应的输出\(Z_0^L\)(最后的第0个token)用于最后的分类任务. 故不像iGPT, ViT其实是有监督的.
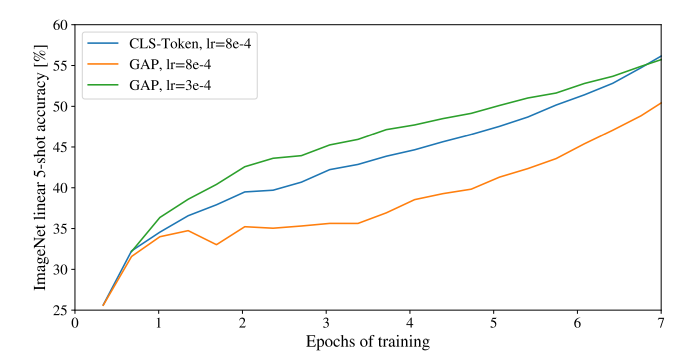
为什么不想iGPT一样通过average pooling来使用所有tokens来分类呢?
其实是可以的, 作者他们最先尝试的就是这个策略, 但是由于学习率没调好, 所以本文显示加了类别的token, 实际情况如下图:
能否从有监督变成自监督?
其实也是可以的, 可以最后预测每一个patch的平均值:
Finally, we predict the 3-bit, mean color (i.e. 512 colors in total) of every corrupted patch using their respective path representations.
positional embeddings有什么影响?
作者试了1-D, 2-D, 以及相对编码, 在第一层, 每一层(单独), 每一层(共享)策略下比较, 发现相差无几, 但是有位置编码会比无位置编码好很多.
标签:代码 red child pool eve code The 图像 ima
原文地址:https://www.cnblogs.com/MTandHJ/p/14907867.html