标签:本质 管理 操作 core image direct rect 取数 level
RDD依赖关系有2种不同类型,窄依赖和宽依赖。
窄依赖(narrow dependency):是指每个父RDD的Partition最多被子RDD一个Partition使用。就好像独生子女一样。窄依赖的算子包括:map,filter,flatMap等。如下图 :1对1 , 多对1
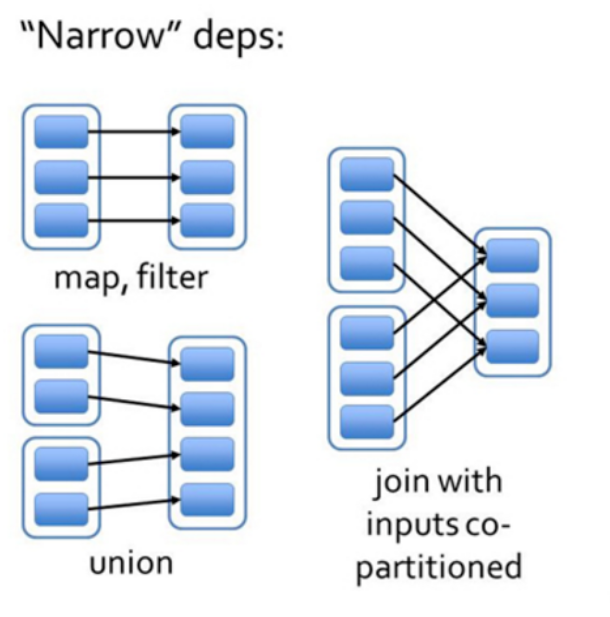
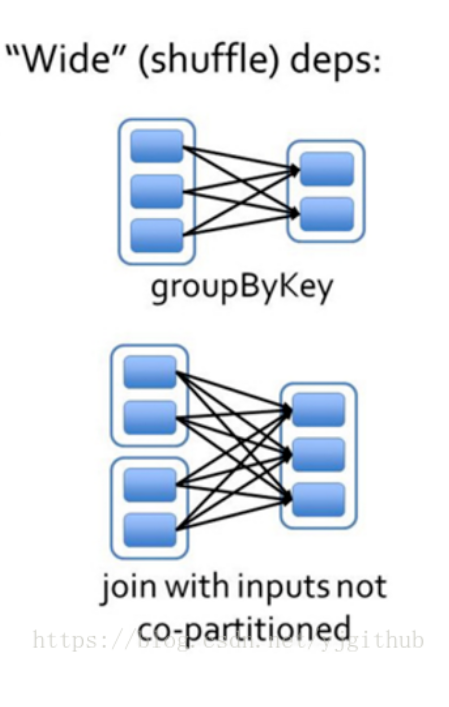
1.宽依赖往往对应着shuffle操作( 多对多,汇总,多节点),需要在运行过程中将同一个父RDD的分区传入到不同的子RDD分区中,中间可能涉及多个节点之间的数据传输;而窄依赖的每个父RDD的分区只会传入到一个子RDD分区中,通常可以在一个节点内完成转换。
2.当RDD分区丢失时(某个节点故障),spark会对数据进行重算。
a. 对于窄依赖,由于父RDD的一个分区只对应一个子RDD分区,这样只需要重算和子RDD分区对应的父RDD分区即可,所以这个重算对数据的利用率是100%的;
b. 对于宽依赖,重算的父RDD分区对应多个子RDD分区,这样实际上父RDD 中只有一部分的数据是被用于恢复这个丢失的子RDD分区的,另一部分对应子RDD的其它未丢失分区,这就造成了多余的计算;更一般的,宽依赖中子RDD分区通常来自多个父RDD分区,极端情况下,所有的父RDD分区都要进行重新计算。
我们后期可以把RDD数据缓存起来,后续其他的job需要用到该RDD的结果数据,可以直接从缓存得到避免重复计算。魂村可以加快数据访问。
RDD设置缓存方式有2种:
进入 spark shell 演示
spark-shell --master spark://1.0.0.155:7077 --executor-memory 1g --total-executor-cores 2
cache使用
# 从hdfs读取
scala> val rdd1 = sc.textFile("/u.txt")
# 计入缓存
scala> rdd1.cache
# 此时查看http://linux01:4040/Storage/ 是没有任何缓存信息,这是因为在使用cache时候需要action触发
scala> rdd1.collect
# 可以看到如下图

# 你可以继续进行算子操作
scala> val rdd2 = rdd1.flatMap(_.split(" "))
# 通过触发action,从缓存拿取数据,执行算子操作
scala> rdd2.collect
当退出spark-shell缓存也随之消失
presist使用
# 虽然设置内存和磁盘的级别,但保存数据量较小,是不会分配到磁盘上的。
scala> rdd2.persist(org.apache.spark.storage.StorageLevel.MEMORY_AND_DISK_SER_2)
scala> rdd2.collect
# 如果想直接保存到磁盘,更改级别。
scala> val rdd3 = rdd2.map(x=>(x,1))
scala> rdd3.persist(org.apache.spark.storage.StorageLevel.DISK_ONLY)
scala> rdd3.collect
从rdd1->rdd2->rdd3-> ..rddn 每一个步骤,如果设置缓存它会从缓存中拿取数据,而不是通过计算后再执行下一个算子操作。
缓存之后生命周期
当任务结束,缓存数据也随之消失
缓存数据的清除
1.自动清除
程序执行完毕,自动清除
2.手动清除
scala> rdd1.unpersist(true) // 默认为true,表示阻塞删除
关于缓存设置应用场景
1.当某个RDD的数据被使用多次,可以设置缓存
val rdd1 = sc.textFile("words.txt")
rdd1.cache
val rdd2=rdd1.flatMap(_.split(" "))
val rdd3=rdd1.map((_,1))
rdd2.collect
rdd3.collect
2.当某个RDD它是经过大量复杂算子操作,计算周期时间很长,将它设置缓存。
当对RDD数据进行缓存,保存在内存或磁盘中,后续就可以直接从内存或者磁盘中获取得到,但是不安全。
而checkpoint机制它提供一种相对更加可靠数据持久方式,它把数据保存在分布式文件系统上,比如HDFS上,它利用HDFS高可用,高容错(多副本)来保证数据安全性。
checkpoint的使用
# hdfs创建checkponit目录
scala> sc.setCheckpointDir("/checkpoint")
# 此时查看hdfs 多了一个checkpoint
[root@linux01 data]# hdfs dfs -ls /
drwxr-xr-x - root supergroup 0 2021-06-22 13:18 /checkpoint
# 读出文件
scala> val rdd1=sc.textFile("/u.txt")
# 对rdd1进行checkpoint
scala> rdd1.checkpoint
# 算子操作
scala> val rdd2 = rdd1.flatMap(_.split(" "))
# 触发action 才会触发checkpoint
scala> rdd2.collect
# 查看hdfs保存文件,可以看到多了part-00000和part-00001两个文件
[root@linux01 data]# hdfs dfs -ls /checkpoint/e5a6cb9f-373c-44ec-8730-7eda0e6067dc/rdd-3
part-00000
part-00001
http://linux01:4040/jobs/ job任务看到会有2个job任务完成,其中一个就是checkpoint,一个是job任务。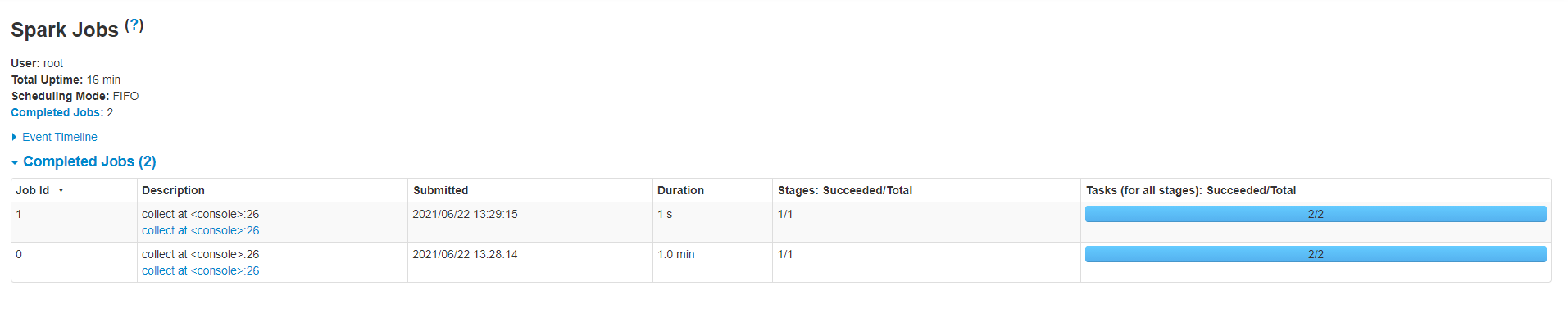
cache和presist分别可以把RDD数据缓存在内存或者本地磁盘,后续要触发cache和presist持久化操作。需要有一个action,它不会开启其他新的job,一个action对应一个job。在运行的过程到程序结束后,对应的缓存数据就自动消失了。它不会改变RDD的依赖关系。
checkpoint:可以把数据持久写入hdfs上,后续要触发checkpoint操作,需要有一个action、任务在运行过程到程序结束之后,对应缓存数据不会消失,它会改变rdd的依赖关系。后续数据丢失了不能再通过血统进行数据恢复。
checkpoint操作要执行需要一个action操作,一个action操作对应后续的一个job,该job执行完成之后,它会再次单独开启另一个job来执行rdd1.checkpoint操作。
所以checkpoint执行action会开启2个job,而cache,presist 只会开启1个job
cache -> checkpoint -> 重新计算
DAG(Directed Acyclic Graph)叫做有向无环图(有方向,无闭环,代表着数据的流向),原始RDD通过一系列的转换形成了DAG
当我们执行一个单词统计的job任务时候,登录到:http://linux01:4040/jobs/可以查看到DAG图,如下图:
sc.textFile("/u.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
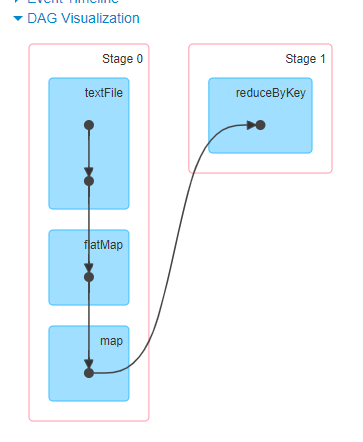
stage表示不同的调度阶段,一个spark中的job 会对应很多个stage(调度阶段)。
为什么要划分stage?
由于在同一个stage中,没有宽依赖,都是窄依赖,后期spark的任务是以task线程方式去运行的,一个分区就对应一个task,在同一个stage中有很多可以并行运行的task。
1、拿到DAG有向无环图之后,从最后一个RDD往前推,首先创建一个stage,然后把当前RDD加入到本stage中。它是最后一个stage。
2、在往前推的过程中,如果遇到窄依赖,就把该RDD加入到stage中,如果遇到宽依赖,就从宽依赖切开,当前一个stage也就结束了。
3、然后重新创建一个新的stage,还是按照第二个步骤往前推,一直到最开始RDD。
划分stage之后,每一个stage中有很多可以并行运行的task,后期它会把每个stage中这些可以并行运行的task封装在一个taskSet集合中。它会把taskSet集合中的task线程提交到worker节点上的executor进程中运行。
spark-RDD缓存,checkpoint机制,有向无环图,stage
标签:本质 管理 操作 core image direct rect 取数 level
原文地址:https://www.cnblogs.com/xujunkai/p/14919490.html