标签:epo driver x86_64 rem space key erro 返回 gre
先安装nvidia驱动,然后安装cuda
lspci | grep -i nvidia
sudo dpkg --list | grep nvidia-*
有以下三种nvidia驱动安装方式.
sudo add-apt-repository ppa:graphics-drivers/ppa
sudo apt-get update
通过System Settings->SoftWare & Updates->Additional Drivers 切换安装,推荐安装高版本的驱动, 例如410
sudo add-apt-repository ppa:graphics-drivers/ppa
sudo apt-get update
sudo apt-get install nvidia-410 nvidia-settings nvidia-prime
注: 驱动安装后要重启电脑
sudo reboot
查看驱动版本和显卡属性:
nvidia-smi
在终端中输入
watch -n 10 nvidia-smi
注:每隔10秒刷新一次终端
sudo apt-get --purge remove nvidia-*
有的电脑需要在4.4.168的内核上安装驱动,否则重启后循环进入登录界面。
CUDA Toolkit
推荐安装cuda9.0或cuda10.0, 首先安装cuda,然后安装相应的补丁。
选择Linux -> x86_64 -> Ubuntu -> 16.04 -> runfile(local) 或者deb(local)
sudo chmod +x cuda_10.0.130_410.48_linux.run
sudo ./cuda_10.0.130_410.48_linux.run
cat /usr/local/cuda/version.txt
注: EULA文档阅读, 点击space键会一页一页翻过,那么阅读完文档仅需几秒钟即可。
注:该方式中会提示是否安装相应的nvidia驱动,选择no;
注:该方式中会提示是否建立到/usr/local/cuda的软链接, 选择yes;
注: 该方式中会提示是否安装samples, 选择no;
注: 推荐使用.runfile方式安装.
sudo dpkg -i cuda-repo-ubuntu1604-10-0-local-10.0.130-410.48_1.0-1_amd64.deb
sudo apt-key add /var/cuda-repo-10-0-local-10.0.130-410.48/7fa2af80.pub
sudo apt-get update# 参考
- [Install CUDA 10.0, cuDNN 7.3 and build TensorFlow (GPU) from source on Ubuntu 18.04](https://medium.com/@vitali.usau/install-cuda-10-0-cudnn-7-3-and-build-tensorflow-gpu-from-source-on-ubuntu-18-04-3daf720b83fe)
- [Ubuntu 16.04配置TensorFlow-GPU 1.6.0](https://wenku.baidu.com/view/33e1ccb1ed3a87c24028915f804d2b160a4e8670.html)
- [Ubuntu下实时查看Nvidia显卡显存占用情况](https://blog.csdn.net/breeze5428/article/details/78928596)
sudo apt-get install cuda
cat /usr/local/cuda/version.txt
注: cuda9安装后,还有四个补丁需要安装.
打开个人配置文件:
sudo gedit ~/.zshrc
在文件尾部输入以下命令:
export PATH=/usr/local/cuda/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH
更新变量环境
source ~/.zshrc
注: 前面已经建立了cuda版本和cuda的软链接.
对于安装了多个版本的cuda, 通过改变软连接形式来调用cuda的版本
sudo rm -rf /usr/local/cuda ## 这个必须
sudo ln -s /usr/local/cuda-9.0 /usr/local/cuda ## 使用cuda 9.0
sudo ln -s /usr/local/cuda-10.0 /usr/local/cuda ## 使用cuda 10.0
nvcc -V
cd /usr/local/cuda/bin
sudo ./uninstall_cuda_XX.pl
sudo rm -rf /usr/local/cuda-XX/
使用cuda里面的samples来测试是否安装成功
cd /usr/local/cuda-10.0/samples/1_Utilities/deviceQuery
sudo make
./deviceQuery
和
cd usr/local/cuda-10.0/samples/1_Utilities/bandwidthTest
sudo make
./bandwidthYest
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 10.1, CUDA Runtime Version = 10.0, NumDevs = 1
Result = PASS
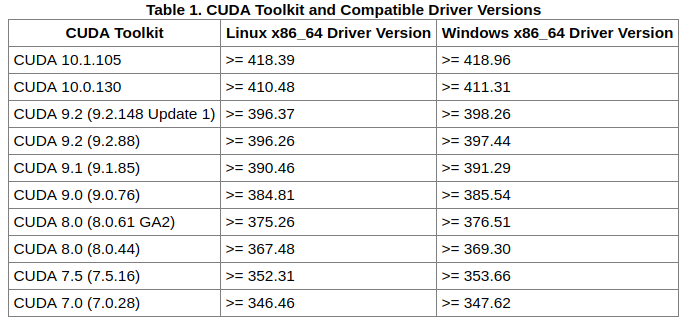
其中cuda driver version是指安装的nvidia驱动对应的版本, 我安装的是nvidia-418, 对应的cuda版本问10.1. cuda runtime version是指安装的cuda的版本.
CUDADeviceQuery(RuntimeAPI)version(CUDARTstaticlinking)
cudaGetDeviceCount returned 35
-> CUDA driver version is insufficient for CUDA runtime version
Result = FAIL
发生这种情况可能是你的nvidia driver的版本和cuda版本对不上.
有教程提到将Ubuntu中intel的集成显卡切换到nvidia显卡,但我试过没用啊!在终端输入:
nvidia-settings
在左侧栏找到PRIME Profiles, 进入切换即可。如果没有这一栏,则:
prime-select nvidia
cudaGetDeviceCount returned 30
-> unknown error
[deviceQuery] test results...
FAILED
目测需要重新安装。
NVIDIA cuDNN is a GPU-accelerated library of primitives for deep neural networks.
下载与cuda对应的deb包安装。
sudo dpkg -i libcudXX.deb
注: cudnn的安装顺序是: libcudnn->libcudnn-dev->libcudnn-doc
sudo apt-get --purge remove libcudnn*
注: cudnn的卸载顺序和安装顺序一样.
sudo cp libnvinfer.so.5 /usr/lib
sudo cp libnvonnxparser.so.0 /usr/lib
更改cmakelist.txt中的CUDA_ARCH值,将该值改为电脑显卡所对应的值:
find_package(CUDA)
if(CMAKE_CROSSCOMPILING)
if(NOT CUDA_ARCH)
message(FATAL_ERROR "Please define the CUDA_ARCH CMake variable")
endif()
else()
if (NOT DEFINED CUDA_CAPABILITY_VERSION_CHECKER)
set(CUDA_CAPABILITY_VERSION_CHECKER
"${CATKIN_DEVEL_PREFIX}/lib/capability_version_checker")
endif ()
execute_process(COMMAND ${CUDA_CAPABILITY_VERSION_CHECKER}
OUTPUT_VARIABLE CUDA_CAPABILITY_VERSION
OUTPUT_STRIP_TRAILING_WHITESPACE)
if ("${CUDA_CAPABILITY_VERSION}" MATCHES "^[1-9][0-9]+$")
set(CUDA_ARCH "sm_${CUDA_CAPABILITY_VERSION}")
else ()
set(CUDA_ARCH "sm_52") # 改这里
endif ()
endif()
由于我的显卡是GeForce 700,所有我需要将该值改为sm_30
Nvidia arch 型号对照
1392987390812 2019-05-31 16:06:09 5106 收藏 12
版权
-arch=sm_xx
Fermi (CUDA 3.2 until CUDA 8) (deprecated from CUDA 9):
SM20 or SM_20, compute_30 – Older cards such as GeForce 400, 500, 600, GT-630
Kepler (CUDA 5 and later):
SM30 or SM_30, compute_30 – Kepler architecture (generic – Tesla K40/K80, GeForce 700, GT-730)
Adds support for unified memory programming
SM35 or SM_35, compute_35 – More specific Tesla K40
Adds support for dynamic parallelism. Shows no real benefit over SM30 in my experience.
SM37 or SM_37, compute_37 – More specific Tesla K80
Adds a few more registers. Shows no real benefit over SM30 in my experience
Maxwell (CUDA 6 and later):
SM50 or SM_50, compute_50 – Tesla/Quadro M series
SM52 or SM_52, compute_52 – Quadro M6000 , GeForce 900, GTX-970, GTX-980, GTX Titan X
SM53 or SM_53, compute_53 – Tegra (Jetson) TX1 / Tegra X1
Pascal (CUDA 8 and later)
SM60 or SM_60, compute_60 – Quadro GP100, Tesla P100, DGX-1 (Generic Pascal)
SM61 or SM_61, compute_61 – GTX 1080, GTX 1070, GTX 1060, GTX 1050, GTX 1030, Titan Xp, Tesla P40, Tesla P4, Discrete GPU on the NVIDIA Drive PX2
SM62 or SM_62, compute_62 – Integrated GPU on the NVIDIA Drive PX2, Tegra (Jetson) TX2
Volta (CUDA 9 and later)
SM70 or SM_70, compute_70 – DGX-1 with Volta, Tesla V100, GTX 1180 (GV104), Titan V, Quadro GV100
SM72 or SM_72, compute_72 – Jetson AGX Xavier
Turing (CUDA 10 and later)
SM75 or SM_75, compute_75 – GTX Turing – GTX 1660 Ti, RTX 2060, RTX 2070, RTX 2080, Titan RTX, Quadro RTX 4000, Quadro RTX 5000, Quadro RTX 6000, Quadro RTX 8000
标签:epo driver x86_64 rem space key erro 返回 gre
原文地址:https://www.cnblogs.com/ChrisCoder/p/14924171.html