标签:demo 添加 ble rop efault only 说明 secret jvm
基于docker 运行
docker run -it -p 8080:8080 datamechanics/spark:jvm-only-3.1-latest sh
// 启动master
/opt/spark/sbin/start-master.sh
// 启动worker
./start-worker.sh spark://bbc0225c7aee:7077
效果 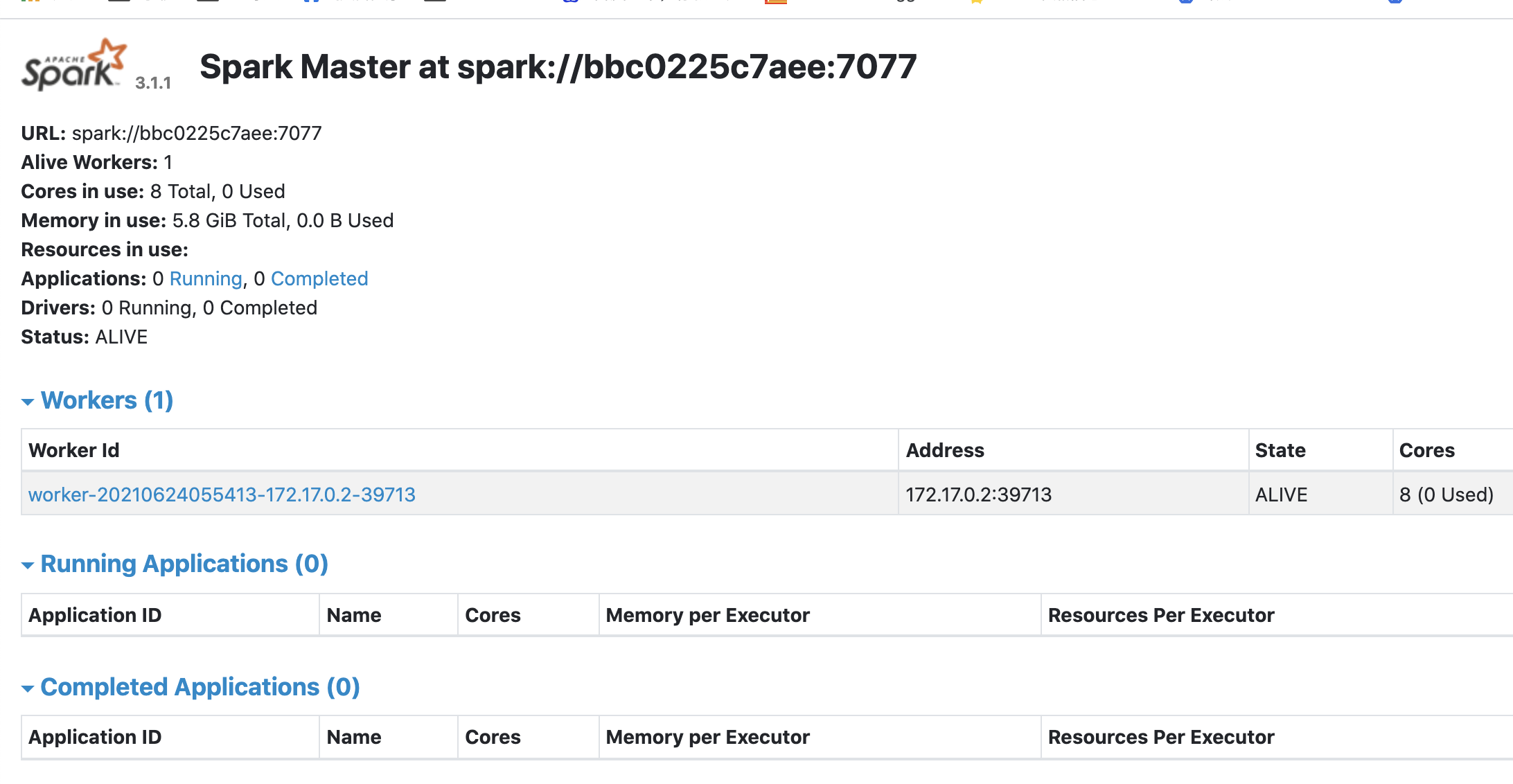
很简单,也是基于容器部署的
./spark-shell \
--packages io.delta:delta-core_2.12:1.0.0,org.apache.hadoop:hadoop-aws:3.2.0 \
--conf "spark.hadoop.fs.s3a.access.key=<accesskey>" \
--conf "spark.hadoop.fs.s3a.secret.key=<accesssecret>" \
--conf "spark.hadoop.fs.s3a.endpoint=endpoint" \
--conf "spark.sql.extensions=io.delta.sql.DeltaSparkSessionExtension" \
--conf "spark.databricks.delta.retentionDurationCheck.enabled=false \
--conf "spark.sql.catalog.spark_catalog=org.apache.spark.sql.delta.catalog.DeltaCatalog"
spark.range(50000000).write.format("delta").save("s3a://delta-lake/firstdemo")
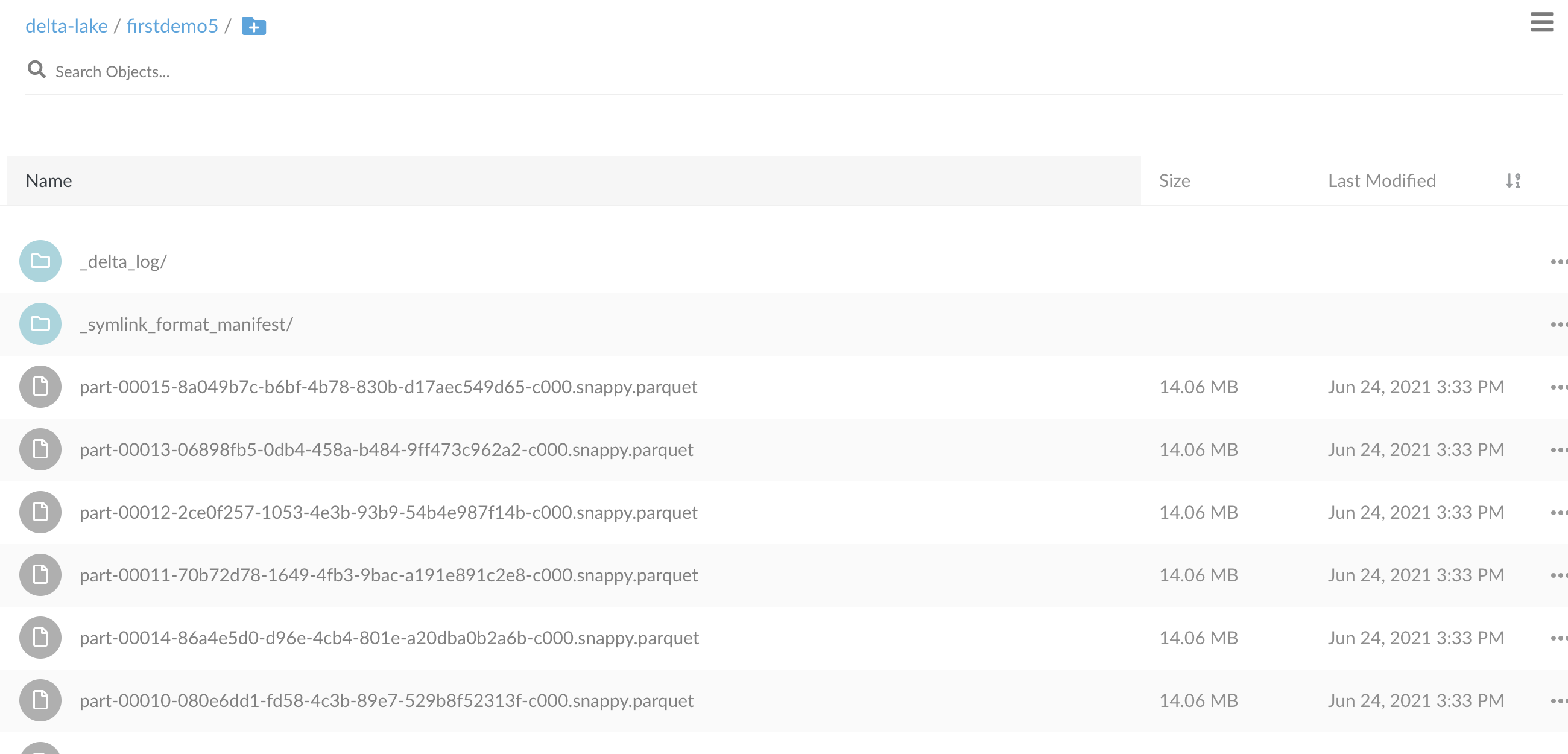
添加s3 data lake 数据源 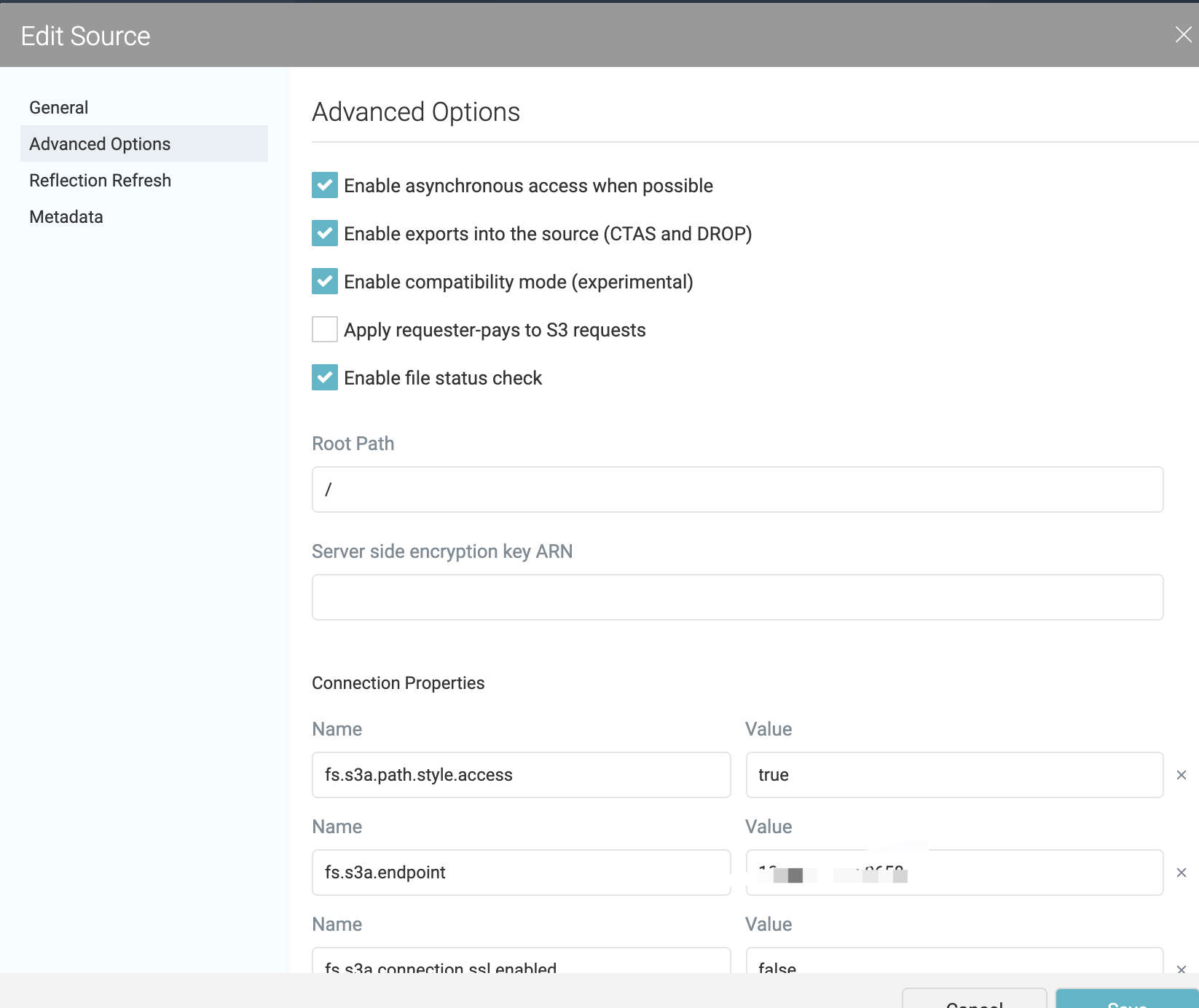
dremio 可以自动发现delta lake 的数据格式,但是需要开启,默认16.1 直接开启了

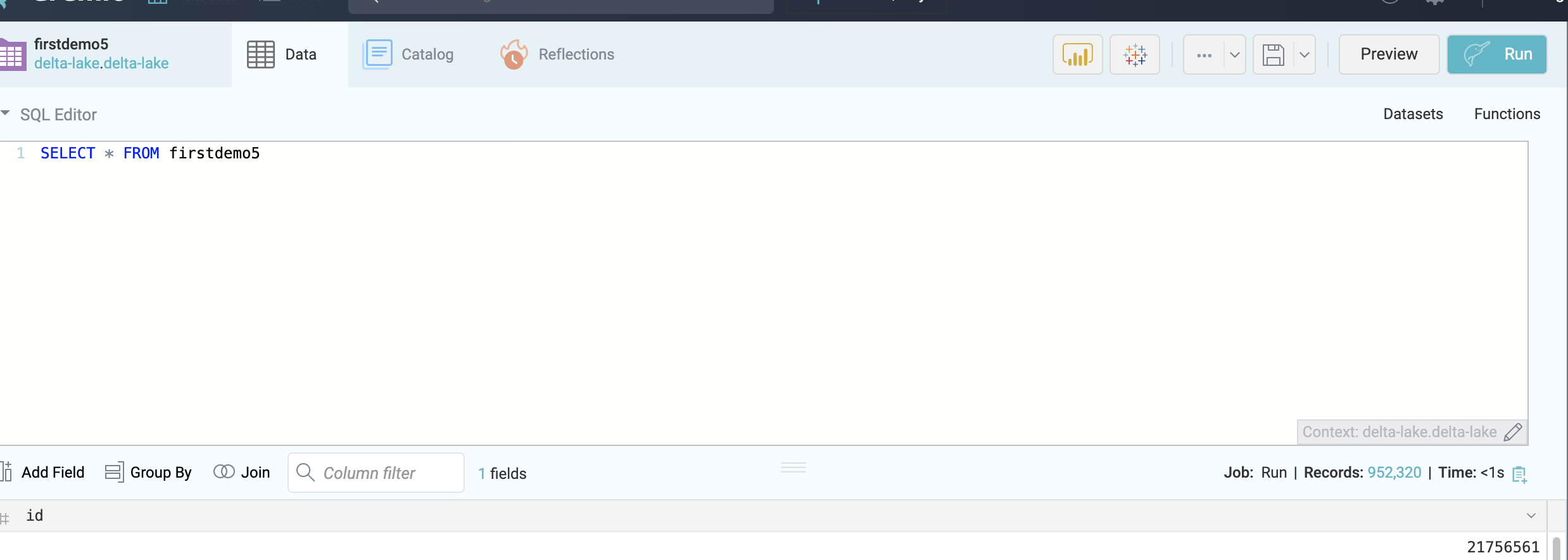
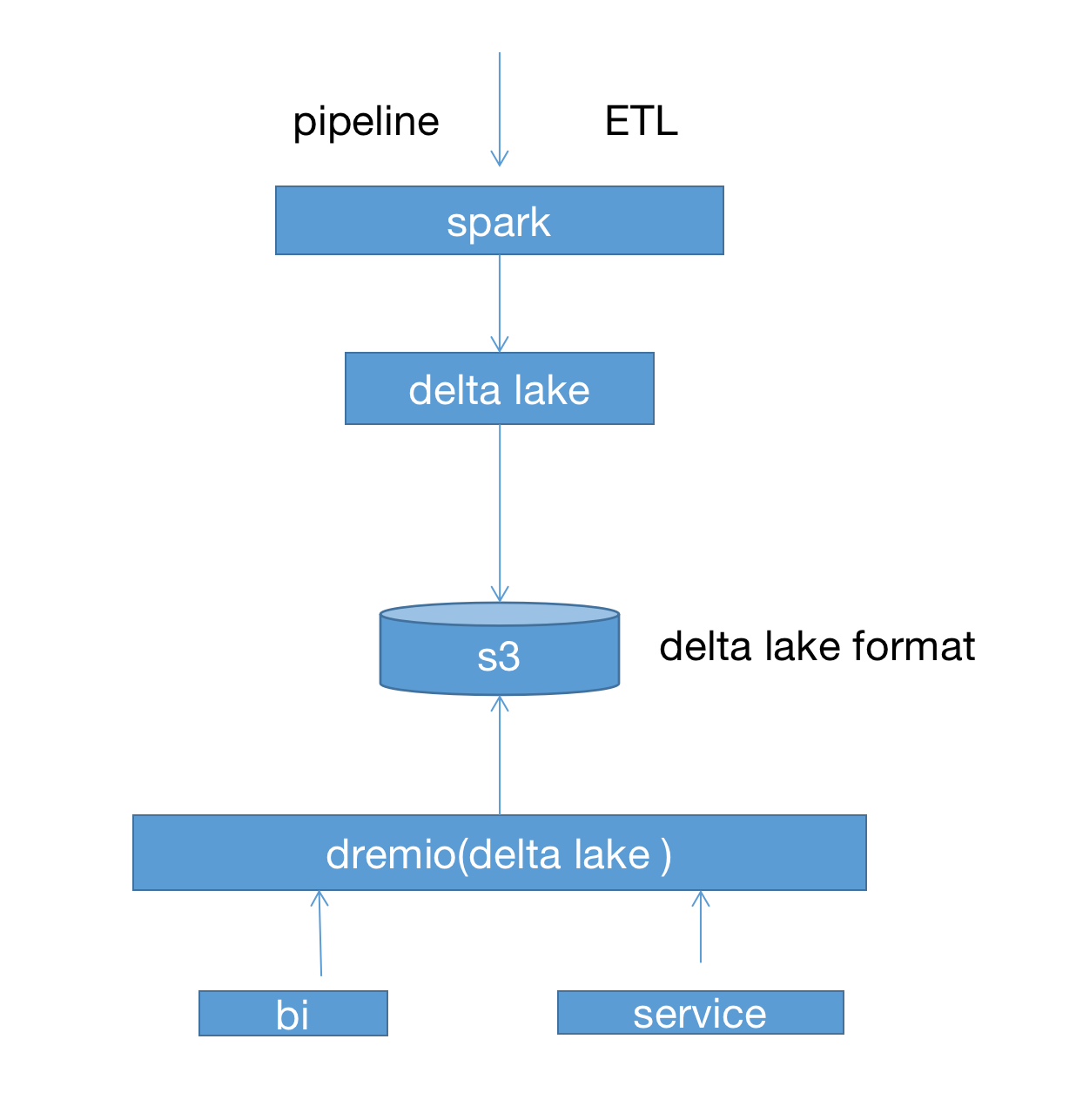
以上只是简单的将各个组件集成在一起,基于delta lake + minio+ dremio 的数据分析模式也是一个很不错的选择,可以加速我们的数据查询处理
dremio 的能力是很强大的,我们可以利用反射能力方便的进行数据加速处理,基于dremio 提供的sql 能力可以方便的进行数据分析,快速的利用数据
湖的能力加速业务处理,同时delta lake 自身也有一些问题(小文件过多以及vacuum,这些问题也都可以很好的解决,官方提供了相关的管理api)
https://docs.delta.io/latest/quick-start.html#language-scala
https://www.vertica.com/kb/Vertica_DeltaLake_Technical_Exploration/Content/Partner/Vertica_DeltaLake_Technical_Exploration.htm
https://databricks.com/blog/2019/04/17/running-peta-scale-spark-jobs-on-object-storage-using-s3-select.html
https://www.datamechanics.co/
标签:demo 添加 ble rop efault only 说明 secret jvm
原文地址:https://www.cnblogs.com/rongfengliang/p/14928505.html