标签:解法 check als 需要 数据 mat 扫描 lse 函数
题目内容:给定一个字符串\(s\),求其中最长的回文子串的长度。
数据范围:\(s\)的长度不超过\(2*10^5\)
时间限制:\(1000ms\)
传统的动态规划的做法时间复杂度\(O(n^2)\),会\(TLE\).此处不多作介绍.
以下给出两种优化的做法:
解法一:
1.当回文子串的长度为奇数时:扫描数组,枚举每一个\(s[i]\),并以之作为回文子串的中心,向两边二分搜索求取从该中心出发向两边扩散的最大长度\(L\), 此时回文子串的长度为\(2*L+1\)。
2.当回文子串的长度为偶数时:中间有两个相邻的\(s[i]\)、\(s[i+1]\),它们两个相等,可以把它们看成是一个新的中心,向左右两个方向扩散求最大扩散长度\(L\),此时回文子串长度为\(2*L+2\)。
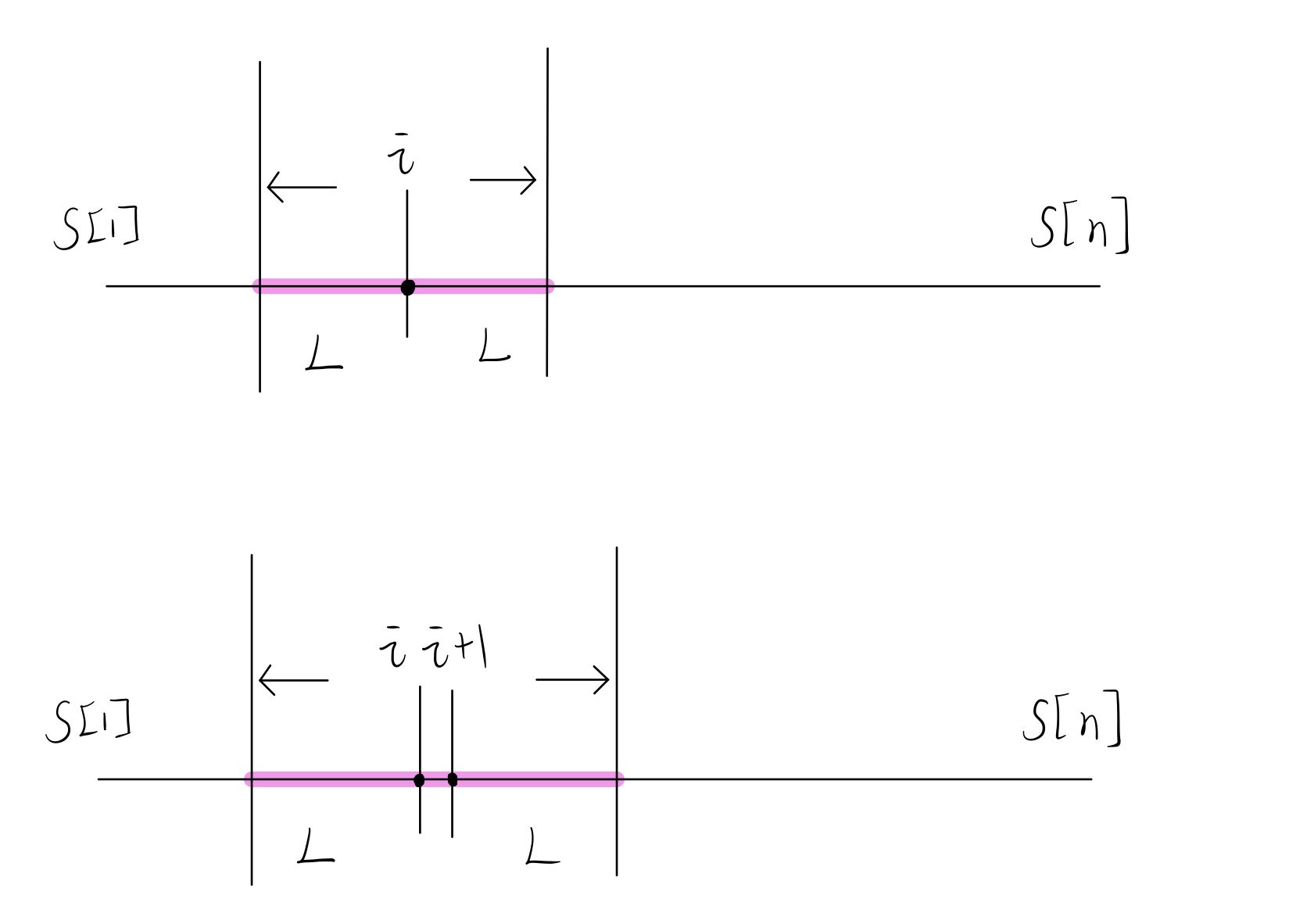
进行二分搜索时,对于\(1\),\(L\)的分布范围是\([0,min(i - 1, n - i)]\);对于\(2\),\(L\)的分布范围是\([0, min(n - i - 1,i - 1)]\).
代码:
#include<bits/stdc++.h>
using namespace std;
const int N = 2e5+2;
char s[N];
bool check(int x, int medi, int kind)//x为回文子串的中心,kind为二分判断的类型。
{
if(kind == 0)//对应第一种
{
for(int k = 1;k <= medi; k++)
{
if(s[x - k] != s[x + k])return false;
}
return true;
}
if(kind == 1)//对应第二种
{
for(int k = 1;k <= medi; k++)
{
if(s[x - k] != s[x + 1 + k])return false;
}
return true;
}
}
int main()
{
cin>>(s + 1);
int n = strlen(s+1);
int ans = 1;
//第一种情况枚举中心:跳过了s[1]以及s[n],因为以它们为中心时L均为0
for(int i = 2;i <= n - 1; i++)
{
int l = 0, r = min(n - i, i - 1);
while(l < r)
{
int medi = (l + r + 1)>>1;
if(check(i, medi, 0))l = medi;
else r = medi - 1;
}
ans = max(ans, 2*l + 1);
}
for(int i = 1;i <= n - 1; i++)
{
if(s[i] == s[i + 1])
{
int l = 0, r = min(n - i - 1, i - 1);
while(l < r)
{
int medi = (l + r + 1)>>1;
if(check(i, medi, 1))l = medi;
else r = medi - 1;
}
ans = max(ans, 2*l + 2);
}
}
cout<<ans;
return 0;
}
解法二
解法一在输入字符串只有一种字母且长度很大时会退化到\(O(n^2)\)(当然数据水一点一般不会出现这种情况),它最大的不足在于每一次二分进行判断(调用\(check\)函数时)代价都是线性的。
解法二跟解法一的思路差不多,是解法一的强化版。只不过借助于哈希,我们将每一次\(check\)的代价降低为常数时间。
哈希的目的是将任意一段区间上的字符串唯一映射到一个值(这里用\(unsigned\) \(long\) \(long\)作为映射值)
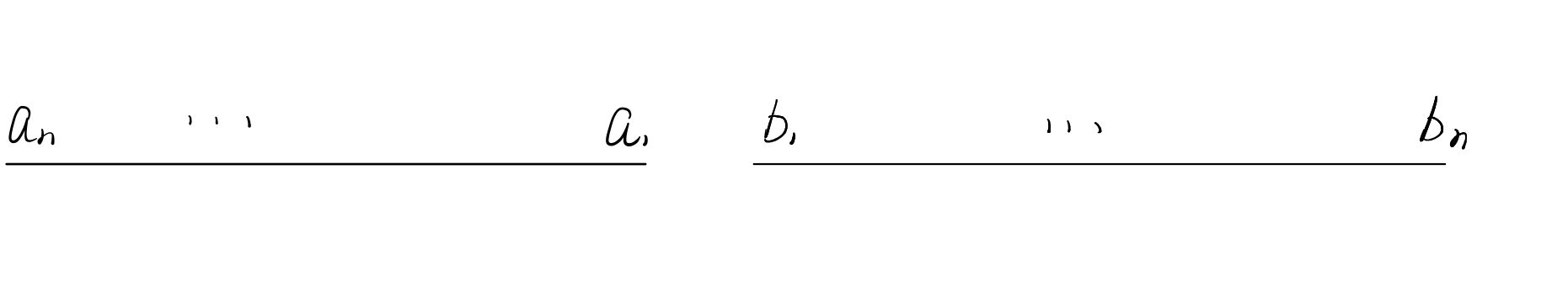
类比某个\(base\)的进制数,上图左侧区间的哈希值记作:
\(a_{n}*base^{n-1}+a_{n-1}*base^{n-2}+...+a_{1}\)
右侧区间哈希值记作:
\(b_{n}*base^{n-1}+b_{n-1}*base^{n-2}+...+b_{1}\)
那么我们只需要直接判断这两个哈希值是否相等就可以知道这两个区间上的字符串是否为镜像对称。
记\(f_{i} = f_{i-1}*base + s_{i} -‘a‘ +1\)
(\(s_{i}-‘a‘+1\)将每一个字母与字母\(a\)进行参照转化为整数)
\(g_{i} = g_{i+1}*base + s_{i} - ‘a‘+1\)
\(P_{i} = base^{i}\)
那么左侧区间类型的原字符串数组\([i,j]\)对应的哈希值为:\(f_{j} - f_{i-1}*P_{j - i + 1}\)
右侧区间类型的原字符串数组\([i,j]\)对应的哈希值为:\(g_{i} - g_{j+1}*P_{j - i + 1}\)
这两个式子的推导:
\(g_{n} = s_{n}-‘a‘+1\)
\(g_{n-1} = (s_{n}-‘a‘+1)*base+s_{n-1}-‘a‘+1\)
...
\(g_{j+1} = (s_{n}-‘a‘+1)*base^{n-j-1}+...s_{j+1}-‘a‘+1\)
...
\(g_{i} = (s_{n}-‘a‘+1)*base^{n-i}+...(s_{j+1}-‘a‘+1)*base^{j+1-i}+...+s_{i}-‘a‘+1\)
区间\([i,j]\)哈希值为\(g_{i}-g_{j+1}*base^{j+1-i}=g_{i} - g_{j+1}*P_{j - i + 1}\)
\(f\)的式子也是一样的,这里省去推导。
#include<bits/stdc++.h>
using namespace std;
#define base 137
typedef unsigned long long int ull;
const int N = 200001;
char s[N];
ull f[N], g[N], P[N];
bool check(int l1, int l2, int l3, int l4)//分别为f对应于区间[l1,l2], g对应于区间[l3, l4]
{
ull t1 = f[l2] - f[l1 - 1]*P[l2 - l1 + 1];
ull t2 = g[l3] - g[l4 + 1]*P[l4 - l3 + 1];
return t1 == t2; //相等则为镜像对称
}
void init(int n)
{
P[0] = 1;
for(int i = 1;i <= n; i++)P[i] = P[i - 1]*base;
}
int main()
{
cin>>(s + 1);
int n = strlen(s + 1);
init(n);//初始化P数组
for(int i = 1;i <= n; i++)
f[i] = f[i - 1]*base + s[i] - ‘a‘ + 1;
for(int i = n; i >= 1; i--)
g[i] = g[i + 1]*base + s[i] - ‘a‘ + 1;
int ans = 0;
for(int i = 1;i <= n; i++)
{
//区间长度为奇数:
int l = 0, r = min(n - i, i - 1);
while(l < r)
{
int medi = (l + r + 1)>>1;
if(check(i-medi, i - 1, i + 1, i + medi))l = medi;
else r = medi - 1;
}
ans = max(ans, l*2 + 1);
//区间长度为偶数,将s[i]与s[i+1]看成新的中心,但是二者必须相等
if(s[i] == s[i + 1])
{
l = 0,r = min(n - i - 1, i - 1);
while(l < r)
{
int medi = (l + r + 1)>>1;
if(check(i - medi,i - 1, i + 2, i + medi + 1))l = medi;
else r = medi - 1;
}
ans = max(ans, 2*l + 2);
}
}
cout<<ans;
return 0;
}
解法二虽然能够确保任何情况下时间复杂度为\(O(nlogn)\),由于解法一,但是也付出了更大的空间代价。
标签:解法 check als 需要 数据 mat 扫描 lse 函数
原文地址:https://www.cnblogs.com/zxq0058/p/14932978.html