标签:二分 通信 ice net 一致性 -- http href 文件组
关键点
此处可以结合本系列上篇文章kafka大白话入门,对Kafka先有个感性认识,再来理解几个概念。
此处简单的前情提要:
假设本身有A和B要通信,他俩直接聊就行了,这时候比如就形成一条通信链路;
如果左右各有3人要通信呢,那就会变成3*3=9条通信链路,
当多对多的情况下就会进而演变为N*N条通信线路,极度复杂冗余,所以抽出来一层,用来接收和转发,这个就是消息队列(kafka)。
Notice:
概念
补充
总结:
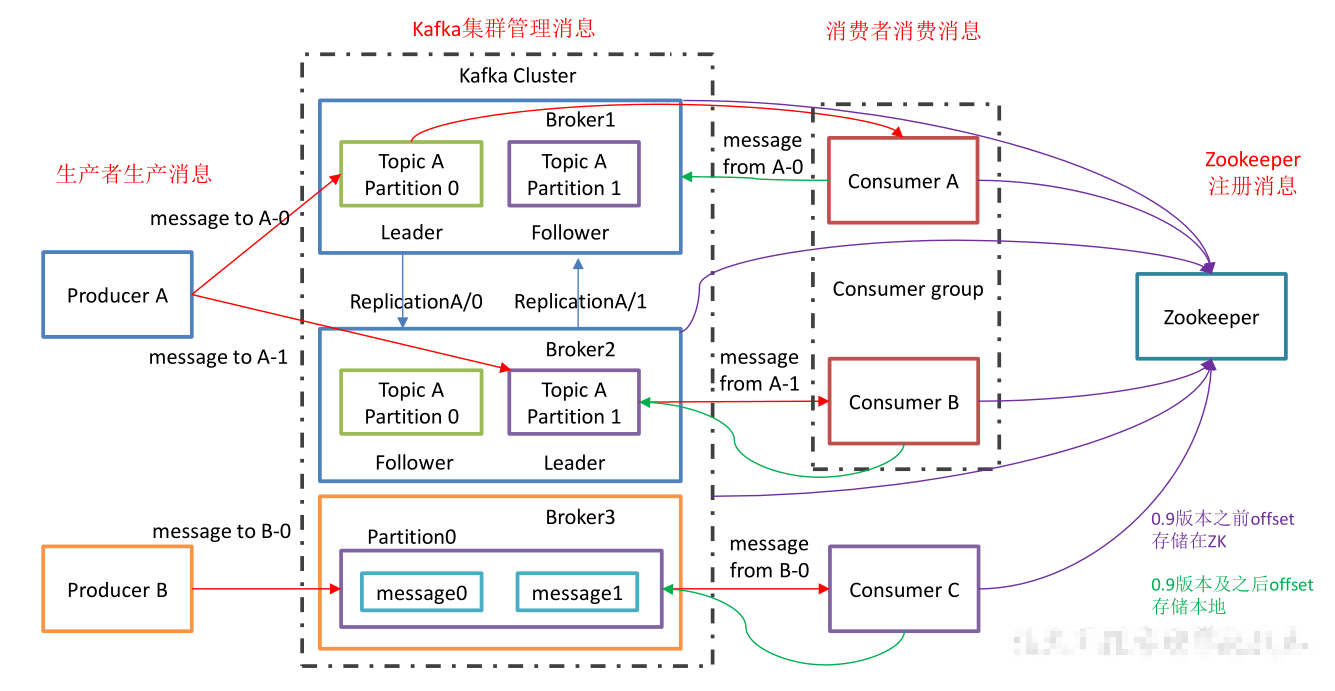
消息是分主题的,然后为了扩展性,每个主题又有许多分区(分片和索引机制),这些分片可以跨机存在
每个分区内部又是有序的队列,索引从0.1.2..开始这种的
注意副本的概念:副本是针对分区的,每个分区都有若干副本(一leader和多follower)
副本的leader和follower又有崩溃后选主的策略,然后对应一些ISR的概念
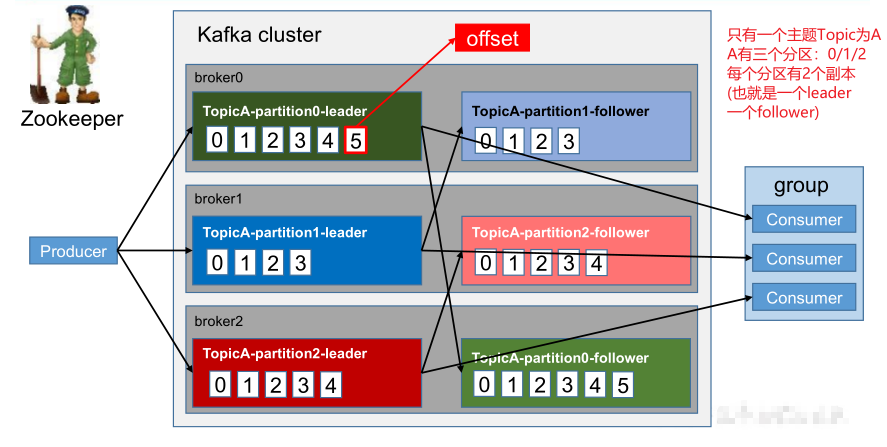
简单描述下:
上图中Kafka集群中有3个broker,每个broker放了两个分区;
整体只有一个主题Topic为A;A有三个分区:0/1/2;
每个分区有2个副本(也就是一个leader一个follower);
Kafka中的消息是以topic来分类的,生产者和消费者都是面向topic的,不过topic是个逻辑上的概念,而partition是物理上的概念,所以存盘的最小粒度单位是分区。
每个partition都对应于一个log文件,log保存的就是生产者生产的数据,生产者的消息会不断追加到log文件,且每个消息都会有自己的offset。
每个partition中的消息是以log的形式存在,但是Kafka的消息最底层用的是LogSegment(日志段),因为单个log文件大小上限为1G,超过后会生成新的log文件。也就是说一个partition可能对应多个log文件。
Kafka的一个日志段包括一个消息日志文件和若干索引文件组成,即一个.log和.index文件
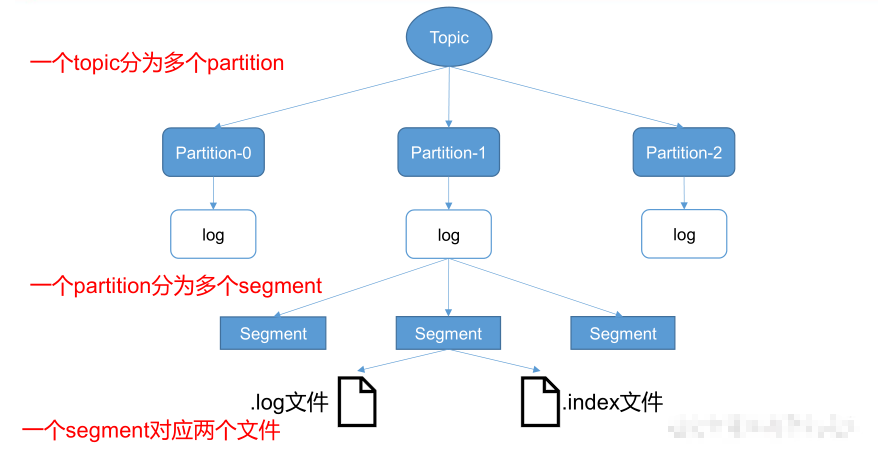
由于生产者生产的消息会不断追加到 log 文件末尾,为防止 log 文件过大导致数据定位效率低下,Kafka 采取了 分片和 索引机制,将每个 partition 分为多个 segment。每个 segment对应两个文件 ——“.index”文件和“.log”文件。这些文件位于一个文件夹下,该文件夹的命名规则为:topic 名称+分区序号。例如,first 这个 topic 有三个分区,则其对应的文件夹为 first-0,first-1,first-2。
00000000000000000000.index
00000000000000000000.log
00000000000000170410.index
00000000000000170410.log
00000000000000239430.index
00000000000000239430.log
partition是以文件夹的形式存储在具体Broker本机上
数据保存为log,log有分片和索引机制,分为很多segment,
保存形式为:000.index--000.log,然后超过1g以后生成新的segment。
那么新的segment怎么命名呢?命名为本segment中最小的消息id,这样在查数据的时候就可以利用二分了。
xx.index文件存offset--(对应log中的起始位置和大小),比如xx.index中存【3--(756,1000)】,那么就会去xx.log中读取756-1756这段的数据。
因此,虽然kafka是磁盘存储,但是读写速度还是很快的。
磁盘的顺序读写比乱序内存读要快吗?
index 和 log 文件以当前 segment 的第一条消息的 offset 命名。
index文件和log文件详解:
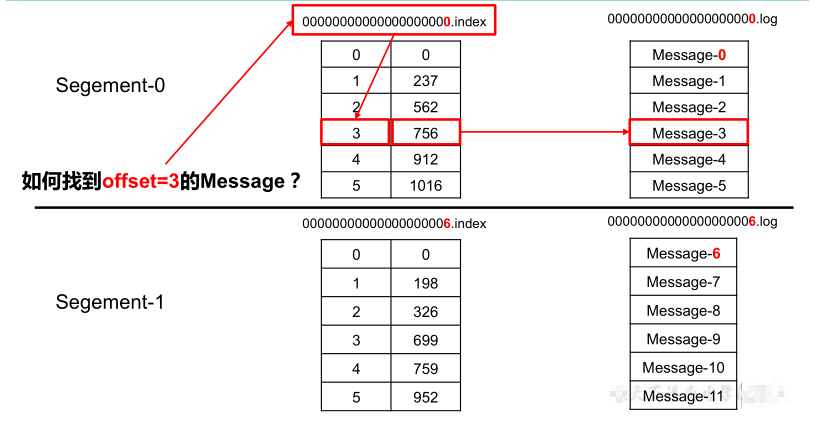
".index"文件存储大量的索引信息,".log"文件存储大量的数据,索引文件中的元数据指向对应数据文件中 message 的物理偏移地址。
因为索引的存在,所以查数据的时候使用了二分,故读写速度比较快。
kafka的message是以topic为基本单位,不同topic之间是相互独立的。每个topic又可分为几个不同的partition,每个partition存储一部的分message。topic与partition的关系如下:
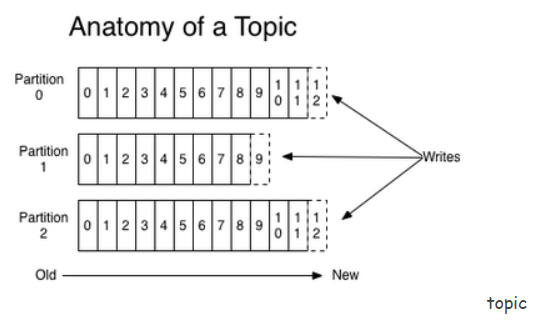
其中,partition是以文件夹的形式存储在具体Broker本机上。
参考:Kafka之数据存储
标签:二分 通信 ice net 一致性 -- http href 文件组
原文地址:https://www.cnblogs.com/xyqlrjm/p/14938673.html