标签:lazy cpu 寄存器 转换 不清楚 语言 double get int

Pixiv:Csyady
任何的数据都存在两个基本问题(这应该是在数据结构里学的)
①如何存储数据
②数据有多大
我们之前使用dw来定义数据,dw其实就是define word定义一个字
还有其他的定义方式,这是基于不同尺寸来定义的
db(define byte)用来定义字节
db 30h,31h,32h
dd(define double word)用来定义双字
dd 12345678h
df用来定义三字
dq用来定义四字
dt用来定义五字
依据这些我们可以较方便地在数据段、栈段来定义数据
但是还存在一个问题,如果我要初始化1000个字节,总不可能写1000次0吧,因此存在另外一个语法能快速帮助我们定义数据
dup语法专门用来重复定义
定义用的伪指令 次数 dup (数据)
db 3 dup (0)
/*db定义3次0*/
db 4 dup (0,1,2)
/*db定义4次0,1,2也就是定义12个字节*/
dt 50 dup (0,0)
/*同理是定义500字*/
依据如此丰富的定义方法和dup可以很高效地定义数据
不过需要注意这是直接定义在内存上的
就汇编里有三种存储方式
(1)立即数idata
(2)寄存器reg
(3)内存SA:EA
立即数对标C语言的常数
寄存器和内存你可以认为都是变量
在C语言里有个关键词是register作用是将变量定义为寄存器变量
现在我们学了汇编,知道寄存器的基本作用是存储数据,但同时我们也知道寄存器如同多才多艺的人,具有很多功能。
寄存器首先在速度上会比内存要快,寄存器可以直接访问CPU,而内存需要先通过地址总线来寻找位置
但由于寄存器数量太少了,因此我们还是多使用内存来存储数据
汇编里也存在ASCII码,因此我们可以用来定义字符(串)
一个字符便占1字节
比如
db ‘a‘
db ‘B‘
db ‘Assembly‘
/*不推荐使用其他类型来定义
很可能会出bug*/
实现这个正常我们会使用if语句来判断字符类型然后在转换,但目前为止我们并没有学习汇编的IF语句,汇编的IF要复杂很多,在之后会遇到,但现在我们要怎么进行大小写转换呢?
我们先对ASCII码进行转换,转成16进制、2进制来寻求答案
| 字符 | ASCII码 | 16进制 | 2进制 |
|---|---|---|---|
| A | 65 | 41 | 0100 0001 |
| B | 66 | 42 | 0100 0010 |
| C | 67 | 43 | 0100 0011 |
| ... | ... | ... | ... |
| a | 97 | 61 | 0110 0001 |
| b | 98 | 62 | 0110 0010 |
| c | 99 | 63 | 0110 0011 |
| ... | ... | ... | ... |
当我们列出所有大小写字母不同码值后,我们便能发现一个最为明显的规律
因此如果我们只要能修改二进制码中的第5位即可
而且在汇编里确实存在这种操作(在C里也有)
那就是逻辑运算and和or
首先在C语言里我们可以这样操作
a = a && 11011111b;
//a转为大写
b = b || 00100000b;
//b转为小写
这里a操作具有这样一个功能
and:0的位置设为0
or :1的位置设为1
傻子采用if转大小写(bushi)
在汇编里为下述代码
and al,11011111b
/*转大写*/
or dl,00100000b
/*转小写*/
这四个寄存器尤为特殊,都具有和bx寄存器一样的功能,可以作为偏移地址的参数,比如
mov ax,ds:[bx]
mov bx,ds:[bp]
mov cx,ds:[si]
mov dx,ds:[di]
同理我们可以进行加减
mov cx,ds:[0+bx]
mov ax,ds:[2+bx]
mov dx,ds:[4+si+bp]
仅仅依靠这种灵活定位偏移地址的方式,我们可以玩出很多花
但语法并非那么宽松,可以说是刻意指定好的
bx、bp为一块,si、di为一块
| 寻址方式 | 含义 | 语法糖 |
|---|---|---|
| 直接寻址 | 用idata、bx、bp、si或di来 | 无 |
| 相对寻址 | 用bx、bp、si或di与idata相加得到 表示为[bx+idata]、[si+idata]等 |
[bx].idata idata[bx] 或[bx] [idata] |
| 变基址寻址 | 用bx、bp与si、di相加组合而成 表示为[bx+di]、[bp+si]等 但注意不可以表示为[bx+bp]或[si+di] |
[bx] [si] |
| 相对变基址寻址 | 在变基址寻址的基础加上idata 表示为[bx+di+idata]等 |
idata[bx] [si] 或[bx].idata[si] |
像下面代码能成立吗?
mov ds:[bx],12
或许能成立,但mov操作将12赋值给ds:[bx],但ds:[bx]占几个字节?
寄存器al就是一字节,ax就是一字,这很明确
但对于某一内存初始地址这并不清楚这块内存多大,我们需要使用X ptr来告诉编译器我们将ds:[bx]当作了几个字节
X可以为字节byte、字word、双字dword、三字fword、四字qword、五字tbyte
不过在16位实模式上你基本没机会使用dword以上的
基本上会报错,就不要想什么tbyte ptr之类的
mov word ptr ds:[bx],12
还有一种情况,就是指令本身指定了传入数据大小
因为只有不确定参数的情况下才需要使用X ptr语法
比如push和pop,这两个指令明确表示是以字来传输的
push ds:[bx]
pop ds:[bp]
上面看似不清楚,但指令本身指定了是传输1字
比如单纯用1个字节或1个字可以当作一个变量
但同时我们依据灵活定位偏移地址的方式,我们可以构造出数组、多维数组(至多两维)、结构体这些基本的数据类型
内存上当然看不出什么,但逻辑上我们依据构造好了,而且x86汇编语言也存在着一些语法糖辅助我们理解
这个比较简单,比如我们定义09为字符串a,1019为字符串b
逻辑上我们划分好了,然后我们在数据段定义数据
data segment
db ‘0123456789‘,‘9876543210‘
data ends
然后我们尝试获取数据
code segment
start: mov ax,data
mov ds,ax
mov bx,0
mov si,0100h
mov di,0200h
/*我们将两个字符串
分别搬到ds:0100和ds:0200处*/
mov cx,10
loop1:
mov al,ds:[bx]
mov ds:[si],al
mov al,ds:[1*10+bx]
mov ds:[di],al
/*注意没有这种语法
mov byte ptr ds:[si],ds:[bx]
因此我使用al暂时存储*/
inc bx
inc si
inc di
loop loop1
mov ax,4c00h
int 21h
code ends
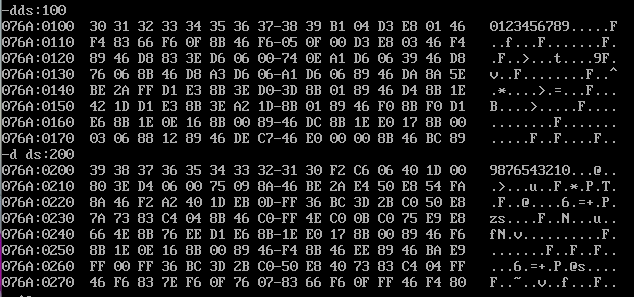
我们可以看到确实成功了
在刚才的程序其实我已经隐含地表达了如何构造二维数组
中间有行代码mov al,ds:[1*10+bx]
我这里表达为1*10其实就是二维数组的一种表达
如果有15个长度10的字符串我可以表示为
mov si,0
...
mov al,ds:[si*10+bx]
...
inc si
当然这在语法上是不允许,我们进行改良
mov si,0
...
mov al,ds:[si+bx]
...
add si,10
同时我们可以使用语法糖加强语意
mov si,0
...
mov al,ds:[si][bx]
...
add si,10
如果我们在逻辑上定义了多个二维数组我们可以使用语法糖idata[bx][si]
如果有多个一维数组我们使用语法糖idata[bx]
结构体比二维数组复杂很多,我们先用C语言描述一个结构体,考虑用汇编实现结构体
struct {
char a;
char b[2];
char c;
};
我们用语法糖[bx].idata
mov bx,0
...
mov al,ds:[bx].0
...
mov al,ds:[bx].1
...
mov al,ds:[bx].3
...
add bx,4
mul ax,2
除法比较复杂,首先div是整除指令
完成一个除法,需要被除数、除数,而结果为商、余数
除数分为8位和16位
被除数为16位且存储在ax寄存器内
除数为8位由寄存器或者内存存放
比如
mov ax,17
mov dl,4
div dl
/*注意不能使用idata作为div的参数*/
那么结果分别为4和1,而余数被存储于ah,商存储于al
被除数高16位存储在DX,低16位存储在AX
除数必须为16位
余数最后存储在DX,商存储在AX
mov dx,0001h
mov ax,86a1h
/*这个被除数也就是
dx*10000h+ax=100001h*/
mov bx,0100h
div bx
我们调用可以看到最后结果AX=0186h,DX=00A1h
(注:使用除法很有可能会出错,若出错你将不得不重启系统)
标签:lazy cpu 寄存器 转换 不清楚 语言 double get int
原文地址:https://www.cnblogs.com/AlienfronNova/p/14939600.html