标签:cte 磁盘 att lte 异步 启动 设置 cat 动作
?简介: 我们在几年前决定引入 MQ 时,市场上已经有不少成熟的解决方案,比如 RabbitMQ , ActiveMQ,NSQ,Kafka 等。考虑到稳定性、维护成本、公司技术栈等因素,我们选择了 RocketMQ。

![]() ?
?
?
?
我们在几年前决定引入 MQ 时,市场上已经有不少成熟的解决方案,比如 RabbitMQ , ActiveMQ,NSQ,Kafka 等。考虑到稳定性、维护成本、公司技术栈等因素,我们选择了 RocketMQ :
?
?
?
?
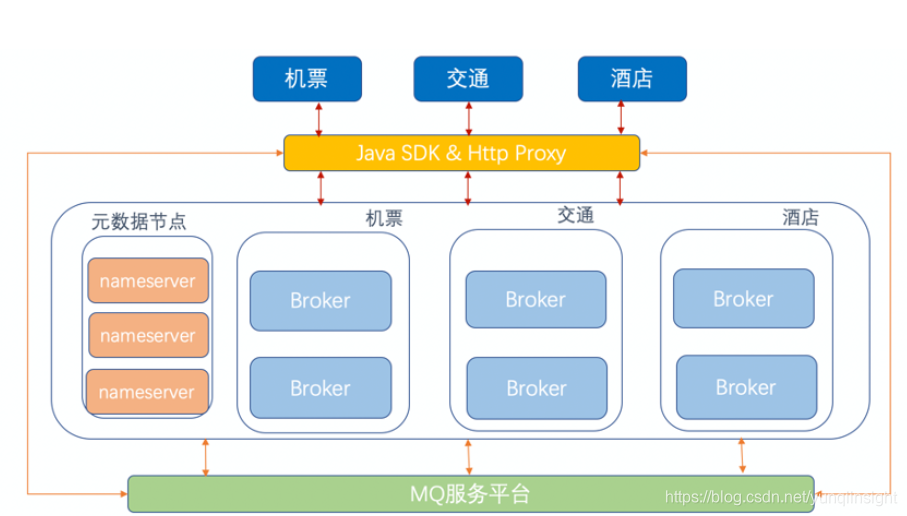
下图是 MQ 接入框架图
?
由于公司技术栈原因,client sdk 我们提供了 java sdk ;对于其他语言,收敛到 http proxy ,屏蔽语言细节,节约维护成本。按照各大业务线,对后端存储节点进行了隔离,相互不影响。
?
![]() ??
??
?
之前单机房出现过网络故障,对业务影响较大。为保障业务高可用,同城双中心改造提上了日程。
?
?
?
?
做双中心之前,对同城双中心方案作了些调研,主要有冷(热)备份、双活两种。(当时社区 Dledger 版本还没出现,Dledger 版本完全可做为双中心的一种可选方案。)
?
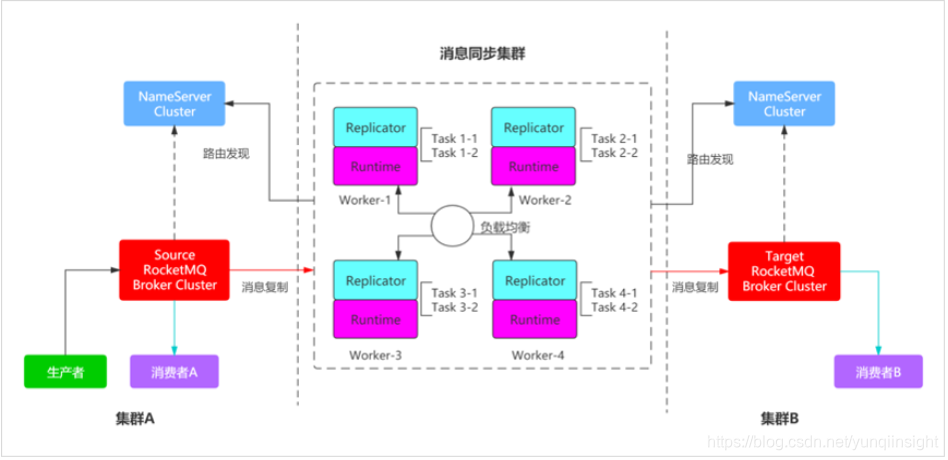
1)同城冷(热)备份
?
两个独立的 MQ 集群, 用户流量写到一个主集群,数据实时同步到备用集群,社区有成熟的 RocketMQ Replicator 方案,需要定期同步元数据,比如主题,消费组,消费进度等。
?
![]() ?
?
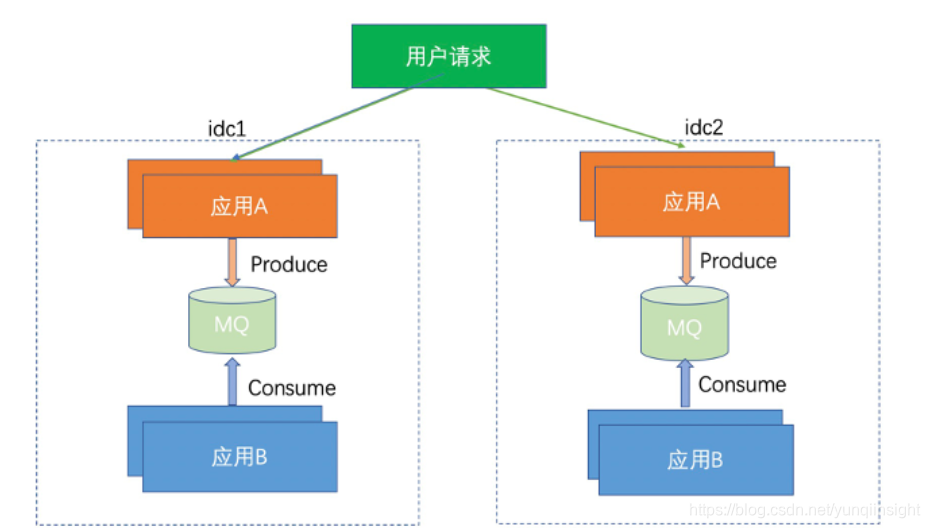
2)同城双活
?
两个独立 MQ 集群,用户流量写到各自机房的 MQ 集群,数据相互不同步。
?
平时业务写入各自机房的 MQ 集群,若一个机房挂了,可以将用户请求流量全部切到另一个机房,消息也会生产到另一个机房。
![]() ??
??
对于双活方案,需要解决 MQ 集群域名。
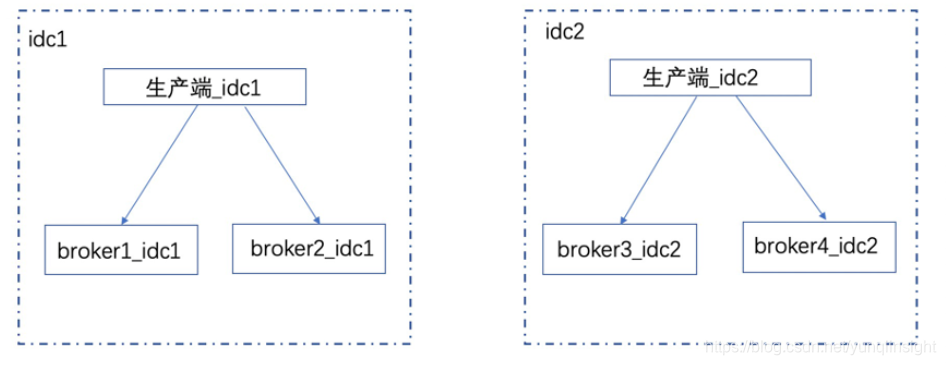
1)若两个集群用一个域名,域名可以动态解析到各自机房。此方式要求生产、消费必须在同一个机房。假如生产在 idc1 ,消费在 idc2 ,这样生产、消费各自连接一个集群,没法消费数据。
2)若一个集群一个域名,业务方改动较大,我们之前对外服务的集群是单中心部署的,业务方已经大量接入,此方案推广较困难。
为尽可能减少业务方改动,域名只能继续使用之前的域名,最终我们采用一个 Global MQ 集群,跨双机房,无论业务是单中心部署还是双中心部署都不影响;而且只要升级客户端即可,无需改动任何代码。
?
?
简单说,就是确定两件事:
如何判断自己在哪个 idc?
?
1) ip 查询
节点启动时可以获取自身 ip ,通过公司内部的组件查询所在的机房。
?
2)环境感知
需要与运维同学一起配合,在节点装机时,将自身的一些元数据,比如机房信息等写入本地配置文件,启动时直接读写配置文件即可。
我们采用了第二个方案,无组件依赖,配置文件中 logicIdcUK 的值为机房标志。
??
客户端节点如何识别在同一个机房的服务端节点?
?
![]() ?
?
客户端节点可以拿到服务端节点的 ip 以及 broker 名称的,因此:
?
相对于前两者,实现起来略复杂,改动了协议层, 我们采用了第二种与第三种结合的方式。
?
基于上述分析,就近生产思路很清晰,默认优先本机房就近生产;
?
若本机房的服务节点不可用,可以尝试扩机房生产,业务可以根据实际需要具体配置。
![]() ??
??
?
优先本机房消费,默认情况下又要保证所有消息能被消费。
?
队列分配算法采用按机房分配队列
?
?
伪代码如下:
?
Map<String, Set> mqs = classifyMQByIdc(mqAll);
Map<String, Set> cids = classifyCidByIdc(cidAll);
Set<> result = new HashSet<>;
for(element in mqs){
result.add(allocateMQAveragely(element, cids, cid)); //cid为当前客户端
}?
消费场景主要是消费端单边部署与双边部署。
?
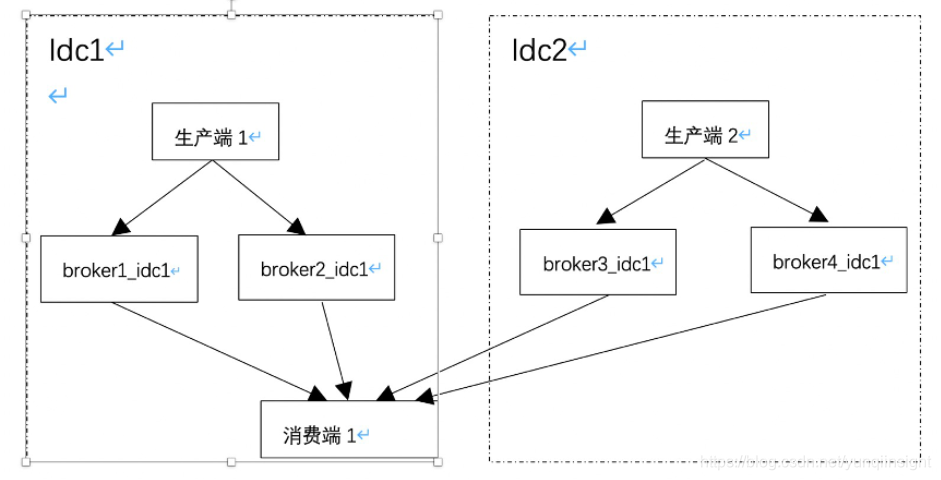
单边部署时,消费端默认会拉取每个机房的所有消息。
![]() ?
?
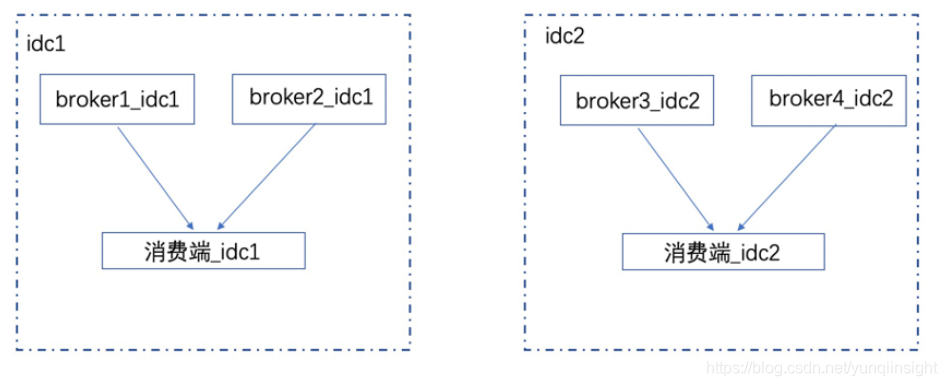
双边部署时,消费端只会消费自己所在机房的消息,要注意每个机房的实际生产量与消费端的数量,防止出现某一个机房消费端过少。
![]() ??
??
?
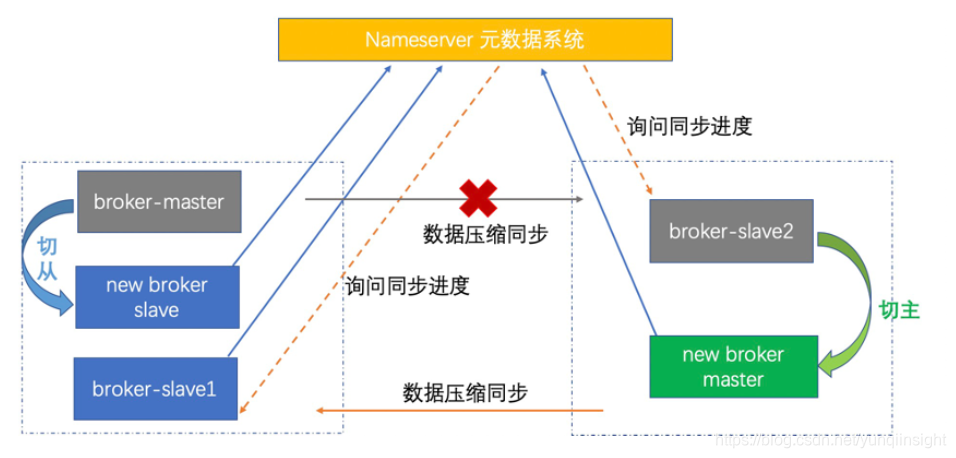
一主两从,一主一从在一机房,一从在另一机房;某一从同步完消息,消息即发送成功。
?
消息生产跨机房;未消费消息在另一机房继续被消费。
?
在某一组 broker 主节点出现故障时,为保障整个集群的可用性,需要在 slave 中选主并切换。要做到这一点,首先得有个broker 主故障的仲裁系统,即 nameserver(以下简称 ns )元数据系统(类似于 redis 中的哨兵)。
?
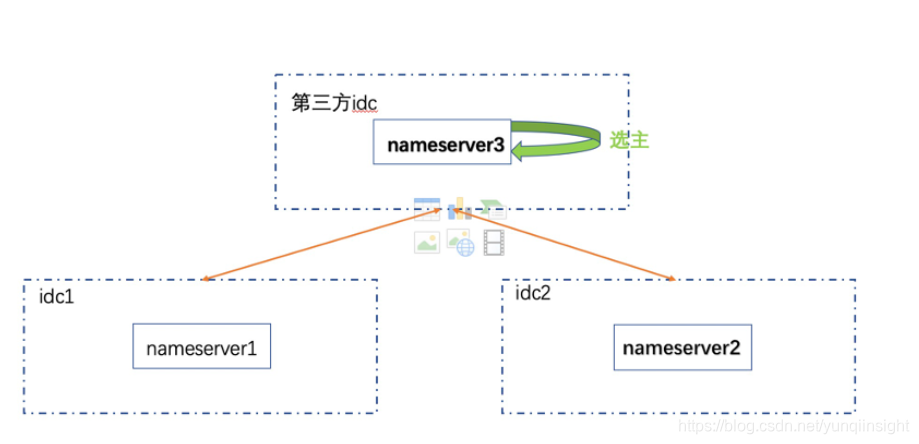
ns 元数据系统中的节点位于三个机房(有一个第三方的云机房,在云上部署 ns 节点,元数据量不大,延时可以接受),三个机房的 ns 节点通过 raft 协议选一个leader,broker 节点会将元数据同步给 leader, leader 在将元数据同步给 follower 。
?
客户端节点获取元数据时, 从 leader,follower 中均可读取数据。
?
![]() ??
??
?
?
流程图如下
![]() ?
?
切中心演练
?
用户请求负载到双中心,下面的操作先将流量切到二中心---回归双中心---切到一中心。确保每个中心均可承担全量用户请求。
先将用户流量全部切到二中心
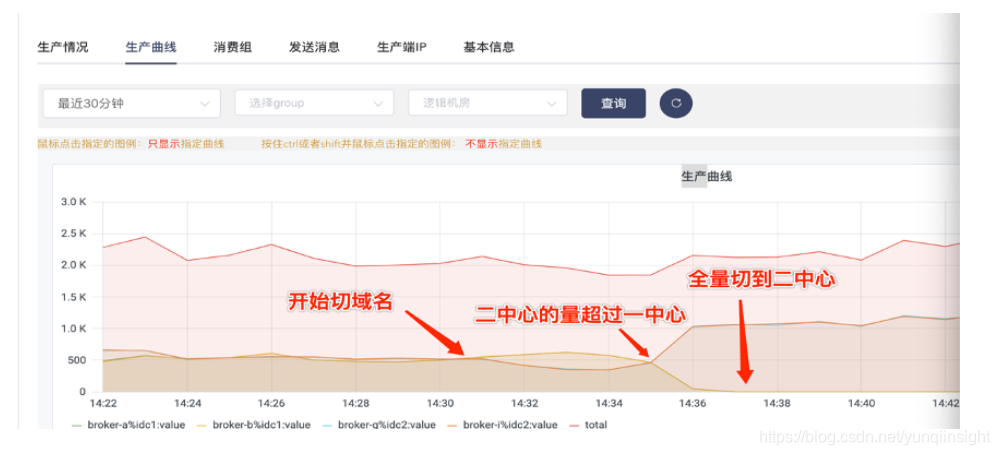
![]() ?
?
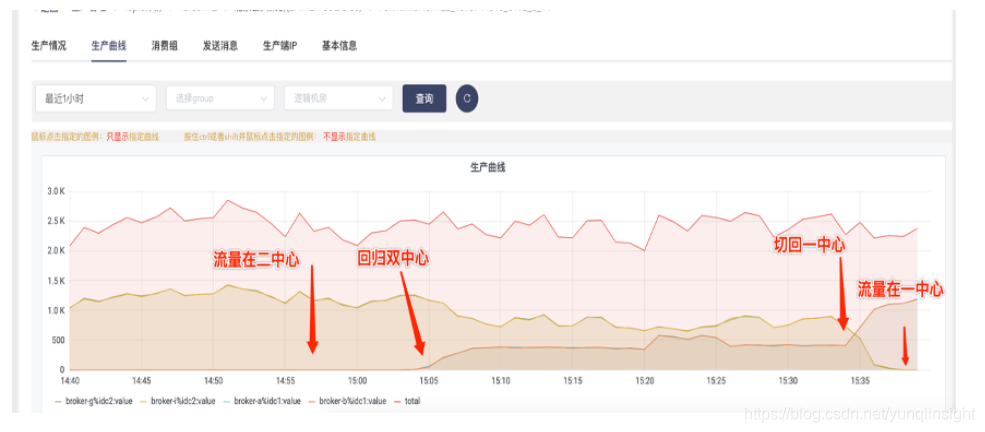
流量回归双中心,并切到一中心
?
![]() ?
?
回顾
?
?
?
即使系统高性能、高可用,倘若随便使用或使用不规范,也会带来各种各样的问题,增加了不必要的维护成本,因此必要的治理手段不可或缺。
?
?让系统更稳定
?
?
主题/消费组治理
?
生产环境 MQ 集群,我们关闭了自动创建主题与消费组,使用前需要先申请并记录主题与消费组的项目标识与使用人。一旦出现问题,我们能够立即找到主题与消费组的负责人,了解相关情况。若存在测试,灰度,生产等多套环境,可以一次申请多个集群同时生效的方式,避免逐个集群申请的麻烦。
?
为避免业务疏忽发送大量无用的消息,有必要在服务端对主题生产速度进行流控,避免这个主题挤占其他主题的处理资源。
?
对消息堆积敏感的消费组,使用方可设置消息堆积数量的阈值以及报警方式,超过这个阈值,立即通知使用方;亦可设置消息堆积时间的阈值,超过一段时间没被消费,立即通知使用方。
?
消费节点下线或一段时间无响应,需要通知给使用方。
客户端治理
?
监控发送/消费一条消息的耗时,检测出性能过低的应用,通知使用方着手改造以提升性能;同时监控消息体大小,对消息体大小平均超过 10 KB 的项目,推动项目启用压缩或消息重构,将消息体控制在 10 KB 以内。
?
一条消息由哪个 ip 、在哪个时间点发送,又由哪些 ip 、在哪个时间点消费,再加上服务端统计的消息接收、消息推送的信息,构成了一条简单的消息链路追踪,将消息的生命周期串联起来,使用方可通过查询msgId或事先设置的 key 查看消息、排查问题。
?
随着功能的不断迭代,sdk 版本也会升级并可能引入风险。定时上报 sdk 版本,推动使用方升级有问题或过低的版本。
服务端治理
?
如何判断一个集群是健康的?定时检测集群中节点数量、集群写入 tps 、消费 tps ,并模拟用户生产、消费消息。
?
性能指标最终反映在处理消息生产与消费的时间上。服务端统计处理每个生产、消费请求的时间,一个统计周期内,若存在一定比例的消息处理时间过长,则认为这个节点性能有问题;引起性能问题的原因主要是系统物理瓶颈,比如磁盘 io util 使用率过高,cpu load 高等,这些硬件指标通过夜鹰监控系统自动报警。
?
高可用主要针对 broker 中 master 节点由于软硬件故障无法正常工作,slave 节点自动被切换为 master ,适合消息顺序、集群完整性有要求的场景。
?
部分后台操作展示
主题与消费组申请
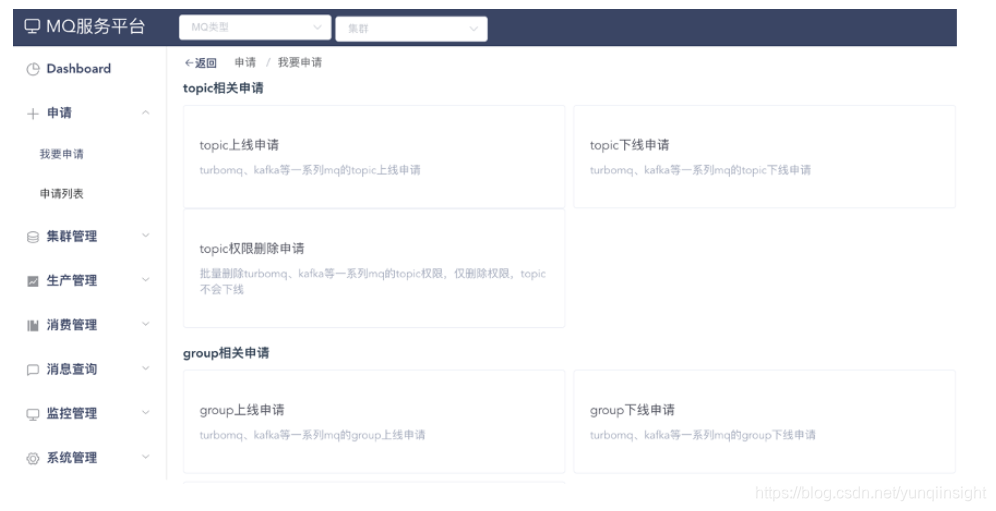
![]() ?
?
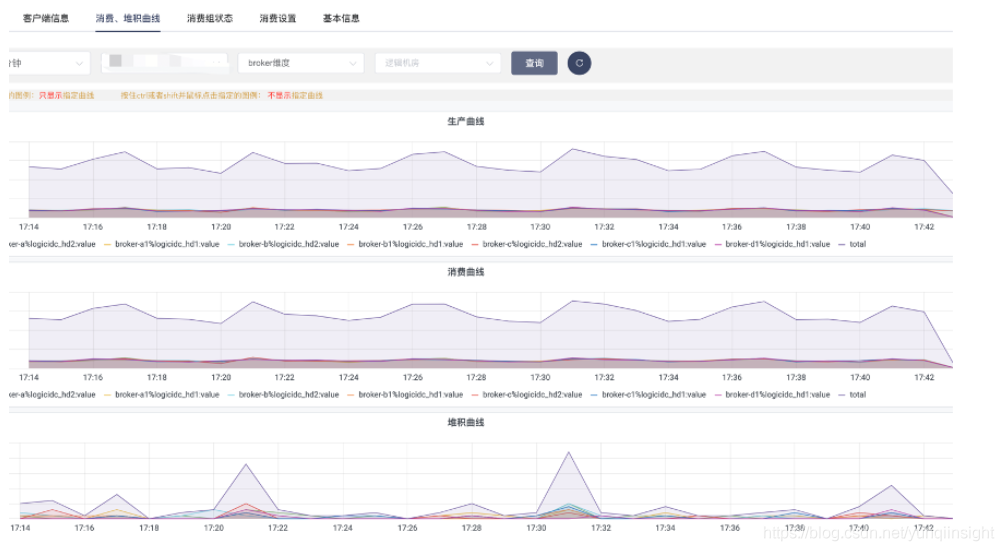
生产,消费,堆积实时统计
?
![]() ?
?
集群监控
![]() ?
?
踩过的坑
?
社区对 MQ 系统经历了长时间的改进与沉淀,我们在使用过程中也到过一些问题,要求我们能从深入了解源码,做到出现问题心不慌,快速止损。
?
?
目前消息保留时间较短,不方便对问题排查以及数据预测,我们接下来将对历史消息进行归档以及基于此的数据预测。
?
原文链接
本文为阿里云原创内容,未经允许不得转载。
?
标签:cte 磁盘 att lte 异步 启动 设置 cat 动作
原文地址:https://www.cnblogs.com/yunqishequ/p/14962115.html