标签:出发点 sep 图片 play 情况下 网络模型 line 相同 enter
目录
1.1 动机
1.2 贡献
1.3 实验分析
1.4 我的想法
2.1 动机
2.2 贡献
2.3 实验分析
2.4 我的想法
3.1 动机
3.2 贡献
3.3 实验分析
3.4 我的想法
4.1 动机
4.2 贡献
4.3 实验分析
4.4 我的想法
5.1 动机
5.2 贡献
5.3 实验分析
5.4 我的思考
噪声标签的最早工作可以追溯到20世纪80年代的任意分类噪声的二分类问题。近些年,随着深度学习研究的深入,相关研究发现深度神经网络在众多场景中取得的成果离不开大量的真实标签信息。然而,在现实复杂的生活场景中,由于人工失误、原始数据噪声和专业知识不足等问题,导致实际采集得到的数据常常包含错误的标签,或者只包含少量的真实性可靠的标签。因此,如何在包含噪声标签的数据集上,合理地选出真实性大或者说可靠的标签是当前的一大研究热点。
在包含噪声标签的数据集上,如果不作任何处理,直接采用神经网络进行有监督的训练和建模,会导致神经网络模型难以学习到原始数据的真实分布,或者说很容易让神经网络模型对错误标注的数据过拟合,导致下游的分类任务性能不理想。近年来,关于噪声标签的研究文章较多,楼主本人通过最近一个月的调研分析,个人的见解可以把当前在噪声标签领域和核心问题分为以下两点:
1) 人工制造的噪声标签建模
2) 真实场景下的噪声标签建模
当前的诸多关于噪声标签的研究成果基本都是建立在人工制造的噪声标签问题底下的理论模型,并且相关模型在人工制造的噪声标签数据集上具有很强的噪声标签样本识别能力,比如Co-teaching[1]和M-correction[2]。然而,较多在人工制造的噪声标签数据集表现良好的模型,在现实真实场景下的噪声标签数据集表现得并不太好,或者很难取得下游分类性能的提升。在人工制造的噪声标签数据集的建模基础源于神经网络的一种特性:在网络模型训练早期,模型能够较快地对包含正确标签的数据进行拟合;同时,随着训练次数的增加,模型逐渐会对错误标签的数据进行拟合,而这样的情况将会导致模型难以学习到正确的数据分布。
依据上述发现,相关研究成果采用在网络早期,依据损失函数的大小排序结果,筛选出部分损失函数小的样本(PS:损失函数越小,表示拟合的越好,即大概率是涵正确标签的样本数据),使得错误标注的样本尽量不参与网络模型的训练,从而最大程度地缓解模型对错误数据过拟合导致模型下游分类性能不足的问题。这类发现,在Co-teaching和M-correction两篇文章中有很清楚的实验分析和理论证明,具体的可见下图:
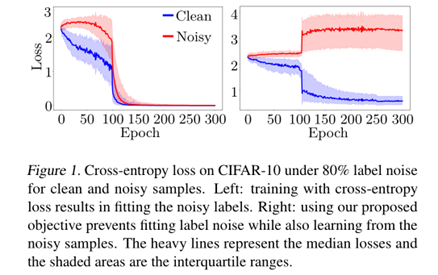
上图中红色曲线表示人工合成错误标注的数据在神经网络模型中拟合得到的交叉熵损失函数值,蓝色曲线表示原始正确标注的数据在神经网络模型中拟合得到的交叉熵损失函数值。由上述左图可知,在训练早期正确标注样本的损失函数值要低于错误标注样本,但是不加控制,随着训练次数的增加,逐渐对错误样本拟合,导致两者很难区分开;而右图,则是M-correction模型采用样本选择策略,控制错误样本对模型训练的贡献程度,从而在不断训练的过程中,将人工合成的错误标注样本和正确标注样本区分开。
上述的发现基本上都是基于人工合成的噪声标签,然而对于现实复杂场景中本就很相似的样本,或者处于不同类别分类边界的样本来说,输入到神经网络中进行训练时,大概率是很难符合上述现象:在训练早期,正确样本的loss小,错误标注样本的loss较大。具体的示例可以见下图[3]。
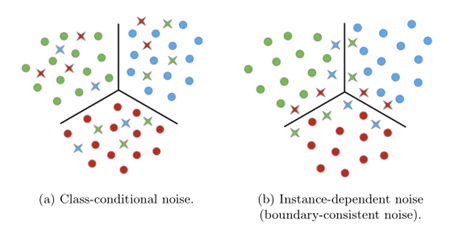
上图中(a)表示人工合成的噪声标签样本分布,其在四角菱形表示原始类别的样本错误标记为其它类别,可知人眼就可以很快辨别。对于图(b),可以发现较多错误标注的样本处于三种不同类别的边界,即原始的样本质量就较差,难以辨别,在实际场景中也容易被人工标注或者机器识别错误,这样的噪声标签数据集更加符合现实复杂场景中的数据。
关于人工合成标签和真实场景下的噪声标签区别,还可以见下图的图片示例[4]:

上图中绿色噪音表示人工合成的噪声标签对应的数据,可以发现瓢虫是正确样本时,其错误样本大部分都是不相干的类别图像:小鸟,小孩和车等。与之相反的是,红色噪声表示真实场景下搜索结果自动标注的瓢虫对应的噪声标签样本:含红色面具的卡通人物,绿叶背景的其它虫类等。
上面是楼主本人对噪声标签领域问题的一点个人见解,个人觉得后续的研究重点还是在现有人工缺失噪声标签数据上表现良好的研究成果基础上,逐渐寻找合适的理论和模型去解决如何区分实际场景中模糊的噪声标注样本。
关于人工合成的数据集研究模型,建议关注以下三篇文章:Co-teaching[1] (NIPS, 2018), Co-teaching+[5] (ICML, 2019), JoCoR[6] (CVPR, 2020).
关于现实复杂场景中的理论建模,建议关注以下两篇文章:MentorMix[4] (ICML, 2020), CSIDN[3] (ICML, 2021).
另外,楼主本人最近在调研如何把选取聚类获取伪标签中置信度比较高的标签,这个问题其实可以当作噪声标签来建模,然而,当前的实验现象发现聚类得到的伪标签之间存在较强的距离语义关系,到时基本很难当作噪声标签问题来建模。其实,这两者应该是属于不同的问题,但是相关性比较强,可以考虑如何深入,目前找到了三篇选取聚类中置信度高伪标签的问题,具体可见[7](IJCV,2020),[8](ICLR,2020),[9](CVPR,2021).
关于Co-teaching和把MixUp用于半监督学习的MixMatch文章见解可参考博文:噪声标签浅析
最后,分享以下我最近看到的五篇关于噪声标签的文章,每篇文章都有开源获取代码,有兴趣的同学可以去下载看看。
带噪声标签的学习是弱监督学习的热点问题之一。基于深度神经网络的记忆效果,采用小损失选择实例机制的训练,对于处理有噪声标签的数据集是非常有效的一种机制。
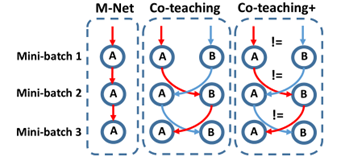
上述机制是简单有效“Co-teaching”方法的核心,即使用小损失技巧交叉训练两个深度神经网络。然而,随着训练次数的增加,两种网络的预测结果逐渐趋同为一种共识,使得Co-teaching逐渐沦为一种自我训练的MentorNet。
针对Co-teaching随着训练次数增加,预测结果变得越来越一致,导致难以合理区分噪声标注样本的问题,本文通过在Co-teaching模型基础上添加一种两种预测结果不一致才更新的策略,使得模型对于噪声标签的区分能够更加鲁棒,并将其简称为Co-teaching+。Mentor-Net, Co-teaching和Co-teaching+的区别如下:
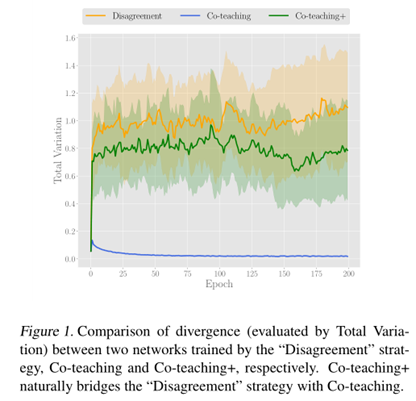
上述预测结果不一致的机制,通过两种网络随着训练次数不断上升的情况下,添加不一致的预测机制后,可以使得两个网络能够在一定程度上保持较高的分歧,具体效果如下图:
上述机制实现的简单算法伪码如下:

本文实验在MNIST, CIFAR-10, CIFAR-100, NEWS和T-ImageNet五种数据集上进行了人工合成伪标签的建模实验分析。
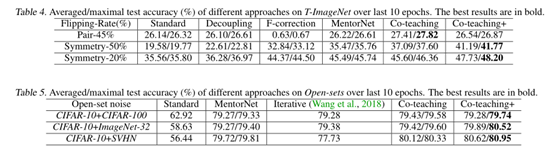
本文主要在于验证了两种网络预测不一致的策略在Co-teaching模型上进行了验证分析,并且解决了Co-teaching模型随着训练次数上次,逐渐演变为MentorNet的问题。预测不一致的策略说明在两种网络协同教学过程中,还是发挥了较大的作用,但是本文对于其起作用的具体原理机制未做深入分析和可视化探讨,导致在本文结束时依然只能依靠实验结果去分析和理解。
大型深度神经网络在相关场景下建模功能强大,但确容易对一些敌对样本敏感和记忆的行为,导致下游任务表现不好。
深度神经网络训练的目标是最小化在训练数据上的平均错误,该学习规则也被称为经验风险最小化(ERM)原理。当训练数据中包含一些对抗性样本时,神经网络模型的下游预测结果会大幅改变,然而,ERM无法解释这样小幅改变导致学习的数据分布难以拟合实际理想的情况。
本文提出了一种简单的学习机制:MixUp,用于缓解神经网络模型在出现对抗样本或者噪声数据时难以学习到正确数据分布的问题。从本质上讲,mixup正则化了神经网络,以支持训练样本之间的简单线性行为。
本文提出的MixUp机制如下:

通过上述的样本混淆,本文的实验结果表明上述机制降低了神经网络对于错误标签的记忆,提高了模型对对抗性样本的鲁棒性,也使得模型的训练更加稳定。
本文对经验风险最小化的解释,其推导到最后就是交叉熵损失函数,具体过程如下:

关于MixUp机制,本文作者的预先实验表明三个或三个以上的例子的凸组合与从狄利克雷分布抽样权值不能提供进一步的增益,并且增加了计算成本的混合。
关于MixUp其具体在做什么?作者认为MixUp的邻近分布可以理解为数据处理的一种形式,它鼓励模型f在训练实例之间表现为线性,而这种线性行为在预测训练实例之外的情况时减少了不必要的振荡。具体的可视化图如下图所示:
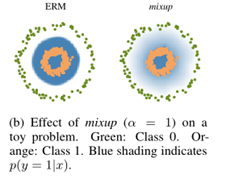
此外,MixUp机制使得神经网络模型对于样本的拟合更好,梯度值也更小,作者采用在CIFAR-10数据集上使用ERM和mixup训练的两个神经网络模型的平均行为。两个模型具有相同的体系结构,使用相同的程序进行训练,并在随机抽样训练数据之间的相同点进行评估。具体的对比分析如下图:
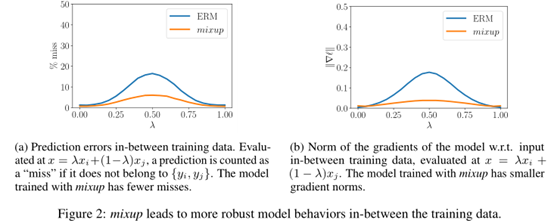
本文在图像和表格数据集上对本文的MixUp机制进行了验证分析。在ImageNet上的错误率评估结果如下:
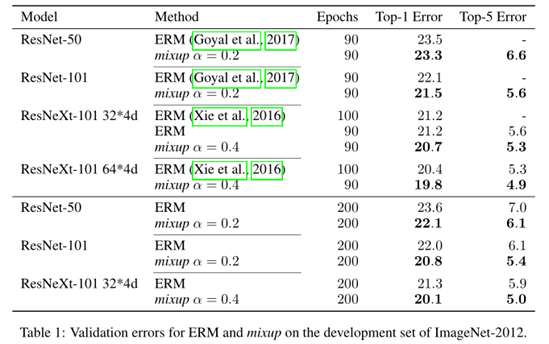
在上面的ImageNet数据集上,作者发现α∈[0.1,0.4]会导致ERM性能的改善(PS:针对ImageNet数据集),而对于大α, mixup会导致欠拟合。我们还发现,能力更高和/或训练时间更长的模型从MixUp中受益最大。
接着,作者将CIFAR-10中标签进行打乱合成噪声标签,采用MixUp机制进行评估,具体结果如下表:
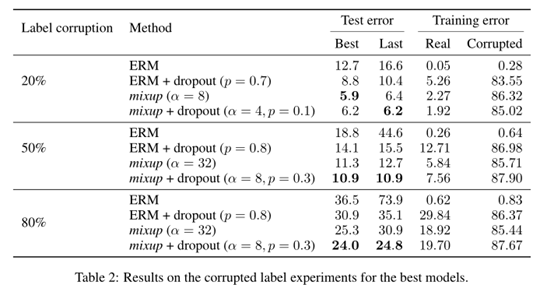
此外,在表格数据集上的实验结果如下:
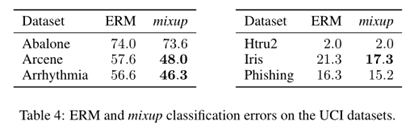
最后,作者进行了消解实验,其实验结果表明MixUp是我们测试的最好的数据增强方法,并且明显优于第二好的方法(MixUp)+标签平滑)。在所有的输入插值方法中,所有类别的混合随机对(AC + RP)的正则化效果最强。标签平滑和添加高斯噪声的正则化效果相对较小。
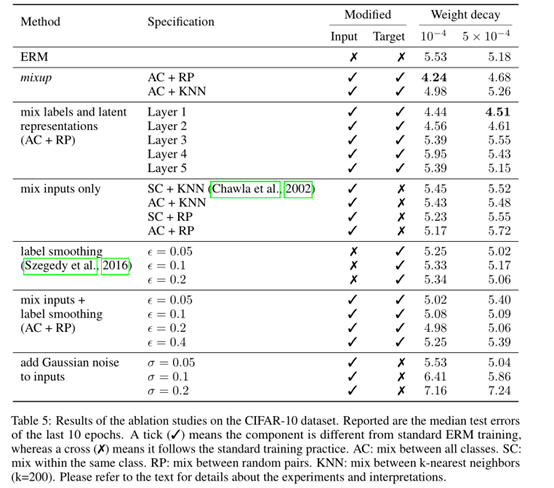
本文提出的MixUp机制简单,实验也很充分详细,并且本文的方法在多篇噪声标签最新论文中都有被用到,可拓展性很强。本文提到MixUp是一种数据增强策略,并且可以把它认为是一种强大的正则化手段,该策略可以考虑作为一种常见的备用trick进行实验分析。
最后,本文的MixUp机制可以考虑如何迁移应用到不同场景中的半监督学习和无监督学习中,这样的扩展也是本文作者最后结论中的一点,并且MixMatch就一种基于MixUp机制的半监督学习机制。
采用噪声比例受控的真实场景下的噪声数据集对理解噪声水平分布的深度学习模型至关重要。由于缺乏合适的贴近真实场景下的噪声数据集,已有的研究成果大多数都是在人工合成的可控数据集上进行实验,而这样的情况导致相关模型在真实场景下的噪声数据集上表现不好。
真实世界的标签噪声从未在受控环境中进行过研究。这导致了两个主要问题。首先,由于合成噪声是由人工分布产生的,分布中的微小变化可能导致不一致甚至矛盾的结果。其次,绝大多数以前的研究更倾向于在噪声水平上验证鲁棒学习方法,因为这些方法的目标是克服较大比例的噪声水平。然而,目前的评估是有限的,因为上述工作只进行了人工合成标签噪声上的建模。
(1)本文建立了第一个依据现实场景下的可控图像噪声标签数据集,通过雇佣人工对样本进行标签信息纠正,共计完成了80万的标注信息;
(2)提出了一种基于MenterNet和MixUp用于客服真实场景下噪声数据的方法,实验结果表明其能够取得STOA;
(3)本文在真实场景和合成噪声数据集上,进行了较大规模的不同噪声级别和网络架构的实验,相关实验结果希望能够对在真实场景下噪声标签建模提高一定的建设性结论。
本文构建的接近真实场景的噪声数据集,于当前人工合成的噪声数据集重要区别:本文没有改变采样干净图像的标签,而是用错误标记的web图像替换干净图像,同时保持标签不变。这种方法的优点是,我们紧密匹配合成数据集的构造,同时仍然能够引入可控的web标签噪声。
本文的MenterMix的核心结合了MentorNet依据损失函数选取干净样本,并采用MixUp降低模型对噪声样本的拟合。MeterNet的基本原理如下:

结合MixUp,进一步提出了MenterMix:

其中t是softmax函数中的温度,在本文的实验中固定为1。Pv指定了单个训练例子的密度函数。理论上,分布是在所有训练示例中定义的,但在实践中,为了实现小批训练,我们计算每个小批训练中的分布。对上述的公式(5)进行变换,得到如下的公式(8)

具体的算法伪码公式如下:

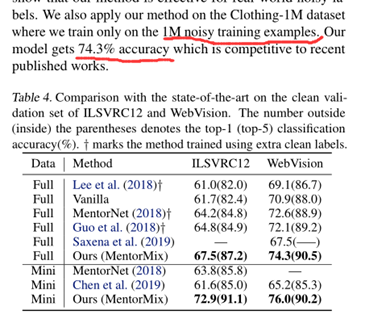
本文在四个数据集上验证了所提出的方法,并给出了关于网页标签噪声的新发现。
总体实验结果,表明MentorNet+MixUp能够有效提高MentorNet的效果。
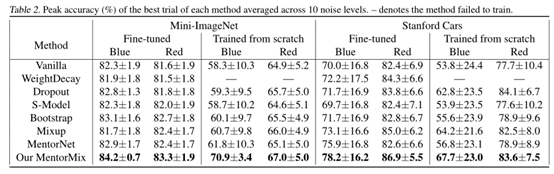
其中蓝色噪声表示合成标签噪声,用红色噪声表示网页标签噪声。
本文对深度神经网络在合成噪声标签数据集和真实场景噪声标签数据集进行了实验分析,具体如下图:
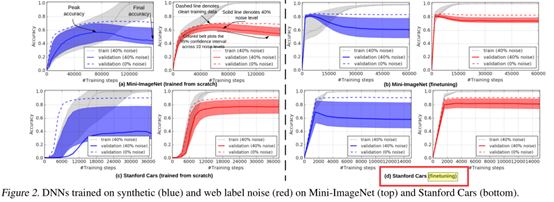
蓝色表示人工合成噪声数据集,红色表示真实场景噪声数据集。上左图一个是直接在含噪声的数据集上训练,右图是在含噪声的数据集上进行微调。结果表明,右图在干净数据训练的模型上执行微调能够有效降低噪声标签对模型过拟合的影响。
另外,本文实验结果表明深度神经网络可能并不会率先在真实场景数据集上对干净标注数据进行拟合,具体分析如下图:
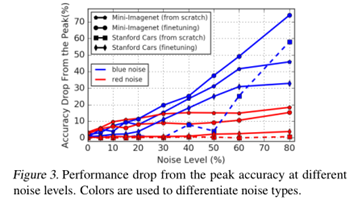
本文的创新点验证了MixUp机制在噪声标签领域具有很强的抗噪声能力,而且MixUp具有很强的领域迁移性。此外,本文在最后关于噪声标签框架本质:神经网络是否会在早期对干净标签容易拟合的性能进行了在合成噪声和实际噪声标签数据集上的探讨分析,这一点可以为后续的噪声标签领域研究给予一定的启发:即设计的相关模型应该能够在向解决实际真实场景下的噪声标签分布的问题前进,而不能停留在人工合成的伪标签上面。
现有的依赖于人的监督的方法通常是不可扩展的,因为手动识别正确或不正确的标签是费时的,而不依赖于人的监督的方法是可扩展的,但效率较低。
为了减少标签噪声清洗过程中人工监督的数量,本文引入了联合神经嵌入网络CleanNet,它只需要人工验证一小部分类别,就可以提供标签噪声的知识,从而可以转移到其他类别。其核心创新:
1) 采用注意力机制选取干净的标签
2) 采用聚类的思想选取类中心
聚类思想的体现如下:
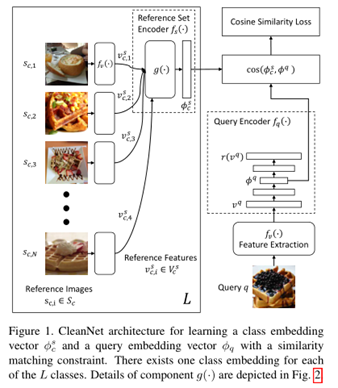
注意力机制的思想体现如下:
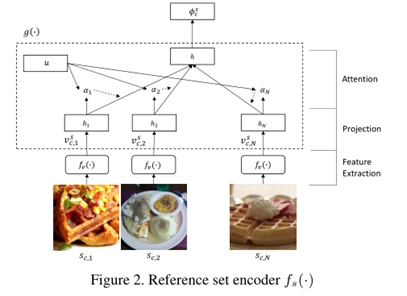
借用注意力机制的核心处理公式如下:

采用聚类思想的公式如下:



最终的模型如下:
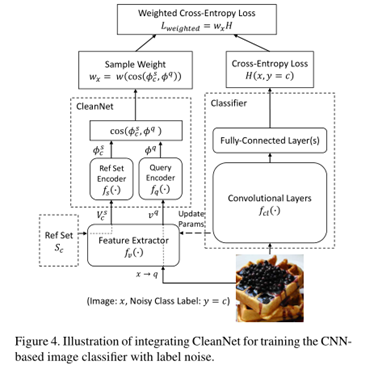
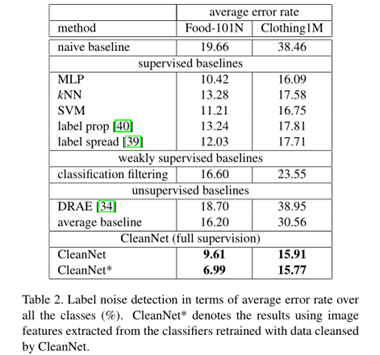
本文采用三种实际真实的噪声标签数据集进行实验:
本文讲聚类的余弦相似度、注意力机制和神经网络的微调策略结合起来,做噪声标签的思路值得借鉴。特别是在判断不同样本间的相似度时,可以考虑设定一个样本相似度模块,用于做噪声标签检测。
本文的模型有点复杂,并且实验的设定和当前主流的噪声标签文章不太一致,并且其实验的对比方法好像比较单一,此外其还要采用人工标注的监督信息,好像这样的方式并不太合适。但是,本文重点在于对采用余弦相似度和注意力机制的应用能够提供一定的启发。
尽管卷积神经网络对少量的标签噪声具有鲁棒性,但使用随机梯度方法训练的卷积神经网络可以很容易地匹配随机标签。当正确目标和错误目标混杂在一起时,网络往往先适合前者,后适合后者。
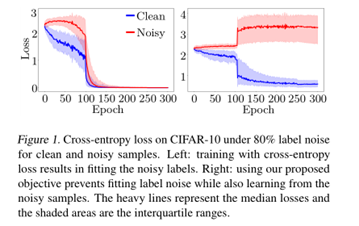
本文提出了一个贝塔混合估计这个概率,并通过依赖网络预测(所谓的自举损失)来纠正损失。进一步结合MixUp,以促进本文方法进一步的提升。
基于Beta的混合概率估计表现如下:
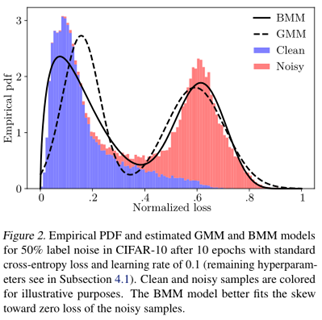
损失函数纠正机制如下:

结合MixUp的损失函数纠正机制:

本文在CIFAR-10和CIFAR-100上面的实验结果如下:
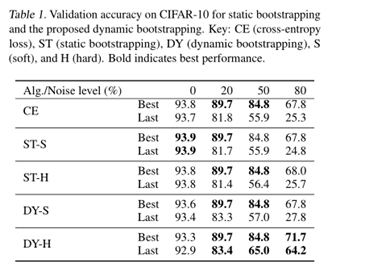
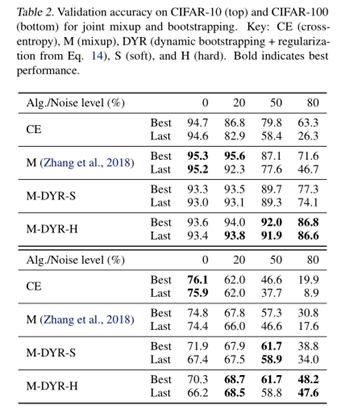
本文最大的亮点在于把人工合成噪声标签数据集上,干净样本在网络训练早期拟合速度快于噪声样本的问题分析的很清楚,但是本文的不足是其没有和Co-teaching进行比较分析,因为本文的出发点和本质就和Co-teaching很相似。
最后,附加一篇在NLP领域做噪声标签的文章:
动机:近年来,深度学习在命名实体识别(NER)方面的研究取得了显著进展。大多数现有的作品假设干净的数据注释,但现实场景中的一个基本挑战是来自各种来源(例如,伪注释、弱注释或远程注释)的大量噪声。
贡献:这项工作研究了一种具有校准置信估计的噪声标记设置。基于对噪声标签和清洁标签不同训练动态的实证观察,提出了基于局部和全局独立性假设估计置信分数的策略。
参考文献
[1] B. Han et al., “Co-teaching: robust training of deep neural networks with extremely noisy labels,” in Proceedings of the 32nd International Conference on Neural Information Processing Systems, Red Hook, NY, USA, Dec. 2018, pp. 8536–8546.
[2] E. Arazo, D. Ortego, P. Albert, N. O’Connor, and K. Mcguinness, “Unsupervised Label Noise Modeling and Loss Correction,” in International Conference on Machine Learning, May 2019, pp. 312–321. Accessed: Jul. 13, 2021. [Online]. Available: http://proceedings.mlr.press/v97/arazo19a.html
[3] A. Berthon, B. Han, G. Niu, T. Liu, and M. Sugiyama, “Confidence Scores Make Instance-dependent Label-noise Learning Possible,” in International Conference on Machine Learning, Jul. 2021, pp. 825–836. Accessed: Jul. 20, 2021. [Online]. Available: http://proceedings.mlr.press/v139/berthon21a.html
[4] L. Jiang, D. Huang, M. Liu, and W. Yang, “Beyond Synthetic Noise: Deep Learning on Controlled Noisy Labels,” in International Conference on Machine Learning, Nov. 2020, pp. 4804–4815. Accessed: Jul. 13, 2021. [Online]. Available: http://proceedings.mlr.press/v119/jiang20c.html
[5] X. Yu, B. Han, J. Yao, G. Niu, I. Tsang, and M. Sugiyama, “How does Disagreement Help Generalization against Label Corruption?,” in International Conference on Machine Learning, May 2019, pp. 7164–7173. Accessed: Jul. 13, 2021. [Online]. Available: http://proceedings.mlr.press/v97/yu19b.html
[6] H. Wei, L. Feng, X. Chen, and B. An, “Combating Noisy Labels by Agreement: A Joint Training Method with Co-Regularization,” 2020, pp. 13726–13735. Accessed: Jul. 13, 2021. [Online]. Available: https://openaccess.thecvf.com/content_CVPR_2020/html/Wei_Combating_Noisy_Labels_by_Agreement_A_Joint_Training_Method_with_CVPR_2020_paper.html
[7] Z. Zheng and Y. Yang, “Rectifying Pseudo Label Learning via Uncertainty Estimation for Domain Adaptive Semantic Segmentation,” Int J Comput Vis, vol. 129, no. 4, pp. 1106–1120, Apr. 2021, doi: 10.1007/s11263-020-01395-y.
[8] Y. Ge, D. Chen, and H. Li, “Mutual Mean-Teaching: Pseudo Label Refinery for Unsupervised Domain Adaptation on Person Re-identification,” presented at the International Conference on Learning Representations, Sep. 2019. Accessed: Jul. 13, 2021. [Online]. Available: https://openreview.net/forum?id=rJlnOhVYPS
[9] F. Yang et al., “Joint Noise-Tolerant Learning and Meta Camera Shift Adaptation for Unsupervised Person Re-Identification,” 2021, pp. 4855–4864. Accessed: Jul. 13, 2021. [Online]. Available: https://openaccess.thecvf.com/content/CVPR2021/html/Yang_Joint_Noise-Tolerant_Learning_and_Meta_Camera_Shift_Adaptation_for_Unsupervised_CVPR_2021_paper.html
标签:出发点 sep 图片 play 情况下 网络模型 line 相同 enter
原文地址:https://www.cnblogs.com/liuzhen1995/p/15038959.html