标签:axis 均值 nsf 下载文件 标准 already inf exist pat
在指定网址下载文件,并放到指定目录
import urllib.request import os url = "xxxxx" data_path = "D:/xxx" if not os.path.isfile(data_path): # 如果不存在文件 ret = urllib.request.urlretrieve(url, data_path) #则下载 print("Download: ", ret) else: print(data_path, "already exists")
df = pd.read_excel(data_path) #读取文件 select_cols = ["survived", "name", "pcalss", "sex", "age", "sibsp", "parch", "fare", "embarked"] #选出要用的列 df = df[select_cols] df.isnull()#可列出所有存在空或者NA的行,为一个True和False的矩阵,若元素为空或者NA则为True,否则为False
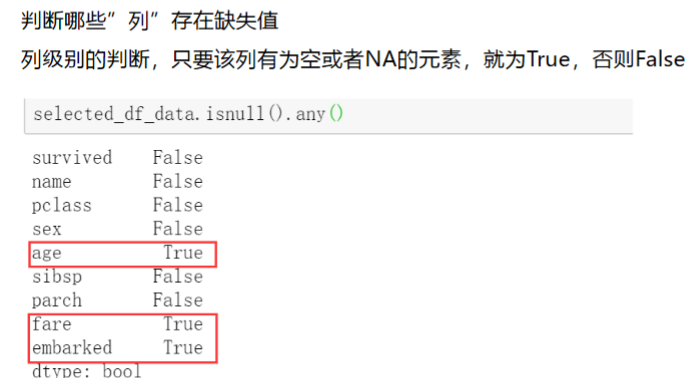
df.isnull().any()
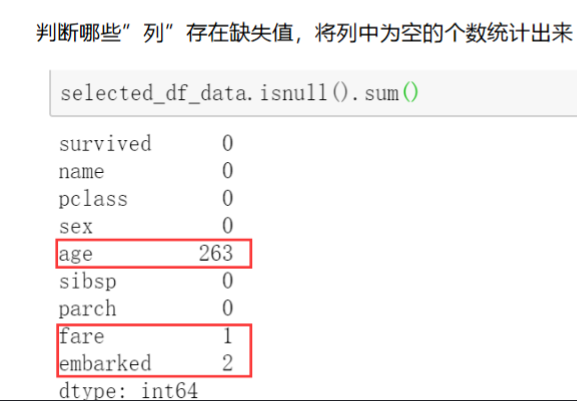
df.isnull.sum()
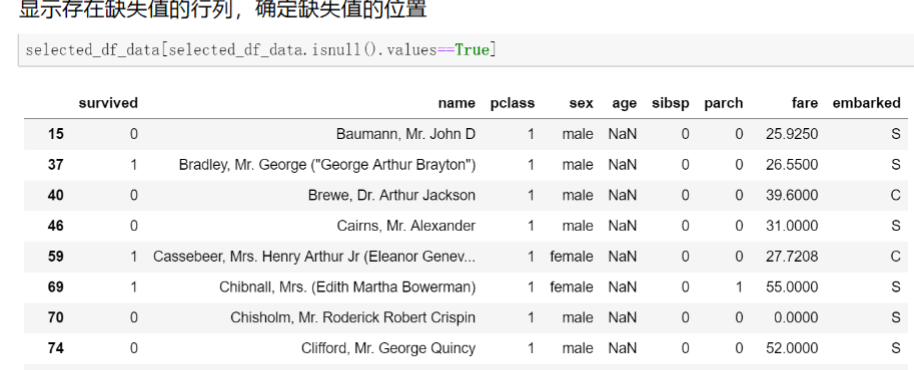
df[df.isnull().values == True]
填充缺失值,用平均值填充
avg_age = df[‘age‘].mean()
df[‘age‘] = df[‘age‘].fillna(avg_age)
将性别转换成序号
df[‘sex‘] = df[‘sex‘].map({‘female‘ : 0, ‘male‘ : 1}).astype(int)
删除一列
axis = 1表示删除列
df = df.drop([‘name‘], axis = 1)
数据标准化
from sklearn import preprocessing
minmax_scale = preprocessing.MinMaxScaler(frature_range = (0, 1))
x_data = minmax_scale.fit_transform(x_data)
标签:axis 均值 nsf 下载文件 标准 already inf exist pat
原文地址:https://www.cnblogs.com/WTSRUVF/p/15048130.html