标签:控制 www ret 依赖 com 误差 net 应用 over
1、GRU概述
GRU是LSTM网络的一种效果很好的变体,它较LSTM网络的结构更加简单,而且效果也很好,因此也是当前非常流形的一种网络。GRU既然是LSTM的变体,因此也是可以解决RNN网络中的长依赖问题。
在LSTM中引入了三个门函数:输入门、遗忘门和输出门来控制输入值、记忆值和输出值。而在GRU模型中只有两个门:分别是更新门和重置门。具体结构如下图所示:
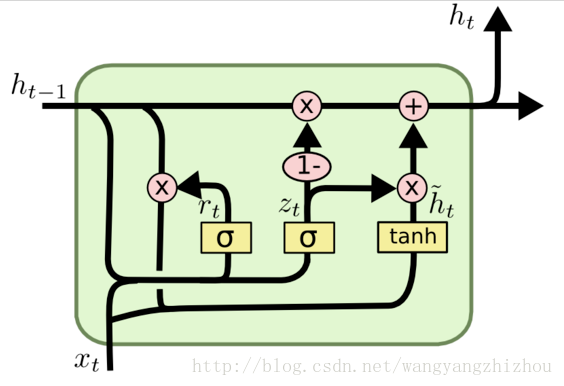
图中的zt和rt分别表示更新门和重置门。更新门用于控制前一时刻的状态信息被带入到当前状态中的程度,更新门的值越大说明前一时刻的状态信息带入越多。重置门控制前一状态有多少信息被写入到当前的候选集 ?? ??h~t 上,重置门越小,前一状态的信息被写入的越少。
2、GRU前向传播
根据上面的GRU的模型图,我们来看看网络的前向传播公式:
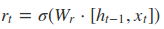
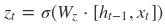
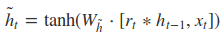
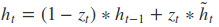
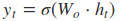
其中[]表示两个向量相连,*表示矩阵的乘积。
3、GRU的训练过程
从前向传播过程中的公式可以看出要学习的参数有Wr、Wz、Wh、Wo。其中前三个参数都是拼接的(因为后先的向量也是拼接的),所以在训练的过程中需要将他们分割出来:
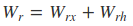
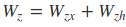
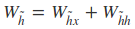
输出层的输入:
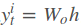
输出层的输出:
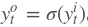
在得到最终的输出后,就可以写出网络传递的损失,单个样本某时刻的损失为:
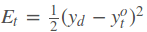
则单个样本的在所有时刻的损失为:
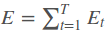
采用后向误差传播算法来学习网络,所以先得求损失函数对各参数的偏导(总共有7个):
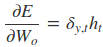
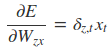
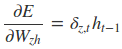
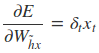
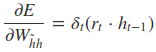
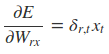
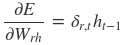
其中各中间参数为:
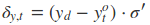
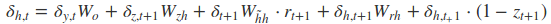
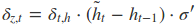
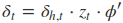
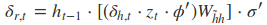
在算出了对各参数的偏导之后,就可以更新参数,依次迭代知道损失收敛。
概括来说,LSTM和CRU都是通过各种门函数来将重要特征保留下来,这样就保证了在long-term传播的时候也不会丢失。此外GRU相对于LSTM少了一个门函数,因此在参数的数量上也是要少于LSTM的,所以整体上GRU的训练速度要快于LSTM的。不过对于两个网络的好坏还是得看具体的应用场景。
参考文献:
抄袭:
标签:控制 www ret 依赖 com 误差 net 应用 over
原文地址:https://www.cnblogs.com/ccfco/p/15065915.html