标签:style blog http io color ar os sp java
推荐系统是近几年比较火的一个话题,尤其是Netflix举办过一次电影推荐比赛之后,ACM有专门的Recommer System的会议。关于推荐系统的分类,从不同的角度有不同的分法,传统的有两种分法,一种叫基于内容(Content based)的推荐,顾名思义就是根据要推荐的项目(电影,书籍,音乐等等)本身的一些DNA进行推荐,比如电影的类型,是动作片还是爱情片还是动作爱情片?电影的导演是否有名,演员的阵容怎么样等等。还有一种叫协同过滤(Collaborative Filtering),协同过滤按照算法又可以分成很多小类,User-based,Item-based,Slope-one,Model-based,下面就以一个实际例子来介绍不同的推荐算法是怎么实现的。
例子:假设我们获取了一些用户在对一些项目的评分,我们的目的是预测某个用户对某个项目的评分。如下面的表格所示,我们拿预测User1对Item2的评分举例。
| Item1 | Item2 | Item3 | Item4 | |
| User1 | 4 | ? | 5 | 5 |
| User2 | 4 | 2 | 1 | |
| User3 | 3 | 2 | 4 | |
| User4 | 4 | 4 | ||
| User5 | 2 | 1 | 3 | 5 |
Content-based是说我们在已经知道了Item DNA的情况下,基于这些DNA去做推荐。比如我们的Item是电影,那Item的DNA可能是电影的类型,我们拿喜剧片,爱情片和科幻片举例。假如Item 2 是一部喜剧片,同时也可以是一部爱情片,我们用一个三维向量表示为:
$\large \mathbf{x}^2 = (1,0.99,0)^T$
如果同时我们也知道了用户喜欢什么样的电影,到底是喜欢喜剧片多一点还是喜欢科幻片片多一点?那么用户的喜好也可以用一个三维向量来表示,假如用户1只喜欢爱情片(喜好程度用0-5来表示),那么用户1的爱好用向量表示为:
$\large \mathbf{w}^1=(0,5,0)^T$
那么,我们基于这两个向量就可以预测用户1会给Item 2 评多少分:
$\large r^{1,2} = {\mathbf{w}^1}^T \cdot \mathbf{x}^2 = 0*1 + 5*0.99 + 0 * 0 = 4.95 $
但实际上我们并不知道表征喜好程度的向量,我们的目的是要学习出这个向量。
为此,我们想定义一些符号:
$\large n_u$:表示一共有多少用户
$\large n_m$:表示一共有多少Item
$\large c(i,j)$:=1表示用户 i 评价过 Item j
$\large r^{i,j}$: 表示用户 i 对 Item j 的评分
$\large \mathbf{x}^j$:表征 Item j 的特征向量
$\large \mathbf{w}^i $: 表征用户的特征向量(未知,需要学习)
$\large m^i $:用户 i 评价过的 Item 数量
$\large n+1$:$\mathbf{x}$和 $\mathbf{w}$的维度
为了学习到用户的特征向量,我们需要定义一个学习策略,我们仍然采用先定义损失函数,然后对损失函数求极小的策略来学习用户特征。很自然的一个选择就是采用平方损失函数。用户 i 对 Item j 的评分损失为:
$\large ( {\mathbf{w}^i}^T \cdot \mathbf{x}^j - r^{i,j} )^2$
对某个用户 i 来说,损失为:
$\Large \frac {1} {2m^i} \sum_{j : c(i,j)=1} ( {\mathbf{w}^i}^T \cdot \mathbf{x}^j - r^{i,j} )^2 + \frac {\lambda}{2m^i} \sum_{k=1}^{n} (w_k^i)^2 $
对所有的用户来说,损失为:
$\Large L(\mathbf{w}) = \frac {1}{2} \sum_{i=1}^{n_u} \sum_{j : c(i,j)=1} ({\mathbf{w}^i}^T \cdot \mathbf{x}^j - r^{i,j})^2 + \frac {\lambda}{2}\sum_{i=1}^{n_u}\sum_{k=1}^{n}(w_k^i)^2 $
最小化上面的损失函数,采用梯度下降进行迭代:
$\Large w_k^i = w_k^i - \alpha \sum_{j : c(i,j)=1} ( {\mathbf{w}^i}^T \cdot \mathbf{x}^j - r^{i,j} ) x_k^j \qquad (for \qquad k=0) $
$\Large w_k^i = w_k^i - \alpha (\sum_{j : c(i,j)=1} ( {\mathbf{w}^i}^T \cdot \mathbf{x}^j - r^{i,j} ) x_k^j + \lambda w_k^i) \qquad (for \qquad k \neq 0) $
如下图所示,我们有三个用户1,2,3和三个电影A,B,C。用户1喜欢电影A和电影C,用户2喜欢电影A,B,C,用户3喜欢电影A。假设电影A和电影C很相似(这里的相似性不是由A和C本身的DNA得到的,至于计算方面后面再说),那么我们有理由预测用户3会喜欢电影C,因为她喜欢A,而A和C很相似。
如果用户1给电影A打了5分,而A和C又有90%的相似,那么我们会预测说用户3给电影C的评分是5*90%=4.5分。这就是所谓的Item-based。
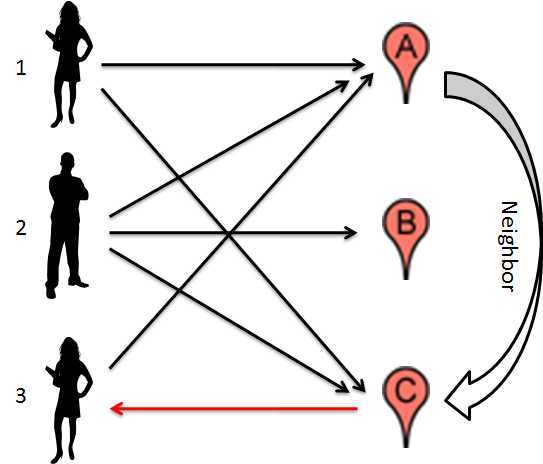
推广一下,回头看看我们开头的例子,我们的任务是要预测用户1会给Item2评多少分,如果我们已经知道了Item2和Item1,Item2和Item3,Item2和Item4之间的相似性,那么我们预测:
$\Large p^{u1,i2} = \frac {r^{u1,i1}s^{i2,i1} + r^{u1,31}s^{i2,i3} + r^{u1,i4}s^{i2,i4}} {s^{i2,i1}+s^{i2,i3}+s^{i2,i4}} $
那么问题来了,在不知道Item本身的信息的情况下,如何计算两个Item之间的相似性呢?如果我们把每个Item都用一个列向量来表示,其中向量里的每一维都是不同的用户对这个Item的评分,那么计算两个Item之间的相似性就转化成我们熟悉的计算两个向量之间的相似性了,可以采用余弦距离(Cosine distance),皮尔逊相关性系数(Peason correlation coefficient),杰卡德相似系数(Jaccard similarity coefficient)等等。这里我们拿皮尔逊相关性系数举例:
$\Large s^{i,j}=\frac {\sum_{u \in U} (r^{u,i} - \overline{r^i}) (r^{u,j} - \overline{r^j}) } {\sqrt{ \sum_{u \in U} (r^{u,i} - \overline{r^i})^2 } \sqrt{ \sum_{u \in U} (r^{u,j} - \overline{r^j})^2 } } $
其中:
$s^{i,j} $ 表示Item i 和Item j之间的相似性
$U$表示同时评价过Item i和Item j的用户集合
$\overline{r^i}$表示用户集合$U$在Item i上的平均评分
$\overline{r^j}$表示用户集合$U$在Item j上的平均评分
用户 a 对 Item i 的评分预测公式为:
$\Large p^{a,i} = \frac {\sum_{j \in I} r^{u,j}s^{i,j}}{\sum_{i \in I} |s^{i,j}|} $
其中:
$I$为用户 a 评价过的Item集合
那么预测User 1 对 Item 2 评分的具体计算步骤为:
1. 找出User 1 评价过的Item集合:Item 1, Item3, Item 4
2. 计算Item 2 和Item 1,Item 3, Item 4之间的相似度
拿计算Item 2 和 Item 1 相似性举例:
2.1 找出同时评价过 Item 2 和 Item 1的用户集合U:用户2,用户4和用户5
2.2 用户集合U在 Item 1 上的平均分3.33,在Item 2 上的平均分2.33,所以:
$\Large s^{2,1} = \frac {0.67*-0.33 + 0.67*1.67+ -1.33*-1.33} {\sqrt {0.67^2 + 0.67^2 + (-1.33)^2} \sqrt {0.33^2 +1.67^2 + 1.33^2}} = 0.754 $
同理,计算出$s^{2,3}=-1, s^{2,4}=0.756$
3. 根据相似度和评分预测公式计算出预测分数
$\Large p^{1,2} = \frac {4*0.754 + 5*(-1) + 5 *0.756} {0.754 + 1 + 0.756} = 0.716 $
在实际工程中,我们遇到的Item数量往往很大,如果在线去计算所有 Item 两两之间的相似度的话肯定不现实,那么实际工程中应该怎么处理呢? 这里提供两个方法:
第一种: 对所有Item进行预处理,一般是用哈希的思想,将可能相似的Item集合Hash到一个桶里,那么在线计算的时候,只需要计算在某个桶里的Item两两之间的相似性了,具体做法请google LSH,这里不多说。
第二种: 用分布式计算离线把所有Item 之间的相似性都计算好,在线直接查询就行。
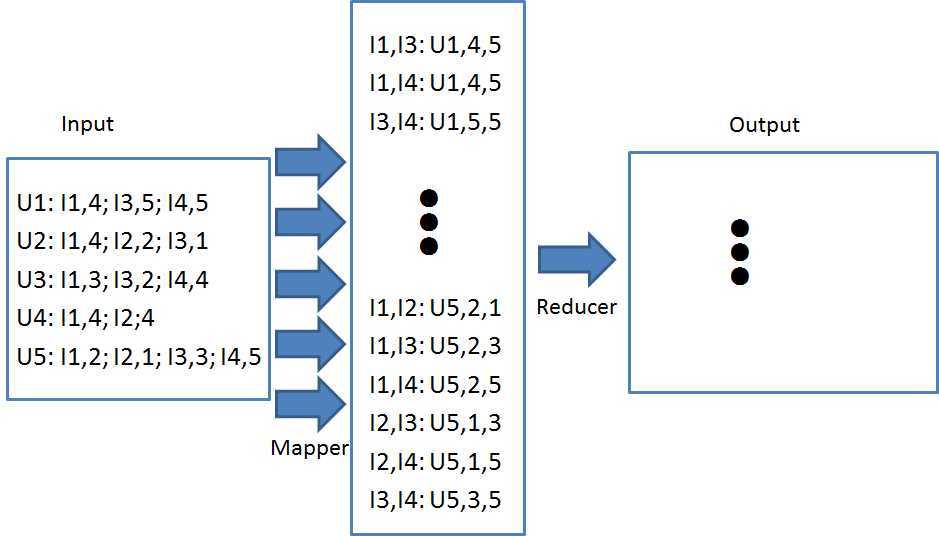
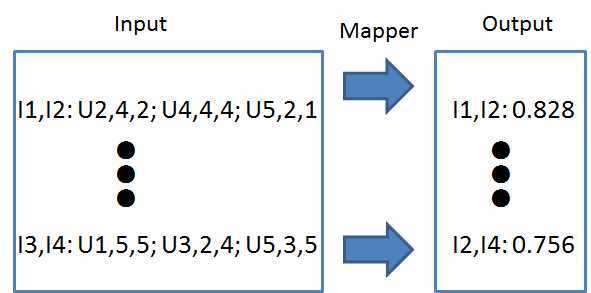
还是以上面的例子来介绍怎么用map-reduce的框架来计算item之间的相似性,整个计算过程采用两个map-reduce过程。
如下图所示,我们有三个用户1,2,3和四个电影A,B,C,D。用户1喜欢电影A和电影C,用户2喜欢电影B,用户3喜欢电影A,电影C和电影D。如果用户1和用户3很相似(同样,相似性也不是基于用户本身的DNA来计算的,后来再介绍),那么我们有理由预测用户1会喜欢电影D,因为用户1喜欢电影A和C,用户3喜欢电影A,C和D,而用户1和用户3又比较相似。这就是所谓的User-based。
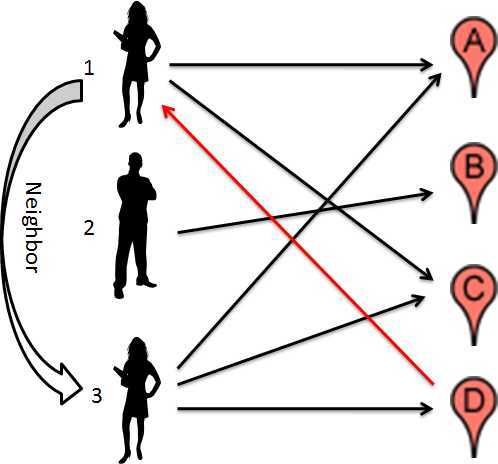
那么我们用这种算法怎么预测用户1对Item 2的评分呢?跟Item-based类似,我们先看看怎么计算两个用户之间的相似性:
$\Large s^{u,v}=\frac {\sum_{i \in I} (r^{u,i} - \overline{r^u}) (r^{v,i} - \overline{r^v}) } {\sqrt{ \sum_{i \in I} (r^{u,i} - \overline{r^u})^2 } \sqrt{ \sum_{i \in I} (r^{v,i} - \overline{r^v})^2 } } $
其中:
$I$为用户u,用户v同时评价过的Item集合
$\overline{r^u}$为用户 u 对 I 里所有 Item 评分的平均值
$\overline{r^v}$为用户 v 对 I 里所有 Item 评分的平均值
User-based的评分的预测公式与Item-based的评分预测公式稍微有点不一样:
$\Large p^{a,i} = \overline{r^a} + \frac {\sum_{u \in U} (r^{u,i} - \overline{r^u}) s^{a,u}} {\sum_{u \in U} |s^{a,u}|} $
其中:
$U$为所有评价过Item i 的用户集合
$\overline{r^a}$为用户 a 对所有他评价过的Item的评分的平均值
$\overline{r^u}$为用户 u 对所有他评价过的Item的评分的平均值(Item i 除外)
为什么User-based和Item-based的评分预测公式会有区别呢?主要是为了消除用户评分的bias,有的用户就是喜欢评低分,而有的用户习惯给高分。
那么,预测用户1在Item 2 上的评分的步骤为:
1. 找出评价过Item 2 的用户集合:用户2,用户4和用户5
2. 计算用户1和用户2,用户4,用户5之间的相似性
拿计算用户1和用户5的相似性为例:
2.1 找出用户1和用户5同时评价过的Item 集合I:Item 1,Item 3 和 Item 4
2.2 用户1在 I 上的平均分为4.67,用户5在I上的平均分为3.33,所以:
$\Large s^{1,5} = \frac {-0.67*-1.33 + 0.33 *0.33 + 0.33 * 1.67}{\sqrt {(-0.67)^2 + 0.33^2 + 0.33^2} \sqrt {(-1.33)^2 + 0.33^2 + 1.67^2}} = 0.756$
同理计算$s^{1,2}=-1,s^{1,4}=0$
3. 根据相似性和评分预测公式计算预测分
$\Large p^{1,2} = 4.67 + \frac {(2-2.5)*(-1) + (4-4)*0 + (1-3.33)*0.756}{1+0+0.756} = 3.95 $
Slope-one基于一种简单的假设,假设任意两个Item i 和 j 之间的评分存在某种线性关系,即知道了Item j 的评分,我们可以用线性公式来预测 Item i 的评分, $p^{u,i}= a r^{u,j}+b^{u,i,j}$,更进一步的假设斜率 $a=1$,这就是算法为什么叫Slope-one的原因。为了求得b,我们先定义一个平方损失函数:
$\large L(b^{i,j}) = \sum_{u \in U}(r^{u,i} - p^{u,i})^2 = \sum_{u \in U}(r^{u,i} - r^{u,j} - b)^2 $
其中:
$U$是同时评价过Item i 和 Item j 的用户集合。
最小化上面的损失函数得到:
$ \large b^{i,j} = \frac {\sum_{u \in U}(r^{u,i} - r^{u,j})} {\sum_{u \in U} 1} $
预测用户a对Item i 的评分预测公式为:
$\large p^{a,i} = \frac {\sum_{j \in I}(r^{a,j} + b^{i,j})} {\sum_{j \in I} 1} $
那么用Slope-one预测用户1在Item 2 上的评分步骤为:
1. 找到同时评价过Item 1 和Item 2的用户: 用户2,用户4和用户5
2. 计算Item 2 和 Item 1 的平均分差
$\large b^{2,1} = \frac {(2-4) + (4-4) +(1-2)} {3} = -1$
3. 仿照步骤1和步骤2计算
$\large b^{2,3} =-0.5, b^{2,4}=-4 $
4. 按照预测公式计算预测分
$\large p^{1,2} = \frac {(4-1) + (5-0.5) + (5-4)} {3} = 2.83 $
后来又演变出一种叫Weighted Slope-one的算法,它的思想和Slope-one一样,只是最后的评分预测公式加入了权重。
$\large p^{a,i} = \frac {\sum_{j \in I}(r^{a,j} + b^{i,j})c^{i,j}} {\sum_{j \in I} c^{i,j}} $
我们在上面计算 $b^{2,1}$的时候,是根据三个用户的共同评分计算出来的,而在计算$b^{2,3}$的时候,是根据两个用户的共同评分计算出来的,计算$b^{2,4}$的时候只根据了一个用户的评分。所以他们的权重分别是$c^{2,1}=3, c^{2,3}=2, c^{2,4}=1$,所以:
$\large p^{1,2} = \frac {(4-1)*3 + (5-0.5)*2 + (5-4)*1} {3+2+1} = 3.17 $
Item-based,User-based,Slope-one都各有优缺点。Item-based跟当前用户的行为相关,比如在浏览一部动作片的时候,推荐的结果可能就是另一部动作片,但在浏览一部爱情片的时候,推荐的结果可能就是一部爱情片。User-based考虑的相同爱好的用户群的兴趣,推荐这个用户群喜欢过的某个Item,与当前用户的行为关系不大,比如在浏览一部动作片或者爱情片的时候,推荐出来的结果可能都一样。Slope-one主要是计算起来比较方便,也可以增量计算,实现很简单。
思考一下:新闻推荐用User-based还是Item-based好?
另外,推荐的可解释性也是现在推荐系统非常强调的,比如你在浏览Amazon的时候,它的推荐都会给出“Why Recommended”的理由。Item-based和Content-based类似,能给出很好的解释,推荐的东西跟你现在浏览的东西相关,因为你在看Java编程思想,所以给你推荐Java相关的书籍。User-based的解释是说跟你趣味相投的某某也喜欢这个电影,但是你可能并不认识这个某某,所以很难让人信服。Slope-one就更没法给出合理的解释了。
未完待续
标签:style blog http io color ar os sp java
原文地址:http://www.cnblogs.com/dudi00/p/4093240.html