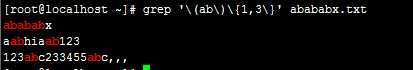grep [OPTION] ...‘PATTERN’ FILE...
[[:digit:]] = [0-9] 所有数字
[[:lower:]] = [a-z] 所有小写字母
[[:upper:]] = [A-Z] 所有大写字母
[[:alpha:]] = [a-zA-Z] 所有字母
[[:alnum:]] = [0-9a-zA-Z] 所有字母和数字
[[:space:]] 所有的换行符,空格符,制表符
[[:punct:]] 所有的标点符号
上例也可以这样输入命令
grep ‘r[[:alpha:]][[:alpha:]]t‘ /etc/passwd 也是一样的结果
[^] :匹配指定集合外的任意单个字符(和[]相反)
次数匹配:用于对其前面紧邻的字符所能够出现的次数作出限定。
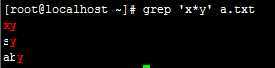
* :匹配其前面任意次,0,1或多次;
例:我们先创建个文件a.txt里面有xy sy aby abc字符的文件
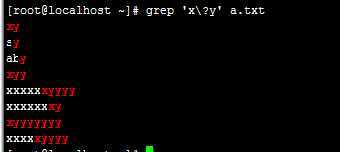
\? :匹配其前面出现的字符0次或1次
匹配其前面出现的字符只能出现一次,或者不出现
例:grep ‘x\?y‘ a.txt
注:匹配y其前面的x只能出现一次,或者不出现
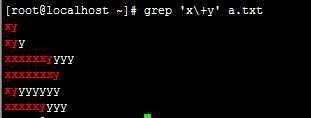
\+ 匹配其前面的字符出现至少一次;
例:
注:匹配x字符至少要出现一次。
\{m\} :匹配其前面的字符至少m次;
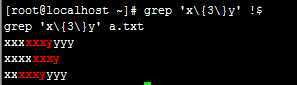
例:grep ‘x\{3\}y‘ !$
注:显示x至少出现3次,!$的意思是最近命令的参数
\{m,n\}:匹配其前面的字符至少m次,至多n次;
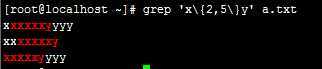
例: grep ‘x\{2,5\}y‘ a.txt
注:显示x至少出现2次,至多5次。是m-n次
.* :匹配任意长度的任意字符
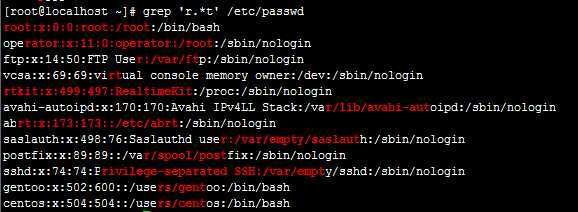
例:grep ‘r.*t‘ /etc/passwd
注:.是任意单个字符,*是任意字符次数 2个加起来就是任意字符任意次数
位置锚定:也就是位置锁定,指定其出现在什么位置上面
^ :行首锚定,必须出现在最左侧
例:grep ‘^r[[:alpha:]][[:alpha:]]t‘ /etc/passwd
注:[[:alpha:]]代表所有的字母,显示r为行首,中间2个所有字母的字符,t为尾部
$ :行尾锚定,必须出现在最右侧
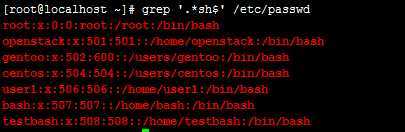
例:grep ‘.*sh$‘ /etc/passwd
注:显示sh结尾的所有行
^$ 空白行:行首与到行尾。
\<:词首锚定,
出现在要查找的单词模式的左侧:\<char
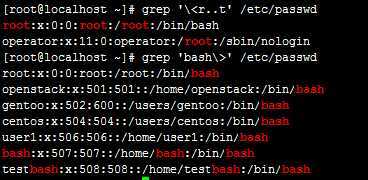
例:grep ‘\<r..t‘ /etc/passwd
注:匹配r是这个单词的词首,t是这个单词的词尾,..表示任意符号单个字符^表示行首。
\>:词尾锚定,也可以用\b
出现在要查找的单词模式的右侧:char\>
例:grep ‘bash\>‘ /etc/passwd
注:显示passwd文件中,所有单词bash在右侧的文件。
\<pattern\>:匹配单词 pattern类似于单词
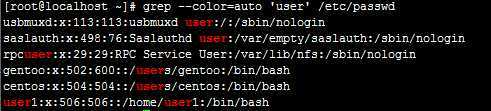
例:grep ‘\<user\>‘ /etc/passwd
注:上例显示\<\>中间字符的所有的行。
\<pattern\> 是\<词首锚定和\>词尾锚定,中间加个单词的组合。这代表一个单词
分组:\(\) 在bash中{}(花括号),()小括号也有特殊意思,所以在这里需要用\做转意符
\{m,n\} 是次数锚定的 最少为m次,最多n次
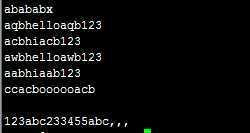
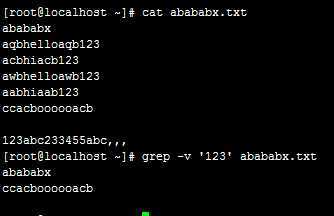
例:abababx.txt文件中有下列字符
输入命令:grep ‘\(ab\)\{1,3\}‘ abababx.txt
注:此显示ab循环 \(ab\)为最少一次最多3次\{1,3\}的行
后向引用:模式中,如果使用\(\)实现了分组,在某行文本的检查中,如果括号中的模式匹配到了某内容,次内容后面的模式中可以被引用;
\1,\2,\3 第一个括号,第二个括号,第三个括号
模式自左而右,引用第#个左括号以及与其匹配右括号之间的模式匹配到的内容。
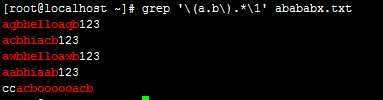
例:grep ‘\(a.b\).*\1‘ abababx.txt
注:(a.b):是a开头中间跟任意字符,b结尾
.* :任意字符任意长度
显示含(a.b),中间可以是.*,但后面还含有(a,b)的所有行
grep选项:
-v:反向选取;总体反向选取。
例:abababx.txt有下列文件,输入命令grep -v ‘123‘ abababx.txt后。查看abababx.txt文件中不包含123的行,空白行也算。
-o:仅显示匹配到的内容
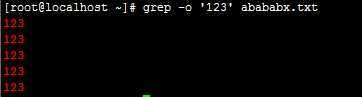
例:grep -o ‘123‘ abababx.txt
注:显示查找到的123,并且就显示123
-i:忽略字符大小写
-E:使用扩展正则表达式
-A #:显示查找的到文件并显示下面#行
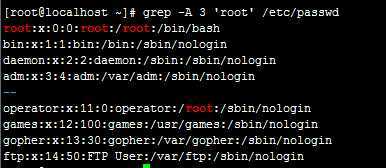
例:grep -A 3 ‘root‘ /etc/passwd
注:查找含root的的行并显示其下面3行,查找到第二个用--隔开并继续显示下面3行
-B #:显示上面#行
-C #:显示上下#行