标签:style blog http io ar os 使用 sp for
KDDCUP - Competition is a strong mover for Science and Engineering
ACM KDD是知识发现和数据挖掘领域的顶级会议,KDD CUP又是基于ACM KDD的世界级赛事。目的在于1. 探求从海量数据中挖掘出高层知识的最佳方法。2. 作为学术界和工业界沟通的桥梁(事实上KDD从97起,首先是由工业界如yahoo,美国国防部发起,参与并获奖的也是SAS,SAP等一些企业,后来学术界渐渐参与进来,比如lib-SVM 的发明者CJ Lin。 3. 促进知识发现和数据挖掘领域的进一步发展。
KDD-CUP 从97年起至今历经15届,每年的二月份在官方网站(http://www.kdd.org/kdd2012/kddcup.shtml)上给出题目,二月份之前都在call for proposal.阶段,下面一些统计指标统计

这是最终提交答案的参赛者的数量,从发起至今就不断有人参与,一般都是以团队的形式。数据集不断增大,而运行速度要求增加。对所运用的机器学习模型的要求也不断提高,下面是2000年之前用到的机器学习的算法。
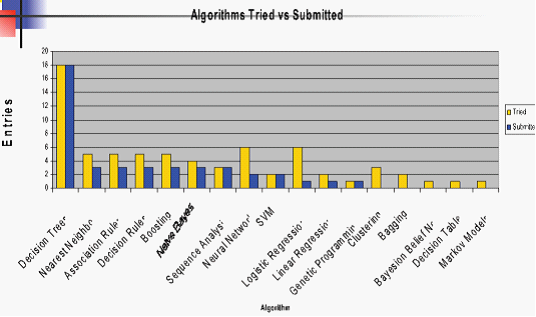
传统的算法如boosting, Decision Tree Nearest Neighbour , association rule(关联规则)等占大多数。事实上2003年起一些Social的数据逐渐进来(估计是Face book,Netfix等社交网站相继创立),社会网络,协同推荐等算法逐渐popular。这是后话。KDD-cup的工作量非常大,一般是成几个月得的在搞,一般人均所用时间达204个小时,最大人均所用时间为910小时,但付出的同时收获也很大。
KDD-CUP 97 -98 都和 CRM 客户关系管理有关,97年的题目是邮件准确得send给有需求的客户,数据集均由工业界一些企业或者机构提供。99年是美国国防部出给出的有效检测网络攻击的问题,即如何识别一些操作是属于内部正常使用行为还是来自外部入侵,这一年的Winner 是著名的SAS公司。
KDD-CUP 2000 采纳了Gazelle.com的题目,Gazelle.com是一家女性奢侈用品的网络零售商。数据信息由点击流信息和购买数据组成。Target有以下几点1 识别哪些用户会花很多钱买很多商品,2 识别重要的页面 3 挖掘访问者可能会关注的品牌。 其目的在于使网站更加个性化,并提高该网站的访问量来增加盈利。 Winner使用的好像是关联规则挖掘。 后来再访问这个网站会很让人有些失望,因为它已经堕落去卖一些旧货了。至少他没有很好得去利用这次竞赛的成果。
KDD Cup 2001 是一个生物学机器学习的问题。值得关注的是从这一年起,数据量(half a gigabyte when uncompressed)和参赛人数(A total of 136 groups participated )增加非常多
Task 1的获胜者Jie Cheng用的是贝叶斯网络学习分类器,Task 2 用的是Inductive Logic programming。 Task 3 用的是KNN算法。 可以看出传统的ML算法还是占主导地位,还是足够应付一些问题的。 KDD-CUP 2002年也是生物学领域的两个任务,一个是Document extraction from biological articles ,TASK 2 是基于基因删除实验的蛋白质分类问题。
KDD-CUP 2003 复杂网络的挖掘开始成为主题,1)the first Task是预测KDD2003会议举行前三个月,每篇paper会receive 多少citation; 2) Task 2 是要求参赛者构建一个只来源于LaTex的大规模文档集的citation graph. 3)最后一个Task是根据一些部分的下载日志去预测相关paper的popularity. (是一个开放性问题)。如上,这一年的topic非常有趣,复杂网络挖掘(社会网络,引文网络)被引进机器学习和数据挖掘的领域,开启了之后05-11年用ML算法去解决社会网络和协同推荐问题的热潮。这一年获奖者大多来自学术界。如NYU
KDD-CUP 2004 又是一个生物学预测问题。冠军是HKUST的杨强团队,他也是KDD-CUP 2012(BJ)的General Chair。
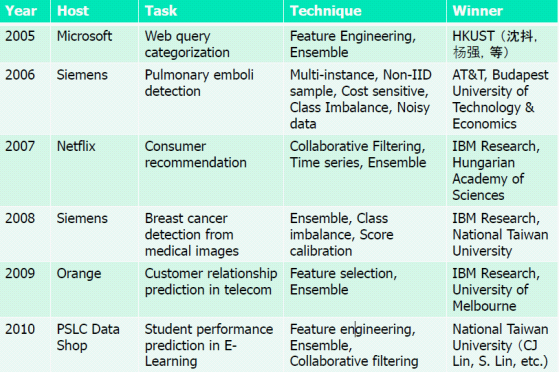
下面是2005-2010年的KDD-CUP 相关信息的统计
值得关注的是,随着KDD-CUP的影响力和难度质量的提高,一些获奖者会成为一些大公司的青睐对象,像05年HKUST的沈抖就被微软总部挖走,扬威也被山景城的Google挖过去了,再到后来11年中科院的项亮也加入了美国视频推荐网站hulu。07年是又是一个协同推荐的customer recommendation的TASK,出题者Netfix是美国一个租电影的社交网站。08年是西门子出题,题目是怎样从拍摄的医学图像中检测出乳腺癌,这也和Siemens公司最为盈利的Health Care市场相关(它是很多医疗检测仪器的提供商)。有意思的一点是07-09年,这三年的Winner都是IBM Research团队(其实这是由于当时IBM 研究院调集了一帮精兵强将去搞人工智能的watson问答系统,即是后来在jeopardy中战胜人类的watson机器人)。于是到了2010年,按照机器学习的思维,似乎可以预测获奖者很可能又是IBM, 所以chair board的专家一致决定这一年让IBM Research出题,这回总不可能参加了吧。(joking.....)。
10年是关于Student Performance prediction in E-learning,也是一个很有意思的topic,获奖者是著名的CJ Lin林志仁教授。有意思的是,这一年获奖的人数竟然一张纸都写不下,这是因为聪明且搞笑的林志仁教授把这个题目当做了他教授的一门课的课程作业!所以是一个班的同学集体参加的。。。。06年的题目很一般,但是用于training和测试 的data却出现严重的问题,最后发现前面一半的ID 都是正样本,后面一半都是负样本,所以后处理根据ID来会讨巧很多,所以本来的竞赛题变得毫无技术含量。导致委员会最后很不情愿颁奖并给出奖金,但是这连同后续也有几次的纰漏使后处理往往能提高很多performance,却揭示了机器学习中存在的一个不容忽视的问题,即数据集不够严密不够完美。所以后来有一年获得SIGKDD最佳论文奖的paper就是阐述的有关data leakage 的问题。
2011年 KDD-CUP 的题目是有关音乐推荐的主题。是一个非常经典的社会网络和协同过滤的推荐问题。获奖者项亮博士对他的解决方案在ppt中做了介绍,他做了大量工作,大概用了14种模型,包括initial BN,KNN,jaccard index,再到深化的问题,创新的解决了两个问题1)Item-based 协同推荐中点击时间的一个影响temporal influence 2)规避社会化推荐中的哈利波特效应,所谓哈利波特效应,源于amazon做推荐系统研究,发现几乎每一个用户都会和哈利波特这本书建立很大相关度,而他认为推荐的意义在于使人们发现那条长尾,而不是已有的热点,如何消除或者弱化热点的影响,他采用了相关的方法见PDF。
另外两篇文章是Learning Online Discussion Structures by Conditional Random Fields(ChengXiang Zhai, Jiawei Han)是SIGIR 2011年的paper,几乎UIUC巨牛逼的教授都一齐上阵了,含金量也算可以。另外一篇Mining Heterogeneous Information Networks也可以读下.
标签:style blog http io ar os 使用 sp for
原文地址:http://www.cnblogs.com/abc8023/p/4100391.html