标签:style blog http io color ar os sp java
我参照的前辈的文章http://blog.fens.me/hadoop-mapreduce-log-kpi/
从1.x改到了2.x。虽然没什么大改。(说实话,视频没什么看的,看文章最好)
先用maven构建hadoop项目
下载maven、添加环境变量、替换eclipse默认maven配置、修改maven默认库位置... ...

这里没有像前辈一样用maven命令去新建一个maven项目,直接用eclipse这个方便IDE就行了
重要的pom.xml添加依赖
1 <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" 2 xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> 3 <modelVersion>4.0.0</modelVersion> 4 5 <groupId>org.admln</groupId> 6 <artifactId>getKPI</artifactId> 7 <version>0.0.1-SNAPSHOT</version> 8 <packaging>jar</packaging> 9 10 <name>getKPI</name> 11 <url>http://maven.apache.org</url> 12 13 <properties> 14 <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> 15 </properties> 16 17 <dependencies> 18 <dependency> 19 <groupId>junit</groupId> 20 <artifactId>junit</artifactId> 21 <version>4.4</version> 22 <scope>test</scope> 23 </dependency> 24 <dependency> 25 <groupId>org.apache.hadoop</groupId> 26 <artifactId>hadoop-common</artifactId> 27 <version>2.2.0</version> 28 </dependency> 29 <dependency> 30 <groupId>org.apache.hadoop</groupId> 31 <artifactId>hadoop-mapreduce-client-core</artifactId> 32 <version>2.2.0</version> 33 </dependency> 34 <dependency> 35 <groupId>org.apache.hadoop</groupId> 36 <artifactId>hadoop-mapreduce-client-common</artifactId> 37 <version>2.2.0</version> 38 </dependency> 39 <dependency> 40 <groupId>org.apache.hadoop</groupId> 41 <artifactId>hadoop-hdfs</artifactId> 42 <version>2.2.0</version> 43 </dependency> 44 <dependency> 45 <groupId>jdk.tools</groupId> 46 <artifactId>jdk.tools</artifactId> 47 <version>1.7</version> 48 <scope>system</scope> 49 <systemPath>${JAVA_HOME}/lib/tools.jar</systemPath> 50 </dependency> 51 </dependencies> 52 </project>
然后让maven下载jar包就行了(第一次下载很多很慢,以后就不用下载,快的很了)
然后就是MR了。
这个MR的任务就是根据日志提取一些KPI指标。
日志格式:
1 222.68.172.190 - - [18/Sep/2013:06:49:57 +0000] "GET /images/my.jpg HTTP/1.1" 200 19939 2 "http://www.angularjs.cn/A00n" "Mozilla/5.0 (Windows NT 6.1) 3 AppleWebKit/537.36 (KHTML, like Gecko) Chrome/29.0.1547.66 Safari/537.36"
有用的变量:
KPI目标:
具体MR:
KPI.java
1 package org.admln.kpi; 2 3 import java.text.ParseException; 4 import java.text.SimpleDateFormat; 5 import java.util.Date; 6 import java.util.HashSet; 7 import java.util.Locale; 8 import java.util.Set; 9 10 /** 11 * @author admln 12 * 13 */ 14 public class KPI { 15 private String remote_addr;// 记录客户端的ip地址 16 private String remote_user;// 记录客户端用户名称,忽略属性"-" 17 private String time_local;// 记录访问时间与时区 18 private String request;// 记录请求的url与http协议 19 private String status;// 记录请求状态;成功是200 20 private String body_bytes_sent;// 记录发送给客户端文件主体内容大小 21 private String http_referer;// 用来记录从那个页面链接访问过来的 22 private String http_user_agent;// 记录客户浏览器的相关信息 23 24 private boolean valid = true;// 判断数据是否合法 25 26 27 public static KPI parser(String line) { 28 KPI kpi = new KPI(); 29 String [] arr = line.split(" "); 30 if(arr.length>11) { 31 kpi.setRemote_addr(arr[0]); 32 kpi.setRemote_user(arr[1]); 33 kpi.setTime_local(arr[3].substring(1)); 34 kpi.setRequest(arr[6]); 35 kpi.setStatus(arr[8]); 36 kpi.setBody_bytes_sent(arr[9]); 37 kpi.setHttp_referer(arr[10]); 38 39 if(arr.length>12) { 40 kpi.setHttp_user_agent(arr[11]+" "+arr[12]); 41 }else { 42 kpi.setHttp_user_agent(arr[11]); 43 } 44 45 if(Integer.parseInt(kpi.getStatus())>400) { 46 kpi.setValid(false); 47 } 48 49 }else { 50 kpi.setValid(false); 51 } 52 53 return kpi; 54 55 } 56 public static KPI filterPVs(String line) { 57 KPI kpi = parser(line); 58 Set pages = new HashSet(); 59 pages.add("/about"); 60 pages.add("/black-ip-list/"); 61 pages.add("/cassandra-clustor/"); 62 pages.add("/finance-rhive-repurchase/"); 63 pages.add("/hadoop-family-roadmap/"); 64 pages.add("/hadoop-hive-intro/"); 65 pages.add("/hadoop-zookeeper-intro/"); 66 pages.add("/hadoop-mahout-roadmap/"); 67 68 if (!pages.contains(kpi.getRequest())) { 69 kpi.setValid(false); 70 } 71 return kpi; 72 } 73 74 public String getRemote_addr() { 75 return remote_addr; 76 } 77 78 public void setRemote_addr(String remote_addr) { 79 this.remote_addr = remote_addr; 80 } 81 82 public String getRemote_user() { 83 return remote_user; 84 } 85 86 public void setRemote_user(String remote_user) { 87 this.remote_user = remote_user; 88 } 89 90 public String getTime_local() { 91 return time_local; 92 } 93 94 public Date getTime_local_Date() throws ParseException { 95 SimpleDateFormat df = new SimpleDateFormat("dd/MMM/yyyy:HH:mm:ss",Locale.US); 96 return df.parse(this.time_local); 97 } 98 //为了以小时为单位统计数据 99 public String getTime_local_Date_Hour() throws ParseException { 100 SimpleDateFormat df = new SimpleDateFormat("yyyyMMddHH"); 101 return df.format(this.getTime_local_Date()); 102 } 103 104 public void setTime_local(String time_local) { 105 this.time_local = time_local; 106 } 107 108 public String getRequest() { 109 return request; 110 } 111 112 public void setRequest(String request) { 113 this.request = request; 114 } 115 116 public String getStatus() { 117 return status; 118 } 119 120 public void setStatus(String status) { 121 this.status = status; 122 } 123 124 public String getBody_bytes_sent() { 125 return body_bytes_sent; 126 } 127 128 public void setBody_bytes_sent(String body_bytes_sent) { 129 this.body_bytes_sent = body_bytes_sent; 130 } 131 132 public String getHttp_referer() { 133 return http_referer; 134 } 135 136 public void setHttp_referer(String http_referer) { 137 this.http_referer = http_referer; 138 } 139 140 public String getHttp_user_agent() { 141 return http_user_agent; 142 } 143 144 public void setHttp_user_agent(String http_user_agent) { 145 this.http_user_agent = http_user_agent; 146 } 147 148 public boolean isValid() { 149 return valid; 150 } 151 152 public void setValid(boolean valid) { 153 this.valid = valid; 154 } 155 }
KPIBrowser.java
1 package org.admln.kpi; 2 3 import java.io.IOException; 4 5 import org.apache.hadoop.conf.Configuration; 6 import org.apache.hadoop.fs.Path; 7 import org.apache.hadoop.io.IntWritable; 8 import org.apache.hadoop.mapreduce.Job; 9 import org.apache.hadoop.mapreduce.Mapper; 10 import org.apache.hadoop.mapreduce.Reducer; 11 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 12 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 13 import org.apache.hadoop.io.Text; 14 15 /** 16 * @author admln 17 * 18 */ 19 public class KPIBrowser { 20 21 public static class browserMapper extends Mapper<Object,Text,Text,IntWritable> { 22 Text word = new Text(); 23 IntWritable ONE = new IntWritable(1); 24 @Override 25 public void map(Object key,Text value,Context context) throws IOException, InterruptedException { 26 KPI kpi = KPI.parser(value.toString()); 27 if(kpi.isValid()) { 28 word.set(kpi.getHttp_user_agent()); 29 context.write(word, ONE); 30 } 31 } 32 } 33 34 public static class browserReducer extends Reducer<Text,IntWritable,Text,IntWritable> { 35 int sum; 36 public void reduce(Text key,Iterable<IntWritable> values,Context context) throws IOException, InterruptedException { 37 sum = 0; 38 for(IntWritable val : values) { 39 sum += val.get(); 40 } 41 context.write(key, new IntWritable(sum)); 42 } 43 } 44 45 public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { 46 Path input = new Path("hdfs://hadoop:9001/fens/kpi/input/"); 47 Path output = new Path("hdfs://hadoop:9001/fens/kpi/browser/output"); 48 49 Configuration conf = new Configuration(); 50 51 @SuppressWarnings("deprecation") 52 Job job = new Job(conf,"get KPI Browser"); 53 54 job.setJarByClass(KPIBrowser.class); 55 56 job.setMapperClass(browserMapper.class); 57 job.setCombinerClass(browserReducer.class); 58 job.setReducerClass(browserReducer.class); 59 60 job.setOutputKeyClass(Text.class); 61 job.setOutputValueClass(IntWritable.class); 62 63 FileInputFormat.addInputPath(job,input); 64 FileOutputFormat.setOutputPath(job,output); 65 66 System.exit(job.waitForCompletion(true)?0:1); 67 68 } 69 }
KPIIP.java
1 package org.admln.kpi; 2 3 import java.io.IOException; 4 import java.util.HashSet; 5 import java.util.Set; 6 7 import org.apache.hadoop.conf.Configuration; 8 import org.apache.hadoop.fs.Path; 9 import org.apache.hadoop.io.Text; 10 import org.apache.hadoop.mapreduce.Job; 11 import org.apache.hadoop.mapreduce.Mapper; 12 import org.apache.hadoop.mapreduce.Reducer; 13 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 14 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 15 16 /** 17 * @author admln 18 * 19 */ 20 public class KPIIP { 21 //map类 22 public static class ipMapper extends Mapper<Object,Text,Text,Text> { 23 private Text word = new Text(); 24 private Text ips = new Text(); 25 26 @Override 27 public void map(Object key,Text value,Context context) throws IOException, InterruptedException { 28 KPI kpi = KPI.parser(value.toString()); 29 if(kpi.isValid()) { 30 word.set(kpi.getRequest()); 31 ips.set(kpi.getRemote_addr()); 32 context.write(word, ips); 33 } 34 } 35 } 36 37 //reduce类 38 public static class ipReducer extends Reducer<Text,Text,Text,Text> { 39 private Text result = new Text(); 40 private Set<String> count = new HashSet<String>(); 41 42 public void reduce(Text key,Iterable<Text> values,Context context) throws IOException, InterruptedException { 43 44 for (Text val : values) { 45 count.add(val.toString()); 46 } 47 result.set(String.valueOf(count.size())); 48 context.write(key, result); 49 } 50 } 51 52 public static void main(String[] args) throws Exception { 53 Path input = new Path("hdfs://hadoop:9001/fens/kpi/input/"); 54 Path output = new Path("hdfs://hadoop:9001/fens/kpi/ip/output"); 55 56 Configuration conf = new Configuration(); 57 58 @SuppressWarnings("deprecation") 59 Job job = new Job(conf,"get KPI IP"); 60 job.setJarByClass(KPIIP.class); 61 62 job.setMapperClass(ipMapper.class); 63 job.setCombinerClass(ipReducer.class); 64 job.setReducerClass(ipReducer.class); 65 66 job.setOutputKeyClass(Text.class); 67 job.setOutputValueClass(Text.class); 68 69 FileInputFormat.addInputPath(job,input); 70 FileOutputFormat.setOutputPath(job,output); 71 System.exit(job.waitForCompletion(true)?0:1); 72 73 } 74 }
KPIPV.java
1 package org.admln.kpi; 2 3 import java.io.IOException; 4 5 import org.apache.hadoop.conf.Configuration; 6 import org.apache.hadoop.fs.Path; 7 import org.apache.hadoop.io.IntWritable; 8 import org.apache.hadoop.io.Text; 9 import org.apache.hadoop.mapreduce.Job; 10 import org.apache.hadoop.mapreduce.Mapper; 11 import org.apache.hadoop.mapreduce.Reducer; 12 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 13 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 14 15 /** 16 * @author admln 17 * 18 */ 19 public class KPIPV { 20 21 public static class pvMapper extends Mapper<Object,Text,Text,IntWritable> { 22 private Text word = new Text(); 23 private final static IntWritable ONE = new IntWritable(1); 24 25 public void map(Object key,Text value,Context context) throws IOException, InterruptedException { 26 KPI kpi = KPI.filterPVs(value.toString()); 27 if(kpi.isValid()) { 28 word.set(kpi.getRequest()); 29 context.write(word, ONE); 30 } 31 } 32 } 33 34 public static class pvReducer extends Reducer<Text,IntWritable,Text,IntWritable> { 35 IntWritable result = new IntWritable(); 36 public void reduce(Text key,Iterable<IntWritable> values,Context context) throws IOException, InterruptedException { 37 int sum = 0; 38 for (IntWritable val : values) { 39 sum += val.get(); 40 } 41 result.set(sum); 42 context.write(key,result); 43 } 44 } 45 46 public static void main(String[] args) throws Exception { 47 Path input = new Path("hdfs://hadoop:9001/fens/kpi/input/"); 48 Path output = new Path("hdfs://hadoop:9001/fens/kpi/pv/output"); 49 50 Configuration conf = new Configuration(); 51 52 @SuppressWarnings("deprecation") 53 Job job = new Job(conf,"get KPI PV"); 54 55 job.setJarByClass(KPIPV.class); 56 57 job.setMapperClass(pvMapper.class); 58 job.setCombinerClass(pvReducer.class); 59 job.setReducerClass(pvReducer.class); 60 61 job.setOutputKeyClass(Text.class); 62 job.setOutputValueClass(IntWritable.class); 63 64 FileInputFormat.addInputPath(job,input); 65 FileOutputFormat.setOutputPath(job,output); 66 67 System.exit(job.waitForCompletion(true)?0:1); 68 69 } 70 71 }
KPISource.java
1 package org.admln.kpi; 2 3 import java.io.IOException; 4 5 import org.apache.hadoop.conf.Configuration; 6 import org.apache.hadoop.fs.Path; 7 import org.apache.hadoop.io.IntWritable; 8 import org.apache.hadoop.io.Text; 9 import org.apache.hadoop.mapreduce.Job; 10 import org.apache.hadoop.mapreduce.Mapper; 11 import org.apache.hadoop.mapreduce.Reducer; 12 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 13 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 14 15 /** 16 * @author admln 17 * 18 */ 19 public class KPISource { 20 21 public static class sourceMapper extends Mapper<Object,Text,Text,IntWritable> { 22 Text word = new Text(); 23 IntWritable ONE = new IntWritable(1); 24 @Override 25 public void map(Object key,Text value,Context context) throws IOException, InterruptedException { 26 KPI kpi = KPI.parser(value.toString()); 27 if(kpi.isValid()) { 28 word.set(kpi.getHttp_referer()); 29 context.write(word, ONE); 30 } 31 } 32 } 33 34 public static class sourceReducer extends Reducer<Text,IntWritable,Text,IntWritable> { 35 int sum; 36 public void reduce(Text key,Iterable<IntWritable> values,Context context) throws IOException, InterruptedException { 37 sum = 0; 38 for(IntWritable val : values) { 39 sum += val.get(); 40 } 41 context.write(key, new IntWritable(sum)); 42 } 43 } 44 45 public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { 46 Path input = new Path("hdfs://hadoop:9001/fens/kpi/input/"); 47 Path output = new Path("hdfs://hadoop:9001/fens/kpi/source/output"); 48 49 Configuration conf = new Configuration(); 50 51 @SuppressWarnings("deprecation") 52 Job job = new Job(conf,"get KPI Source"); 53 54 job.setJarByClass(KPISource.class); 55 56 job.setMapperClass(sourceMapper.class); 57 job.setCombinerClass(sourceReducer.class); 58 job.setReducerClass(sourceReducer.class); 59 60 job.setOutputKeyClass(Text.class); 61 job.setOutputValueClass(IntWritable.class); 62 63 FileInputFormat.addInputPath(job,input); 64 FileOutputFormat.setOutputPath(job,output); 65 66 System.exit(job.waitForCompletion(true)?0:1); 67 } 68 }
KPITime.java
1 package org.admln.kpi; 2 3 import java.io.IOException; 4 import java.text.ParseException; 5 6 import org.apache.hadoop.conf.Configuration; 7 import org.apache.hadoop.fs.Path; 8 import org.apache.hadoop.io.IntWritable; 9 import org.apache.hadoop.io.Text; 10 import org.apache.hadoop.mapreduce.Job; 11 import org.apache.hadoop.mapreduce.Mapper; 12 import org.apache.hadoop.mapreduce.Reducer; 13 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 14 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 15 16 /** 17 * @author admln 18 * 19 */ 20 public class KPITime { 21 22 public static class timeMapper extends Mapper<Object,Text,Text,IntWritable> { 23 Text word = new Text(); 24 IntWritable ONE = new IntWritable(1); 25 @Override 26 public void map(Object key,Text value,Context context) throws IOException, InterruptedException { 27 KPI kpi = KPI.parser(value.toString()); 28 if(kpi.isValid()) { 29 try { 30 word.set(kpi.getTime_local_Date_Hour()); 31 } catch (ParseException e) { 32 e.printStackTrace(); 33 } 34 context.write(word, ONE); 35 } 36 } 37 } 38 39 public static class timeReducer extends Reducer<Text,IntWritable,Text,IntWritable> { 40 int sum; 41 public void reduce(Text key,Iterable<IntWritable> values,Context context) throws IOException, InterruptedException { 42 sum = 0; 43 for(IntWritable val : values) { 44 sum += val.get(); 45 } 46 context.write(key, new IntWritable(sum)); 47 } 48 } 49 50 public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { 51 Path input = new Path("hdfs://hadoop:9001/fens/kpi/input/"); 52 Path output = new Path("hdfs://hadoop:9001/fens/kpi/time/output"); 53 54 Configuration conf = new Configuration(); 55 56 @SuppressWarnings("deprecation") 57 Job job = new Job(conf,"get KPI Time"); 58 59 job.setJarByClass(KPITime.class); 60 61 job.setMapperClass(timeMapper.class); 62 job.setCombinerClass(timeReducer.class); 63 job.setReducerClass(timeReducer.class); 64 65 job.setOutputKeyClass(Text.class); 66 job.setOutputValueClass(IntWritable.class); 67 68 FileInputFormat.addInputPath(job,input); 69 FileOutputFormat.setOutputPath(job,output); 70 71 System.exit(job.waitForCompletion(true)?0:1); 72 73 } 74 75 }
其实五个MR都差不多,都是WordCount稍作改变。(前辈好像写的有点小错误,被我发现改了)
hadoop环境是:hadoop2.2.0;JDK1.7;虚拟机伪分布式;IP 192.168.111.132。
具体效果:
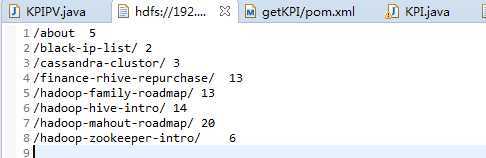
这里前辈是把指定目录提取出来了。实际情况可以根据自己的需求提取指定页面。
具体代码和日志文件:http://pan.baidu.com/s/1qW5D63M
实验日志数据也可以从别的地方获得来练手,比如搜狗http://www.sogou.com/labs/dl/q.html

不当之处期盼喷正。
标签:style blog http io color ar os sp java
原文地址:http://www.cnblogs.com/admln/p/InAciton-logKPI.html