标签:style blog class code c java
说明
MapReduce原理
如果block的大小默认是64MB,假设输入文件有两个,一个32MB,一个72MB,则小的文件时一个输入片,大文件会分为两个数据块,是两个输入片,一共三个输入片每一个输入片由一个Mapper进程处理,所以一共三个Mapper进程处理
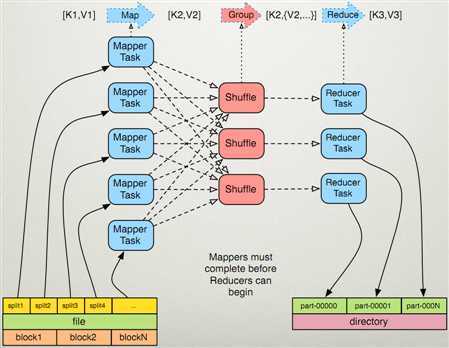
MapReduce执行流程
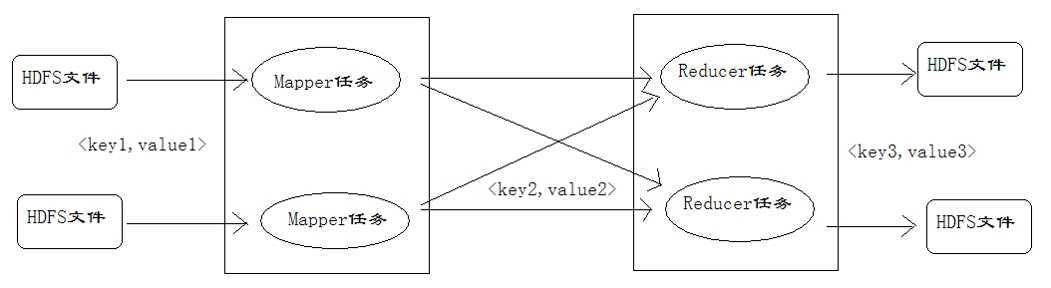
运行时通过Mapper读取HDFS文件,执行自己的方法,最后输出到HDFS文件中
hadoop中,map函数位于内置类org.apache.hadoop.mapreduce.Mapper<KEYIN,VALUEIN,KEYOUT,VALUEOUT>中(Mapper.java 122行)
reduce函数位于内置类org.apache.hadoop.mapreduce.Reducer<KEYIN,VALUEIN,KEYOUT,VALUEOUT>中(Reducer.java 153行)
JobTracker和TaskTracker
Mapper 和 Reducer
具体分为下面6个阶段:
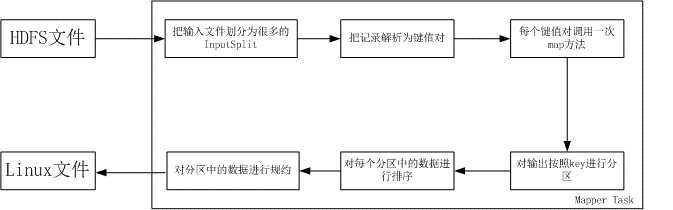
- 第一阶段是把输入文件按照一定的标准分片(InputSplit),每个输入片的大小是固定的。默认情况下,输入片(InputSplit)的大小与数据块(Block)的大小是相同的。如果数据块(Block)的大小是默认值64MB,输入文件有两个,一个是32MB,一个是72MB。那么小的文件是一个输入片,大文件会分为两个数据块,那么是两个输入片。一共产生三个输入片。每一个输入片由一个Mapper 进程处理。这里的三个输入片,会有三个Mapper 进程处理。
- 第二阶段是对输入片中的记录按照一定的规则解析成键值对。有个默认规则是把每一行文本内容解析成键值对。“键”是每一行的起始位置(单位是字节),“值”是本行的文本内容。
- 第三阶段是调用Mapper 类中的map 方法。第二阶段中解析出来的每一个键值对,调用一次map 方法。如果有1000 个键值对,就会调用1000 次map 方法。每一次调用map 方法会输出零个或者多个键值对。
- 第四阶段是按照一定的规则对第三阶段输出的键值对进行分区。比较是基于键进行的。比如我们的键表示省份(如北京、上海、山东等),那么就可以按照不同省份进行分区,同一个省份的键值对划分到一个区中。默认是只有一个区。分区的数量就是Reducer 任务运行的数量。默认只有一个Reducer 任务。
- 第五阶段是对每个分区中的键值对进行排序。首先,按照键进行排序,对于键相同的键值对,按照值进行排序。比如三个键值对<2,2>、<1,3>、<2,1>,键和值分别是整数。那么排序后的结果是<1,3>、<2,1>、<2,2>。如果有第六阶段,那么进入第六阶段;如果没有,直接输出到本地的linux文件中。
- 第六阶段是对数据进行归约处理,也就是reduce 处理。键相等的键值对会调用一次reduce 方法。经过这一阶段,数据量会减少。归约后的数据输出到本地的linxu文件中。本阶段默认是没有的,需要用户自己增加这一阶段的代码。
过程如下:
- 第一阶段是Reducer 任务会主动从Mapper 任务复制其输出的键值对。Mapper 任务可能会有很多,因此Reducer 会复制多个Mapper 的输出。
- 第二阶段是把复制到Reducer 本地数据,全部进行合并,即把分散的数据合并成一个大的数据。再对合并后的数据排序。
- 第三阶段是对排序后的键值对调用reduce 方法。键相等的键值对调用一次reduce 方法,每次调用会产生零个或者多个键值对。最后把这些输出的键值对写入到HDFS 文件中。
接口

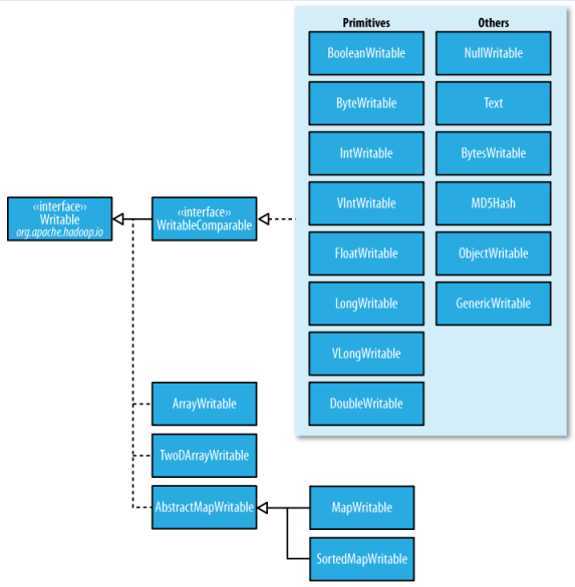
1. MapReduce的任意Key和Value必须实现Writable接口.
2. 两个方法 write和readFileds方法
write方法将对象序列化到DataOutput中
readFields从DataInput中将对象反序列化到对象的属性中
3.常用的writable实现类:(其中Text类似于java.lang.String)
- TextOutputformat
默认的输出格式,key和value中间值用tab隔开的。
- SequenceFileOutputformat
将key和value以sequencefile格式输出。
- SequenceFileAsOutputFormat
将key和value以原始二进制的格式输出。
- MapFileOutputFormat
将key和value写入MapFile中。由于MapFile中的key是有序的,所以写入的时候必须保证记录是按key值顺序写入的。
- MultipleOutputFormat
默认情况下一个reducer会产生一个输出,但是有些时候我们想一个reducer产生多个输出,MultipleOutputFormat和MultipleOutputs可以实现这个功能。
简单例子:wordcount

public static class MyMapper extends Mapper<LongWritable,Text,Text,IntWritable>{ final Text key2=new Text();//key2,表示该行中的单词 final IntWritable value2=new IntWritable(1);//value2,表示单词在该行的出现次数 //key,表示文本行的起始位置;value,表示文本行 protected void map(LongWritable key,Text value,Context context)throws java.io.IOException,InterruptedException{ final String[] splited=value.toString().split(" ");//把文本内容按照空格分割 for(String word:splited){ key2.set(word); //把key2、value2写入到上下文context中 context.write(key2,value2);//每个单词作为新的键,数值1作为新的值,这里输出的是每个单词,所以出现次数是常量1 } } }
public static class MyReducer extends Reducer<Text,IntWritable,Text,IntWritable >{ final IntWritable value3=new IntWritable(0);//key3,表示单词出现的总次数 //key表示单词,values表示map方法输出的1的集合,context为上下文对象 protected void reduce(Text key,java.lang.Iterable<IntWritable> values,Context context)throws java.io.IOException,InterruptedException{ int sum=0; for(IntWritable count:values){ sum+=count.get(); }//执行到这里,sum表示该单词出现的总次数 //key3表示单词,是最后输出的key final Text key3=key; //value3表示单词出现的总次数,是最后出现的value value3.set(sum); context.write(key3,value3); } }
public static void main(String[] args) throws IOException,InterruptedException,ClassNotFoundException{ // TODO Auto-generated method stub final String INPUT_PATH="hdfs://hadoop:9000/input";//输入路径 final String OUTPUT_PATH="hdfs://hadoop:9000/output";//输出路径,必须是不存在的 Configuration conf = new Configuration();//加载配置文件 final Job job = new Job(conf,"WordCountApp");//创建一个job对象,封装运行时所需要的所有信息,可以提交到hadoop独立地运行 job.setJarByClass(WordCountApp.class);//需要打X成jar包的话,加这一句 FileInputFormat.setInputPaths(job,INPUT_PATH);//告诉job执行作业时输入文件的路径 job.setInputFormatClass(TextInputFormat.class);//设置把输入文件处理成键值对的类 job.setMapperClass(MyMapper.class);//设置自定义的Mapper类 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class);//设置map方法输出的k2、v2的类型 //job.setCombinerClass(MyReducer.class); job.setPartitionerClass(HashPartitioner.class);//设置对k2分区的类 job.setNumReduceTasks(1);//设置运行的Reducer任务的数量 job.setReducerClass(MyReducer.class);//设置自定义的Reducer类 FileOutputFormat.setOutputPath(job,new Path(OUTPUT_PATH));//告诉job执行作业的输出路径 job.setOutputFormatClass(TextOutputFormat.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class);//设置reduce方法输出的k3、v3的类型 job.waitForCompletion(true);//让作业运行,直到运行结束,程序退出,把job对象提交给hadoop运行,直到作业运行结束后才可以 }
final String pathString="/input"; final FSDataOutputStream fsDataOutputStream=fileSystem.create(new Path(pathString)); IOUtils.copyBytes(new ByteArrayInputStream("wish you happy \n".getBytes()),fsDataOutputStream,configuration,false); IOUtils.copyBytes(new ByteArrayInputStream("wish you happy \n".getBytes()),fsDataOutputStream,configuration,false); IOUtils.copyBytes(new ByteArrayInputStream("wish you happy \n".getBytes()),fsDataOutputStream,configuration,false); IOUtils.copyBytes(new ByteArrayInputStream("wish you happy \n".getBytes()),fsDataOutputStream,configuration,false); IOUtils.copyBytes(new ByteArrayInputStream("wish you happy \n".getBytes()),fsDataOutputStream,configuration,false); IOUtils.copyBytes(new ByteArrayInputStream("wish you happy \n".getBytes()),fsDataOutputStream,configuration,false); IOUtils.copyBytes(new ByteArrayInputStream("wish you happy \n".getBytes()),fsDataOutputStream,configuration,false); IOUtils.copyBytes(new ByteArrayInputStream("wish you happy \n".getBytes()),fsDataOutputStream,configuration,false); IOUtils.copyBytes(new ByteArrayInputStream("wish you happy \n".getBytes()),fsDataOutputStream,configuration,false); IOUtils.copyBytes(new ByteArrayInputStream("Today is a nice day \n".getBytes()),fsDataOutputStream,configuration,false); IOUtils.copyBytes(new ByteArrayInputStream("Today is a nice day \n".getBytes()),fsDataOutputStream,configuration,false); IOUtils.copyBytes(new ByteArrayInputStream("Today is a nice day \n".getBytes()),fsDataOutputStream,configuration,false); IOUtils.copyBytes(new ByteArrayInputStream("Today is a nice day \n".getBytes()),fsDataOutputStream,configuration,true);
14/05/18 12:08:04 INFO mapred.JobClient: Running job: job_local_0001
14/05/18 12:08:04 INFO mapred.Task: Using ResourceCalculatorPlugin : null
14/05/18 12:08:04 INFO mapred.MapTask: io.sort.mb = 100
14/05/18 12:08:04 INFO mapred.MapTask: data buffer = 79691776/99614720
14/05/18 12:08:04 INFO mapred.MapTask: record buffer = 262144/327680
14/05/18 12:08:04 INFO mapred.MapTask: Starting flush of map output
14/05/18 12:08:04 INFO mapred.MapTask: Finished spill 0
14/05/18 12:08:04 INFO mapred.Task: Task:attempt_local_0001_m_000000_0 is done. And is in the process of commiting
14/05/18 12:08:04 INFO mapred.LocalJobRunner:
14/05/18 12:08:04 INFO mapred.Task: Task ‘attempt_local_0001_m_000000_0‘ done.
14/05/18 12:08:04 INFO mapred.Task: Using ResourceCalculatorPlugin : null
14/05/18 12:08:04 INFO mapred.LocalJobRunner:
14/05/18 12:08:04 INFO mapred.Merger: Merging 1 sorted segments
14/05/18 12:08:04 INFO mapred.Merger: Down to the last merge-pass, with 1 segments left of total size: 499 bytes
14/05/18 12:08:04 INFO mapred.LocalJobRunner:
14/05/18 12:08:04 INFO mapred.Task: Task:attempt_local_0001_r_000000_0 is done. And is in the process of commiting
14/05/18 12:08:04 INFO mapred.LocalJobRunner:
14/05/18 12:08:04 INFO mapred.Task: Task attempt_local_0001_r_000000_0 is allowed to commit now
14/05/18 12:08:04 INFO output.FileOutputCommitter: Saved output of task ‘attempt_local_0001_r_000000_0‘ to hdfs://hadoop:9000/output
14/05/18 12:08:04 INFO mapred.LocalJobRunner: reduce > reduce
14/05/18 12:08:04 INFO mapred.Task: Task ‘attempt_local_0001_r_000000_0‘ done.
14/05/18 12:08:05 INFO mapred.JobClient: map 100% reduce 100%
14/05/18 12:08:05 INFO mapred.JobClient: Job complete: job_local_0001
14/05/18 12:08:05 INFO mapred.JobClient: Counters: 19
14/05/18 12:08:05 INFO mapred.JobClient: File Output Format Counters
14/05/18 12:08:05 INFO mapred.JobClient: Bytes Written=51
14/05/18 12:08:05 INFO mapred.JobClient: FileSystemCounters
14/05/18 12:08:05 INFO mapred.JobClient: FILE_BYTES_READ=781
14/05/18 12:08:05 INFO mapred.JobClient: HDFS_BYTES_READ=456
14/05/18 12:08:05 INFO mapred.JobClient: FILE_BYTES_WRITTEN=130038
14/05/18 12:08:05 INFO mapred.JobClient: HDFS_BYTES_WRITTEN=51
14/05/18 12:08:05 INFO mapred.JobClient: File Input Format Counters
14/05/18 12:08:05 INFO mapred.JobClient: Bytes Read=228
14/05/18 12:08:05 INFO mapred.JobClient: Map-Reduce Framework
14/05/18 12:08:05 INFO mapred.JobClient: Map output materialized bytes=503
14/05/18 12:08:05 INFO mapred.JobClient: Map input records=13
14/05/18 12:08:05 INFO mapred.JobClient: Reduce shuffle bytes=0
14/05/18 12:08:05 INFO mapred.JobClient: Spilled Records=94
14/05/18 12:08:05 INFO mapred.JobClient: Map output bytes=403
14/05/18 12:08:05 INFO mapred.JobClient: Total committed heap usage (bytes)=1065484288
14/05/18 12:08:05 INFO mapred.JobClient: SPLIT_RAW_BYTES=89
14/05/18 12:08:05 INFO mapred.JobClient: Combine input records=0
14/05/18 12:08:05 INFO mapred.JobClient: Reduce input records=47
14/05/18 12:08:05 INFO mapred.JobClient: Reduce input groups=8
14/05/18 12:08:05 INFO mapred.JobClient: Combine output records=0
14/05/18 12:08:05 INFO mapred.JobClient: Reduce output records=8
14/05/18 12:08:05 INFO mapred.JobClient: Map output records=47
Today 4
a 4
day 4
happy 9
is 4
nice 4
wish 9
you 9
标签:style blog class code c java
原文地址:http://www.cnblogs.com/wishyouhappy/p/3735044.html