二分类问题(classification)
给定一个样本集T
样本总数为m
每个样本记做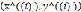
其中 为输入变量,也称为特征变量;
为输入变量,也称为特征变量; 为我们要预测的输出变量,也称为目标变量
为我们要预测的输出变量,也称为目标变量
 表示第
表示第 个样本。
个样本。
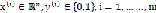
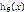 的作用是,对于给定的输入变量,根据选择的参数计算输出变量=1的可能性
的作用是,对于给定的输入变量,根据选择的参数计算输出变量=1的可能性
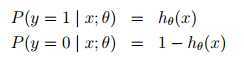
也就是
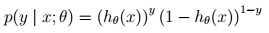
最终,当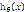 大于等于0.5时,预测y=1,当
大于等于0.5时,预测y=1,当 小于0.5时,预测y=0
小于0.5时,预测y=0
假设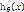 是一下形式:
是一下形式:
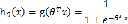
其中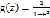 称为Logistic函数或者sigmoid函数,函数图象如下
称为Logistic函数或者sigmoid函数,函数图象如下
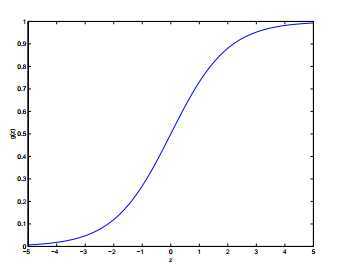
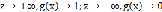
为什么选择
Logistic函数见下节广义线性模型(Generlized Linear Models)
Logistic函数有如下有趣性质:
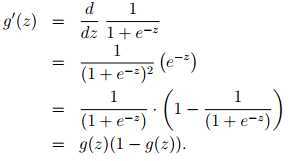
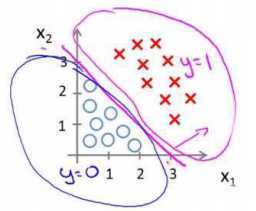
下面情况怎么办?
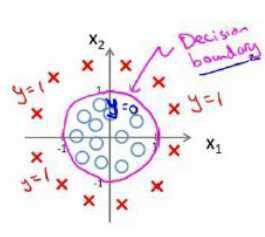
试一下这个:(模型选择一节将进一步研究)
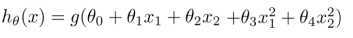
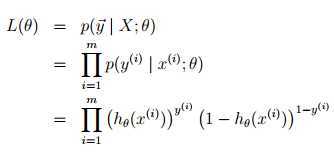
之后要做的就是
梯度下降是解决这种优化问题的通用解法
使用 更新策略
更新策略
偶偶,得到和线性回归一样的结果。。别得意, 是不一样的
是不一样的
最终的更新策略如下:
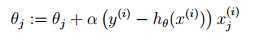
对?(θ)求导,令导数等于0。。。。这个式子太复杂了,貌似没有直接解法
使用如下更新方法
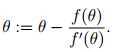
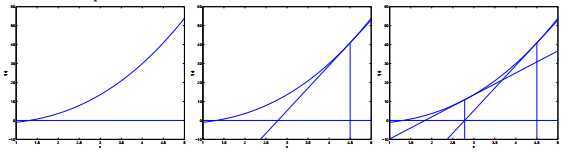
过程看下图自行脑补:
在Logistic Regression中,最大化
?(θ)的过程可以看做寻找?(θ)一阶导数为零的点,这样就转换成牛顿法可以求解的问题:
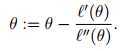
注意到
Logistic Regression中θ是一个向量,需要对牛顿法做拓广,叫Newton-Raphson method
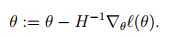
H是
Hessian矩阵,在Logistic Regression中:
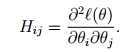
牛顿法在接近收敛时,有平方的收敛效果,即原来有0.01的误差,一次迭代后只有0.0001的误差
这使得牛顿法相比梯度下降法只需要少量的迭代就能达到相同的精度
牛顿法收敛速度虽然很快,但求 Hessian 矩阵的逆的时候比较耗费时间
牛顿法的初始化参数只有靠近收敛点才回高效,如果远离收敛点,甚至不会收敛,因为导数方向没有指示收敛点的方向
用牛顿法求解Logistic Regression叫Fisher‘s scoring
什么Conjugate Gradient,BFGS,LBFGS。。。。将开辟一节
可规约为:
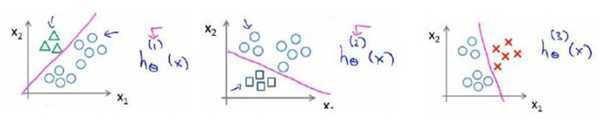
这种方法叫做一对多(One-vs-All)方法
更高级的方法会开辟一节单独研究
[1] CS229
Lecture notes 1 (ps) (pdf) Supervised Learning, Discriminative Algorithms Andrew Ng
[2] Coursera Machine Learning Andrew Ng
未完待续
2. Supervised Learning - Logistic Regression,布布扣,bubuko.com
2. Supervised Learning - Logistic Regression
原文地址:http://www.cnblogs.com/noooop/p/3735278.html