在Wiki上看到的LSA的详细介绍,感觉挺好的,遂翻译过来,有翻译不对之处还望指教。
原文地址:http://en.wikipedia.org/wiki/Latent_semantic_analysis
前言
浅层语义分析(LSA)是一种自然语言处理中用到的方法,其通过“矢量语义空间”来提取文档与词中的“概念”,进而分析文档与词之间的关系。LSA的基本假设是,如果两个词多次出现在同一文档中,则这两个词在语义上具有相似性。LSA使用大量的文本上构建一个矩阵,这个矩阵的一行代表一个词,一列代表一个文档,矩阵元素代表该词在该文档中出现的次数,然后再此矩阵上使用奇异值分解(SVD)来保留列信息的情况下减少矩阵行数,之后每两个词语的相似性则可以通过其行向量的cos值(或者归一化之后使用向量点乘)来进行标示,此值越接近于1则说明两个词语越相似,越接近于0则说明越不相似。
LSA最早在1988年由 Scott Deerwester, Susan Dumais, George Furnas, Richard Harshman, Thomas Landauer, Karen Lochbaum and Lynn Streeter提出,在某些情况下,LSA又被称作潜在语义索引(LSI)。
概述
词-文档矩阵(Occurences Matrix)
LSA 使用词-文档矩阵来描述一个词语是否在一篇文档中。词-文档矩阵式一个稀疏矩阵,其行代表词语,其列代表文档。一般情况下,词-文档矩阵的元素是该词在文档中的出现次数,也可以是是该词语的tf-idf(term frequency–inverse document frequency)。
词-文档矩阵和传统的语义模型相比并没有实质上的区别,只是因为传统的语义模型并不是使用“矩阵”这种数学语言来进行描述。
降维
在构建好词-文档矩阵之后,LSA将对该矩阵进行降维,来找到词-文档矩阵的一个低阶近似。降维的原因有以下几点:
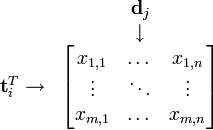
可以看到,每一行代表一个词的向量,该向量描述了该词和所有文档的关系。
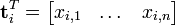
相似的,一列代表一个文档向量,该向量描述了该文档与所有词的关系。

词向量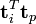 的点乘可以表示这两个单词在文档集合中的相似性。矩阵
的点乘可以表示这两个单词在文档集合中的相似性。矩阵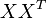 包含所有词向量点乘的结果,元素(i,p)和元素(p,i)具有相同的值,代表词p和词i的相似度。类似的,矩阵
包含所有词向量点乘的结果,元素(i,p)和元素(p,i)具有相同的值,代表词p和词i的相似度。类似的,矩阵 包含所有文档向量点乘的结果,也就包含了所有文档那个的相似度。
包含所有文档向量点乘的结果,也就包含了所有文档那个的相似度。
现在假设存在矩阵 的一个分解,即矩阵可分解成正交矩阵U和V,和对角矩阵
的一个分解,即矩阵可分解成正交矩阵U和V,和对角矩阵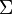 的乘积。
的乘积。
这种分解叫做奇异值分解(SVD),即:

因此,词与文本的相关性矩阵可以表示为:
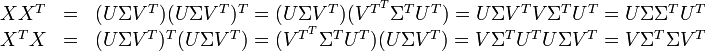
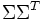 与
与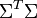 是对角矩阵,因此
是对角矩阵,因此 肯定是由的特征向量组成的矩阵,同理
肯定是由的特征向量组成的矩阵,同理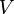 是特征向量组成的矩阵。这些特征向量对应的特征值即为中的元素。综上所述,这个分解看起来是如下的样子:
是特征向量组成的矩阵。这些特征向量对应的特征值即为中的元素。综上所述,这个分解看起来是如下的样子: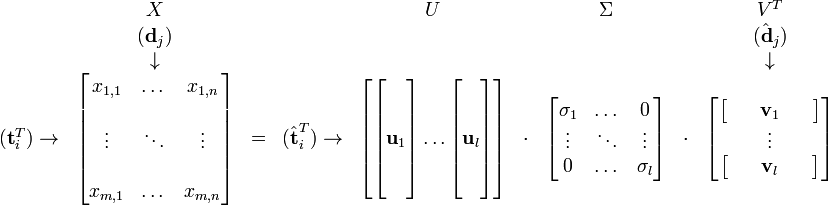
 被称作是奇异值,而
被称作是奇异值,而  和
和 则叫做左奇异向量和右奇异向量。通过矩阵分解可以看出,原始矩阵中的
则叫做左奇异向量和右奇异向量。通过矩阵分解可以看出,原始矩阵中的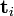 只与U矩阵的第i行有关,我们则称第i行为
只与U矩阵的第i行有关,我们则称第i行为  。同理,原始矩阵中的
。同理,原始矩阵中的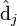 只与
只与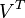 中的第j列有关,我们称这一列为。与并非特征值,但是其由矩阵所有的特征值所决定。
中的第j列有关,我们称这一列为。与并非特征值,但是其由矩阵所有的特征值所决定。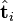 与含有k个奇异值的矩阵相乘,实质是从高维空间到低维空间的一个变换,可以理解为是一个高维空间到低维空间的近似。同理,向量
与含有k个奇异值的矩阵相乘,实质是从高维空间到低维空间的一个变换,可以理解为是一个高维空间到低维空间的近似。同理,向量 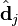 也存在这样一个从高维空间到低维空间的变化。这种变换用公式总结出来就是这个样子:
也存在这样一个从高维空间到低维空间的变化。这种变换用公式总结出来就是这个样子: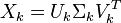
 与
与  在低维空间的相似度。比较向量
在低维空间的相似度。比较向量 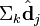 与向量
与向量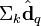 (比如使用余弦夹角)即可得出。
(比如使用余弦夹角)即可得出。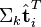 与
与 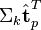 可以判断词
可以判断词 和词
和词 的相似度。
的相似度。 
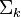 的逆矩阵可以通过求其中非零元素的倒数来简单的得到。
的逆矩阵可以通过求其中非零元素的倒数来简单的得到。 将其映射到语义空间,再与文档进行比较。
将其映射到语义空间,再与文档进行比较。低维的语义空间可以用于以下几个方面:
(原文还说了一些其它方面,感觉不是很重要,不翻译了,放上原文)
Synonymy and polysemy are fundamental problems in natural language processing:
LSA has been used to assist in performing prior art searches for patents.[5]
The use of Latent Semantic Analysis has been prevalent in the study of human memory, especially in areas of free recall and memory search. There is a positive correlation between the semantic similarity of two words (as measured by LSA) and the probability that the words would be recalled one after another in free recall tasks using study lists of random common nouns. They also noted that in these situations, the inter-response time between the similar words was much quicker than between dissimilar words. These findings are referred to as the Semantic Proximity Effect.[6]
When participants made mistakes in recalling studied items, these mistakes tended to be items that were more semantically related to the desired item and found in a previously studied list. These prior-list intrusions, as they have come to be called, seem to compete with items on the current list for recall.[7]
Another model, termed Word Association Spaces (WAS) is also used in memory studies by collecting free association data from a series of experiments and which includes measures of word relatedness for over 72,000 distinct word pairs.[8]
算法局限性
LSA的一些缺点如下:
原文地址:http://blog.csdn.net/roger__wong/article/details/41175967