标签:style blog http ar sp strong 数据 on 2014
先说一下什么是密度聚类的方法
参考文章:基于密度的聚类
这篇文章的大概意思通过一幅图来说明:
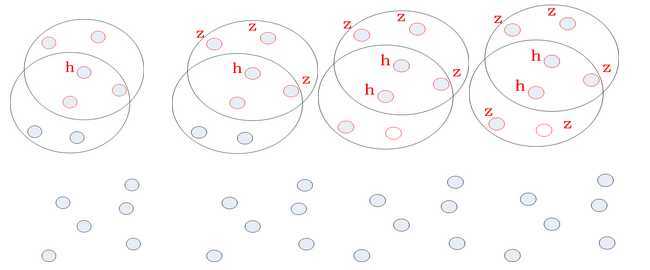
1 首先任意选定一个点假设就以图中最左边的h为第一个点,根据半径判断,在一定的范围内点的个数是否满足要求。
-如果满足把这个点标记为核心点,这个圆判定为一个聚类。
-如果不是,就把这个点判定为边界点,标记为噪声;在随机选取一个点。
2 确定这一类,依次判断这个圆内的点的属性(核心,边界)。
3 如果还有没有被标记的点,在任意选取一个点从上面开始做,一直到标记完所有的点。
优点:
1 对噪声不敏感。
2 能发现任意形状的聚类。
缺点:
1 结果与参数有很大的关系。
2 有一些点会被判定为数据不同的类。
我的方法:
也是基于密度聚类的方法,首先摒弃了圆形,采用了方形来判断,提高了速度。
其次,基于上,把坐标系画风成不同的小方块,统计在图形内的点,再对这些图形进行分类。
不会产生一个点属于多个类的情况。
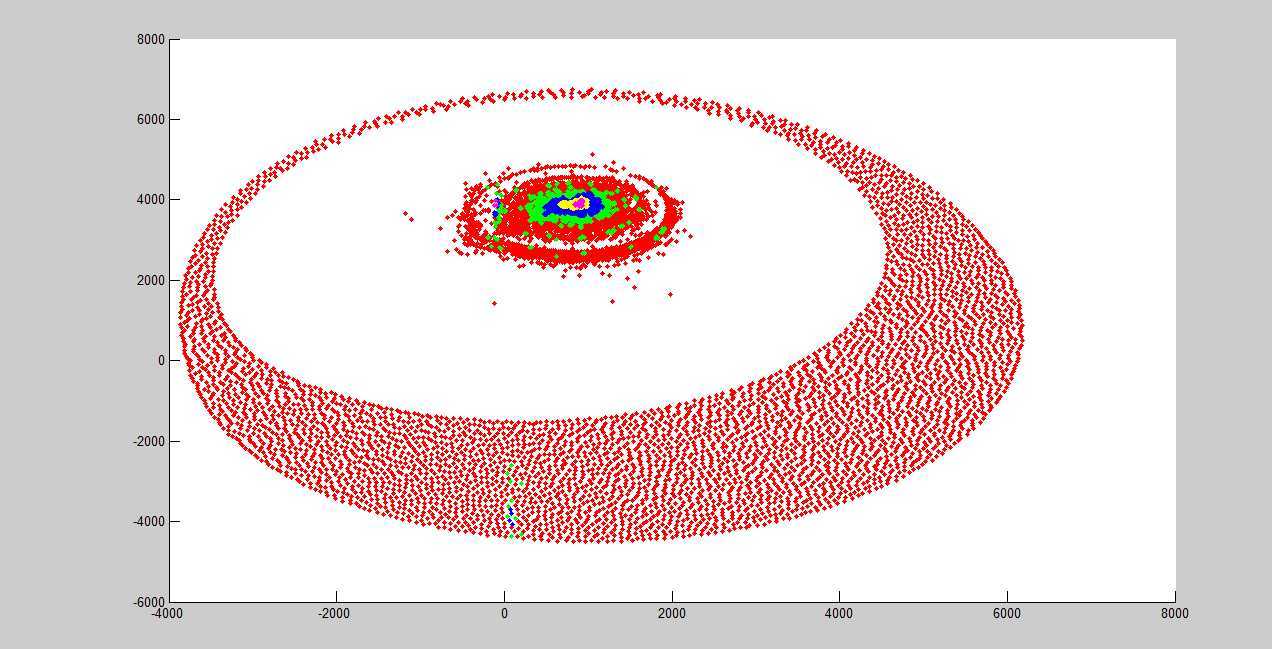
下面是对1w多个点的聚类情况:,x的范围[-4000, 6200], y的范围[-5000, 6200]。
先看一下原始数据的情况:

这是下面第一次的结果,参数100*100:
看起来还不错,但是当放大两次和放大三次后:
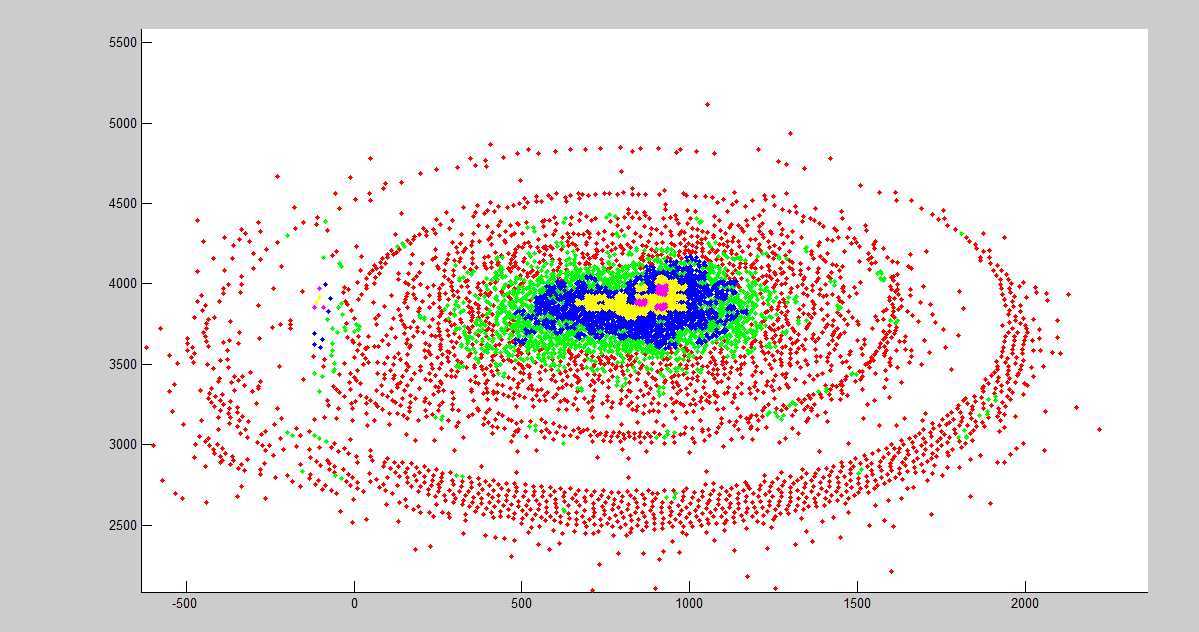
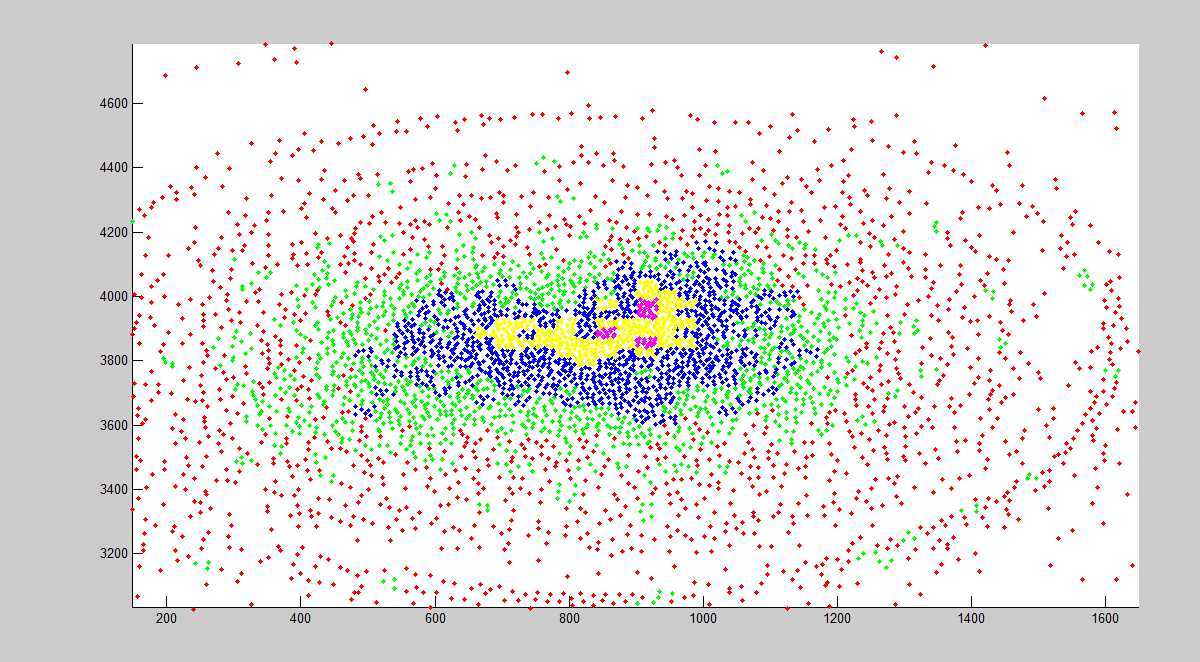
可以看到,当放大三次后,结果就没有那么乐观了,有了很明显的分块现象
采取参数30*30:
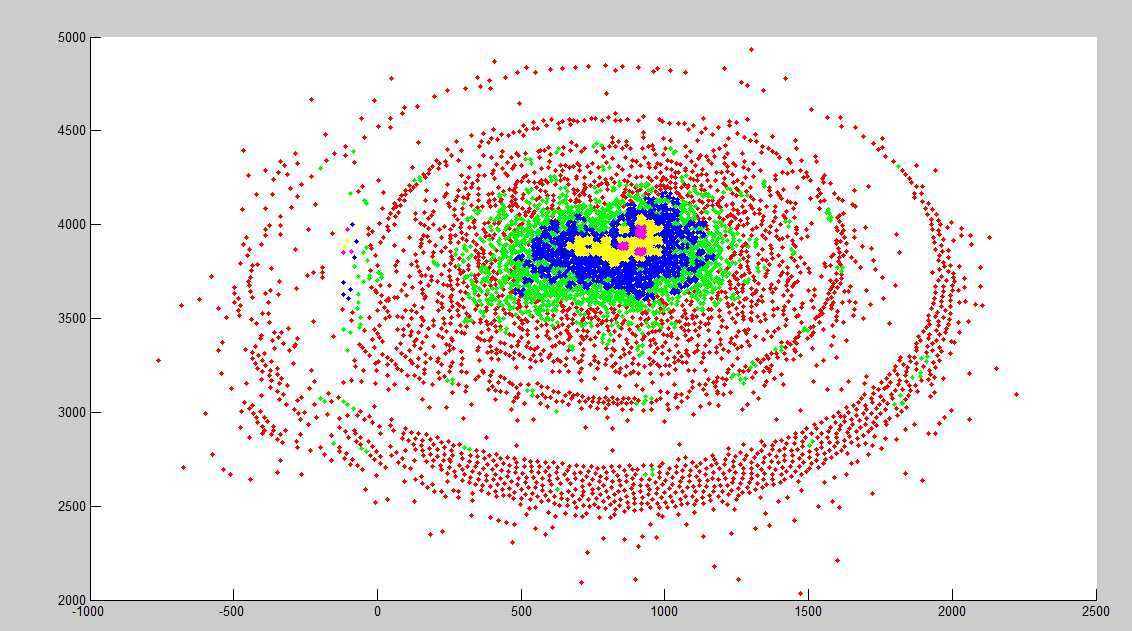
这次是直接放大情况,可以看到结果还是比较不错的。
只是这种方法的噪音有点多。
综上发现:
结果和参数的关系并不明显。
也可以发现任意形状的聚类。
一个点也不会同时归为两个类。
但是这次的结果却噪音偏多。
以上。
标签:style blog http ar sp strong 数据 on 2014
原文地址:http://www.cnblogs.com/xujie-nm/p/4111506.html