标签:des style blog http io ar color os 使用
(The record length is the number of characters, including spaces, in a data line.) If your data lines are long, and it looks like SAS is not reading all your data, then use the LRECL= option in the INFILE statement to specify a record length at least as long as the longest record in your data file.
filename test ‘E:\sasData\num1.txt‘; data res; infile test lrecl=256; label name=‘姓名‘ age=‘年龄‘; input name$ age; run;
1:三种读取数据的方式
1.1:list input
变量名字符数小于32,字符型变量后加$, 两个变量间要有间隔。缺失值用 . 表示。
INPUT Name $ Age Height; 可行 尽量用这种,美观,易阅读
INPUT Name $Age Height; 可行
INPUT Name$ Age Height;可行
INPUT Name$Age Height; 可行
适用范围?
对于日期型或其他复杂类型不适用
适用于字符(字符中不能带有空格)和数字,并以空格为分隔符的数据
列指针停留在哪?
data two; input x $ y 1.; datalines; 10 1 /*读入结果10 1*/ 10 1 /**读入结果10 ./
100000000011 2 /*读入结果10000000 2*/ ; run;
/*表明list input的指针停留在最后一个读入参数的紧挨着的空格的下一个位置*/
1.2:Column input
适用范围?
对于对应变量值都在固定列的数据十分有用
优点?
读入的字符变量值可以带有空格
可以自由的选择读入的列,不必按顺序读入
缩减文件的存储空间,如果有空格分隔,那么空间将会增加一倍
对于缺失值的话读入空白列即可
列指针指针停留在哪?
停留在指定的列的下一列
INPUT Name $ 1-10 Age 11-13 Height 14-18;
以上两种都只能读入标准数值类型,比如Standard numeric data contain only numerals, decimal points, minus signs, and E for scientific notation.
无法读入Numbers with embedded commas or dollar signs are examples这些非标准的数值类型。 例如100,100,1 $100 日期型这些数据
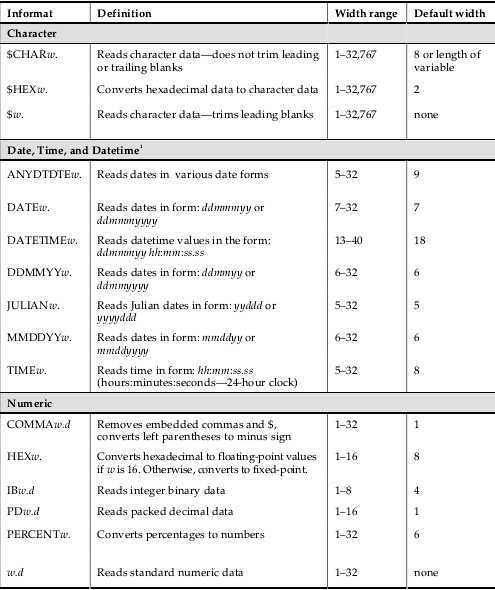
1.3:格式输入
w=total width d=number of decimal
字符格式 $informatw. w.是标准的字符读入格式(不带informat)
数值格式 informatw.d w.d是标准的数值读入格式(不带informat)
日期格式 informatw.
格式输入都是从第一列开始读入数据,如果对应列数不对,读入的数据也会有误
对于混合输入,其开始位置依据其他两种输入法的数据指针的位置进行读取数据
列指针指针停留在哪?
停留在规定的长度的下一格
data one; INPUT Name $16. Age 3. +1 Type $1. +1 Date MMDDYY10. (Score1-Score5) (4.1); datalines; Alicia Grossman 13 c 10-28-2008 7.8 6.5 7.2 8.0 7.9 ; run;
常用的可选择的格式
读入数据及其结果展示
1.4:混合输入
取长补短,中西合并!!结合三种输入法的优缺点进行数据读取
data one; INPUT name $ 1-22 state $ year @40 size comma9.; datalines; Yellowstone ID/MT/WY 1872 4,065,493 Everglades FL 1934 1,398,800 Yosemite CA 1864 760,917 Great Smoky Mountains NC/TN 1926 520,269 Wolf Trap Farm VA 1966 130 ; run;
/*重点是数据指针的位置,上面的三种读入方式有描述*/
2:读取mess data
有时候,前面的四种方式都胜任不了读入的任务,那么需要更多的工具来完成相应的目标
The @‘character’ column pointer
sometimes you don’t know the starting column of the data, but you do know that it always comes after a particular character or word
The colon modifier :
If you only want SAS to read until it encounters a space,then you can use a colon modifier on the informat
对于字符型格式输入,如果是默认长度,则读取的数据长度小于等于8。
如果规定长度,比如$20. 则可能读取到不想要的数据
这时候可以用:
/*要读取的数据*/
My dog Sam Breed: Rottweiler Vet Bills: $478 /*不同的读取方式和结果*/ INPUT @’Breed:’ DogBreed $; Rottweil INPUT @’Breed:’ DogBreed $20.; Rottweiler Vet Bill INPUT @’Breed:’ DogBreed :$20.; Rottweiler
3:数据读取技巧
3.1:一个input读取多行数据
如果input中的变量在一行数据中没有全部读取完,那么他会自动转到下一行读取数据
与其这样,不如我们自己明确规定他应该转到哪行去读取
DATA highlow; INPUT City $ State $ / NormalHigh NormalLow #3 RecordHigh RecordLow; */表示读取下一行 #n表示读取第n行,这里的第n行应理解为一次input循环中所相对的第n行,比如第一次88 29是第3行,第二次97 65就是是3行; datalines; Nome AK 55 44 88 29 Miami FL 90 75 97 65 Raleigh NC 88 68 105 50 ; RUN;
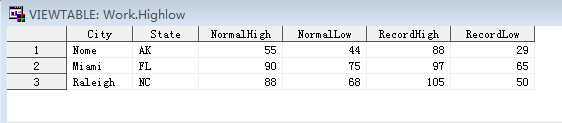
/与#n的重要区别,以及与lostcard搭配的使用
lostcard的作用:Discards the first record in the group of records being read,Attempts to build an observation by beginning with the second record in the group
使用/读取多行数据时,例如input var1 / var2;var1先被读入input缓冲流中,然后/表示换行将换行后的数据也读入同一个缓冲流中,这样就意味着,必须要先读入var1才能读入var2。
而使用#n时,那么就意味着系统会开创多条input缓冲流。这样我们就能读var2再读var1;input #2var2 #1var1;
*#n与lostcard结合的实例; data res; input id test1 #2 idcheck test2 test3; *使用#2时会得到正确的输出结果301 304,但是使用/时只能得到一条输出,因为使用/时第三行和第四行拼凑成了一条缓冲流,下次input会直接输入第五行而不会从第四行输入; if id ne idcheck then do; put id= idcheck=; lostcard; end; cards; 301 92 301 61 75 303 92 78 304 85 304 90 89 ; run; proc print noobs;run;
3.2:将一行数据读取到多个观测值
双尾@@ ,当使用时告诉sas不要换行,除非数据读取完毕,或者遇到一个不以@@结尾的input,当input遇到一行结尾而还有变量没读取时会自动切换到下一行
This line-hold specifier is like a stop sign telling SAS, “Stop, hold that line of raw data.”
data body_fat; input Gender $ PercentFat @@; datalines; m 13.3 f m 22 f 23.2 m 16 m 12 ;
3.3:按条件读入需要的数据,分段读取一条数据
单尾@
record理解为一横行,@的主要功能是可以在一个循环中分段读取一个record,来达到是否需要当前观测值的效果
data red_team; input Team $ 13-18 @; 1 if Team=‘red‘; 2 input IdNumber 1-4 StartWeight 20-22 EndWeight 24-26; 3 datalines; David red 189 165 Amelia yellow 145 124 Alan red 210 192 Ravi yellow 194 177 Ashley red 127 118 Jim yellow 220 . ; 4 proc print data=red_team; title ‘Red Team‘; run; 流程详解: 1:input读取第一条记录进入缓冲流,从13-18读取数据,然后赋值给pdv中的变量Team,单尾@将缓冲流中的record位置保存下来 2:if进行判断,如果是‘red’则进行下一个input语句,否则当前data循环停止,返回data步开始,将所有pdv中的变量赋为缺失值,并释放缓冲流中维持的record 3:如果是‘red’则进入下一个input,继续从缓冲流当前维持的record位置读取数据,并将值赋值给pdv中的变量IdNumber, StartWeight, and EndWeight 4:返回data步开始并释放缓冲流,并清空pdv
单尾@与双尾@的异同
相同点:
他们都是line-hold specifier
不同点:
The trailing @ holds a line of data for subsequent INPUT statements, but releases that line of data when SAS returns to the top of the DATA step to begin building the next observation
The double trailing @ holds a line of data for subsequent INPUT statements even when SAS starts building a new observation.
简而言之是单尾抓一轮,双尾抓死不放手!!!
4:infile语句以及其中的选项
sas读取数据有很多假设,比如一个input中的变量没读取完毕、或者是一个变量读了一半另一半在下一行,sas会自动跳到下一个数据行读取数据进入input中,有时这不是我们需要的,用infile中的选项可以解决很多这种问题
firstobs= tells SAS at what line to begin reading data
obs= It tells SAS to stop reading when it gets to that line in the raw data file
/**************************** Ice-cream sales data for the summer Flavor Location Boxes sold Chocolate 213 123 Vanilla 213 512 Chocolate 415 242 Data verified by Blake White 数据集中的数据 ****************************/ filename test ‘E:\sasData\num1.txt‘; data res; infile test firstobs=3 obs=5; input x :$12. y z; run;
Missover :MISSOVER option tells SAS that if it runs out of data, don’t go to the next data line.Instead, assign missing values to any remaining variables.
他告诉sas,说:"input没读完就别读啦,直接全部给我赋为缺失值!!!"
truncover::option tells SAS to read data for the variable until it reaches the end of the data line, or the last column specified in the format or column range, whichever comes first
上面时truncover的结果,下面是missover
根据字面意思也可以区分,trunc是截断,表明是有多少留多少!
miss是丢失,表明没有那么多就干脆为缺失吧!
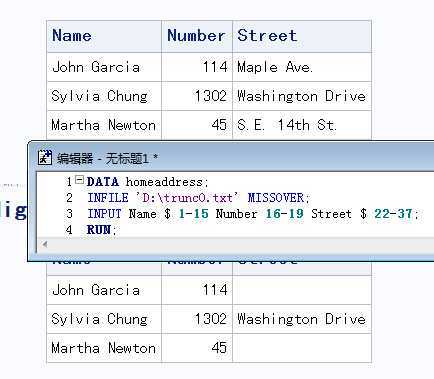
dlm=‘?‘ 标明你要使用的分隔符 ,对于常用的csv文件用dlm=‘,‘;对用tab分隔符,如果电脑编码是ASCII则用dlm=‘09‘x;如果编码为EBCDIC则用dlm=‘05‘X;
dlmstr=‘?‘ 标明你要使用的字符串分隔符
dsd(delimiter-sensitive data)这个符号做了三件事
1:忽视引号内的分隔符
2:当读取带引号的字符串时,不把引号内读作数据的一部分(比如读取"abc",读入数据集中的内容是abc)
3:将两个连续的分隔符当做缺失值处理(默认‘,‘为分隔符,要改变的话要再加dlm=选项,默认情况下sas会将多个连续分隔符当成一个处理)
5:PROC IMPORT过程。
import过程会预先扫描20行来判断变量对应的类型,并且会根据你的文件后缀来判断你的分隔符,如果是.csv则会用‘,‘,.txt则用‘09‘X,其他的需要自己声明。
会忽略引号,并将两个连续分隔符当做缺失值处理。实现dsd dlm missover的大部分功能。
PROC IMPORT DATAFILE=‘D:\truncO.csv‘ OUT=Temp REPLACE;GETNAMES=NO;RUN;
REPLACE会将输出数据集替代原有的数据集。
GETNAMES=NO; 是不把第一行当做列名。
DATAROWS = n;是规定从第几行开始读取
GUESSINGROWS = n; 是改变默认扫面的行数
6:自己定义缺失值
data res;
missing N R;*表示将N R也默认为缺失值,当读到N R数据时,而要求是数字格式的话,那么不会将其赋值为缺失值,而会写成N R;
...................
run;
标签:des style blog http io ar color os 使用
原文地址:http://www.cnblogs.com/yican/p/4110956.html