标签:blog http 使用 数据 2014 log 工作 as 算法
在之前的文章中简单描述了一下如何通过LRU结合多层缓存机制实现高命中的缓存,这一章节里的主要内容是深入地了解其原理的实现.
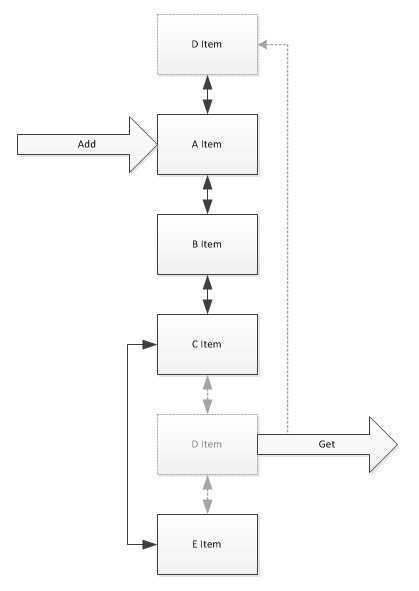
什么是LRU算法? LRU是Least Recently Used的缩写,即最少使用页面置换算法,是为虚拟页式存储管理服务的.通过这种算法可以把最近使用的数据迁移到数据存储的热区,而不常用的数据则迁到数 据存储的冷区;通过数据存储分区那在清除局部冷区数据相应要处理的复杂底就会降低.在.NET中可以通过一个双向链表来实现冷热交互的结构,大概结构如 下:
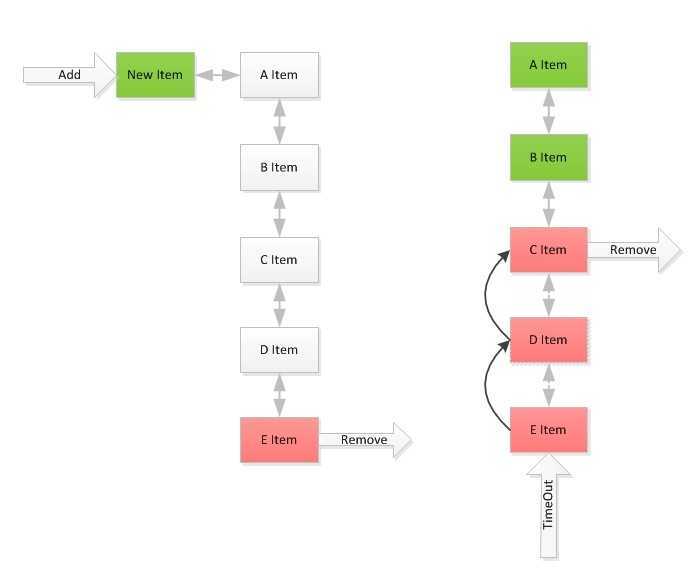
以上是一个基于双向链表存储的原理,新添加进来的数据会添加到头部,当数据被获取命中后同样也会移至到链表头,这样就能形成一个上面的热数据而下面 的冷数据的存储结构体.基于这种结构我们可以在添加的时候如果存储容间不足就可以把尾部的项移走,在移除超时项时也只需要从底部开始检测这样可以做以最少 复杂度的情况把已经超时的数据删除.
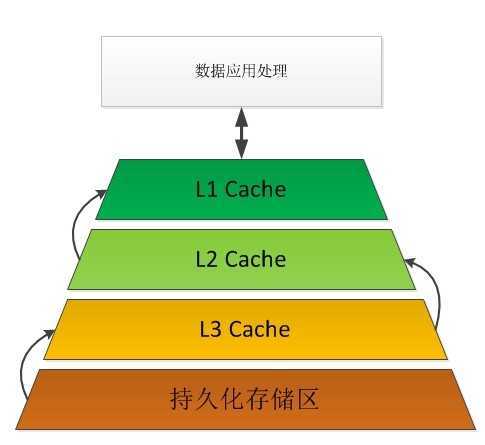
在之前的文章里已经提到,只有LRU是满足不了命中率的需求.LRU只以保证最新的数据存储在热区,访问低的数据存储在冷区.但在实际应用中热区的数据并不代表中率就很高;因此为了满足存储命中率的需要就要加入类似于CPU中多级缓存区的机制原理.
通过以上划分层次可以把不同命中率的数据存放到不同的缓存区,命中率最高的存放在最顶层,依次往下存储命中最低的存储到最低层.而应用处理则从最顶层开始检索,保证最快获取命中高的数据.
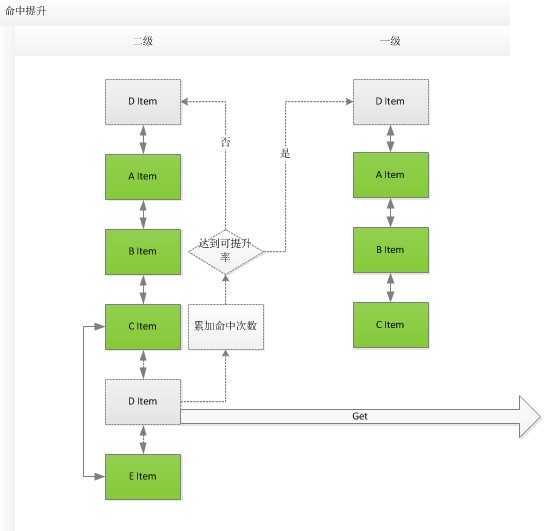
既然有了不同命中的存储区,那剩的工作就是如何把当前数据在这些区域中切换,其实现原理可以采用很简单的方法就是当一个缓存项在某个区中被获取的次数达到一定数据而又没有被当前区排除那就可以提升其命中率的级别.
标签:blog http 使用 数据 2014 log 工作 as 算法
原文地址:http://www.cnblogs.com/kloseking/p/4115183.html