标签:style blog http ar color os sp 数据 on
在因子分析(Factor analysis)中,介绍了一种降维概率模型,用EM算法(EM算法原理详解)估计参数。在这里讨论另外一种降维方法:主元分析法(PCA),这种算法更加直接,只需要进行特征向量的计算,不需要用到EM算法。
假设数据集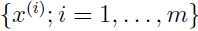 表示 m 个不同类型汽车的属性,比如最大速度,转弯半径等等. 对于任意一辆汽车
表示 m 个不同类型汽车的属性,比如最大速度,转弯半径等等. 对于任意一辆汽车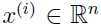 ,假设第 i 个属性和第 j 个属性 xi 和 xj 分别以 米/小时 和 千米/小时 来表示汽车的最大速度,那么很显然这两个属性是线性相关的,所以数据可以去掉其中一个属性,即在 n-1 维空间处理即可. 这只是一个小小的例子,在大多数现实的数据中,有太多这样的数据冗余和重复,所以要想办法自动检测和去掉这些数据冗余。
,假设第 i 个属性和第 j 个属性 xi 和 xj 分别以 米/小时 和 千米/小时 来表示汽车的最大速度,那么很显然这两个属性是线性相关的,所以数据可以去掉其中一个属性,即在 n-1 维空间处理即可. 这只是一个小小的例子,在大多数现实的数据中,有太多这样的数据冗余和重复,所以要想办法自动检测和去掉这些数据冗余。
例如现在对无线控制直升飞机的飞行员做一个调查,用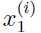 衡量飞行员 i 的飞行技能的熟练程度,
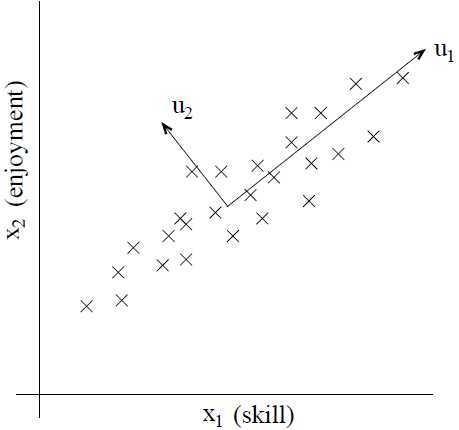
衡量飞行员 i 的飞行技能的熟练程度,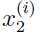 衡量飞行员享受飞行的程度,不过由于无线控制直升机很难操纵,所以只有那些具有熟练飞行技巧的飞行员才是真正享受飞行过程,才算得上优秀的飞行员。所以 x1 和 x2 指向具有很大的关联。于是,我们根据 x1 和 x2 画出数据,可以发现,数据主要都分布在坐标轴的角平分线方向变化 (u1所示方向),只有很少的点偏离这条线,如下图所示:
衡量飞行员享受飞行的程度,不过由于无线控制直升机很难操纵,所以只有那些具有熟练飞行技巧的飞行员才是真正享受飞行过程,才算得上优秀的飞行员。所以 x1 和 x2 指向具有很大的关联。于是,我们根据 x1 和 x2 画出数据,可以发现,数据主要都分布在坐标轴的角平分线方向变化 (u1所示方向),只有很少的点偏离这条线,如下图所示:
在执行PCA算法之前,需要对数据进行预处理,对数据的均值和方差进行归一化:
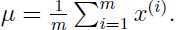
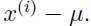 代替每一个
代替每一个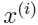
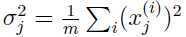
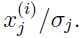 代替每一个
代替每一个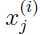
步骤(1-2)是为了保证数据的均值为0,对于那些均值本来就为0的数据集,这两步可以省略(例如语音的时序序列,或者其他声音信号).
步骤(3-4)保证每个坐标的方差为1,这样不同的属性值就被归一到同一个可比较的范围内处理,例如 x1 表示汽车的速度是几十或者几百米每小时,x2 表示汽车里面的座位数大约是2-4,那么就是通过方差的归一化使得这种差距较大的属性数据值有可比性。当然,如果我们确切知道原始数据中所有属性的取值都在同一个可比较的范围内,步骤(3-4)也是可以省略的,比如一个关于图像中各个像素点灰度值得数据集,每一个数据点的范围都是{0,1, ... ,255},所以方差就不用归一化.
预处理之后,如何检测出数据的主要变化方向呢?就是说想找到某一方向,使得大部分数据都近似分布在这个方向附近。
考虑下面进过归一化的数据:
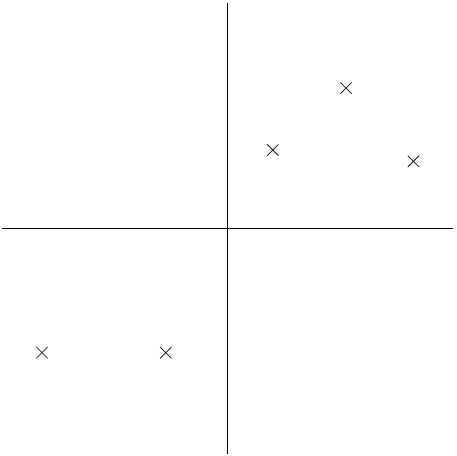
下面我们画出了一个方向 u,圆点表示原始数据在 u 上的映射:
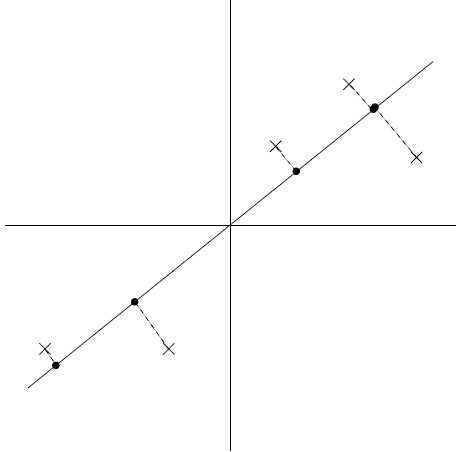
可以看出映射后的数据之间相距较远,即方差值较大,并且数据点都距原点较远,再考虑另一个方向:
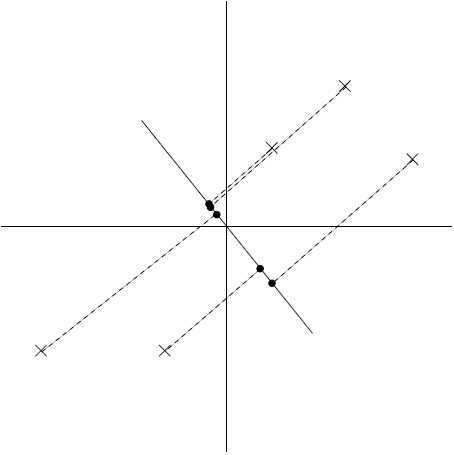
可以看出,这些映射后的数据点方差较小,而且距离原点比较近。
我们想要做的就是运用算法自动从上面类似的各个方向中选出最合适的方向。
给定单位向量 u 和一个点 x, x 映射到 u 上投影的长度为 xTu, 即一个数据集中的点 x(i) 映射到 u 上之后到原点的距离为 xTu
因为要选择出数据的主要变化方向 u, 从上面两个不同方向的例子可以看出,如果在原始数据主要沿某一方向变化较大,那么原始数据在这个方向上投影点的方差就较大,所以要找到u,就是最大化原数据在 u 方向上投影点的方差,通常把 u 设定为单位向量:
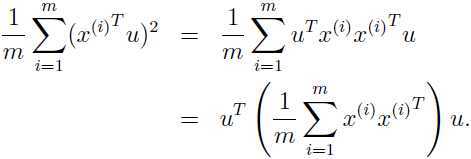
最大化上面的式子,注意到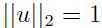 , 假设原始数据的均值为0(这一点要注意,同时也告诉我们为什么前面要将数据均值归一化为0),那么
, 假设原始数据的均值为0(这一点要注意,同时也告诉我们为什么前面要将数据均值归一化为0),那么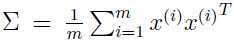 正好是原始数据的协方差矩阵(关于协方差矩阵的概念参考协方差详解l)
正好是原始数据的协方差矩阵(关于协方差矩阵的概念参考协方差详解l)
要想使得上面式子取得最大值,u 必须取 Σ 的主特征向量方向(可以定性理解为一个矩阵的主特征方向包含着该矩阵最多的信息)。更加一般地,想要把原始数据映射到一个 k 维的子空间(k<n),应该选择出 Σ 的k个最主要的特征向量 u1, u2, ..., uk, 这 k 个向量组成了一组新的正交基。
把数据映射到新的正交基所表示的空间:
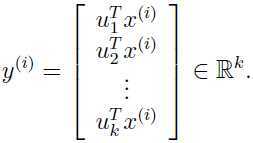
这样在尽可能多保留原始数据信息的情况下,把数据由 n 维降低至 k 维.因此PCA就是一种数据降维算法, u1, u2, ..., uk,叫做原始数据的前 k 个主成分.关于具体实践参考:PCA和白化练习之处理二维数据.
有时候数据维度高不仅仅是因为数据存在冗余,而是存在了一些噪声,所以PCA同样具有降噪的作用。
总结:
PCA就是一种把原始数据投影到该数据集的主特征方向上的操作,因为一个数据集的主特征方向包含着绝大部分该数据的信息,通过选取合适数量的特征向量,既可以保留原始数据的信息,又能实现数据降维降噪,到底具体选取几个特征向量通常是根据特征值来判断,用选取的特征向量对应的特征值之和比上所有特征值之和,结果一般要求大于95%即可,即保留了原始数据95%的信息,当然也可以根据问题的具体要求,调整这个选择的阈值。
Principal components analysis(PCA):主元分析
标签:style blog http ar color os sp 数据 on
原文地址:http://www.cnblogs.com/90zeng/p/PCA.html