标签:style blog http ar sp 文件 数据 on 2014
|
项目名称 |
Crawling is going on |
|
项目版本 |
Alpha版本 |
|
负责人 |
北京航空航天大学计算机学院 newbe软件团队 |
|
联系方式 |
http://www.cnblogs.com/newbe |
|
要求发布日期 |
2014-11-23 |
a) pdf文件无法保存到本地bug已修复。
b) 上一版从文件读入多行种子网址功能实际只能读到最后一行的种子网址,该“伪功能”已修复。
c) 网址栏或爬取数留空不能提醒用户,却会是程序锁死bug修复。
d) 上一版没有选择种子网址txt文件按钮,却是靠start按钮触发选择文件,设计不友好,改进为选择文件即出现选择txt按钮。
e) 种子网址栏只能输入一个种子网址,改进为可以输入多行种子网址。
1.2 新增功能
a) 增加了关键字爬取和链接+关键字爬取功能,可以过滤与关键字无关的网页。
b) 增加暂停以及重爬功能。
c) 增加本地文件保存路径的修改与打开查看功能。
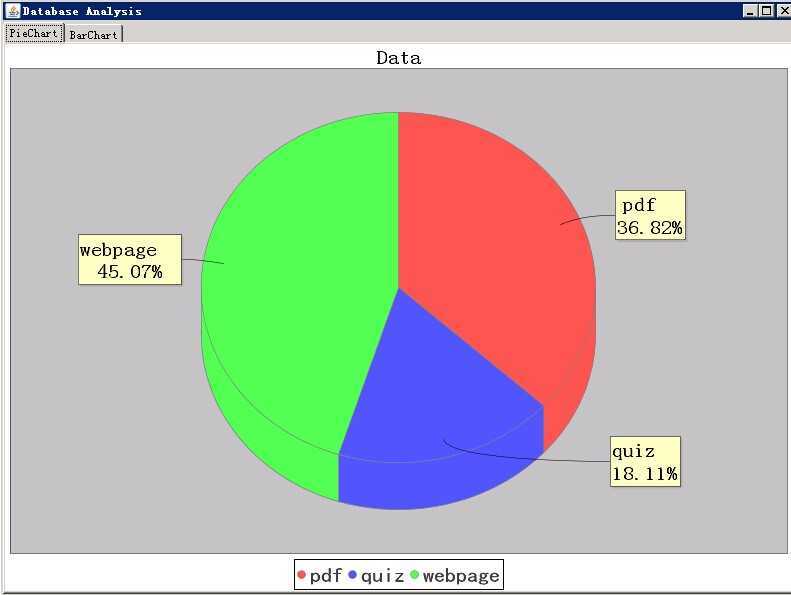
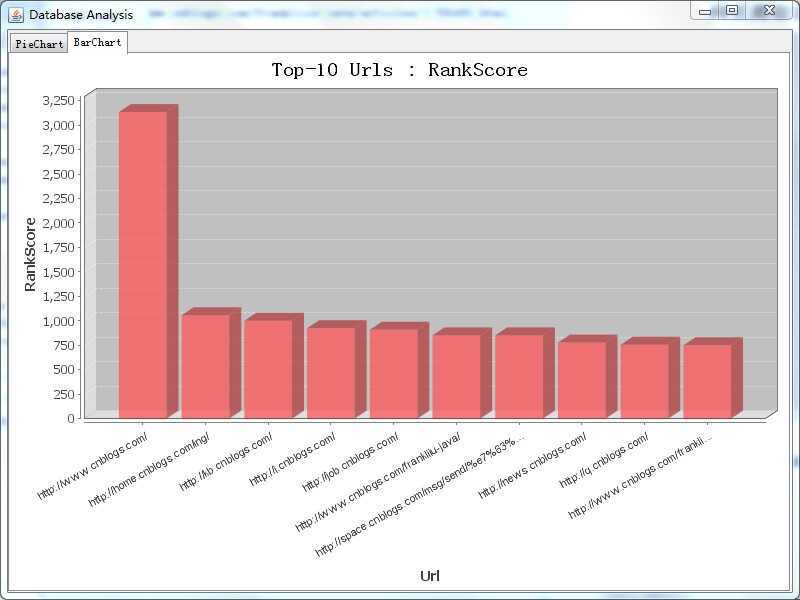
d) 增加依据PageRank算法按照热度排序得到Top10的网页,并和分类饼状图一起通过Analyze按钮呈现在柱状图上。
e) 记录爬取情况并能实时动态显示:爬取成功网页数,爬取失败数,过滤网页数等,并实时呈现在柱状图上。
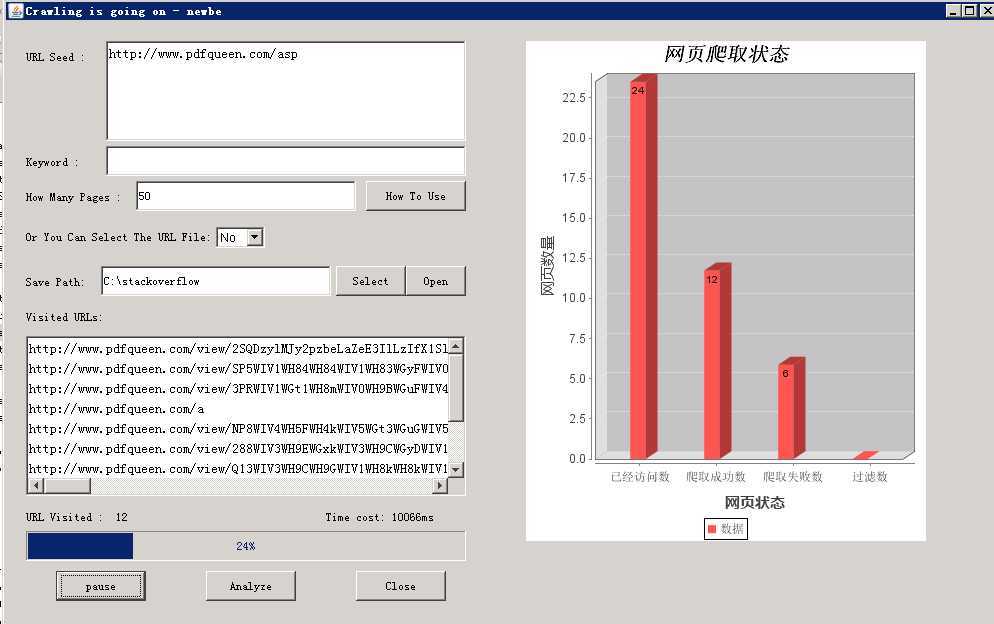
f) 界面新增实时计时功能,单位是毫秒(ms)。
g) 对界面整体布局进行了排版和优化。
|
操作系统需求 |
WINDOWS XP,WINDOWS 7,WINDOWS 8 |
|
运行环境需求 |
需安装最新版本的JRE |
|
数据库需求 |
在联网的环境下可以直接连接服务器的数据库,本地数据库没有特殊要求 |
将jar软件复制到本地,运行即可。
以下缺陷和限制将在Beta版中加以完善和补充。
a) 目前的(综合型)链接+关键字爬取的过滤算法算法相对比较简单,虽然适用于大多数的网页筛选,但是有些特殊的网页不能有效的进行过滤。
b) 个别url网址爬取时候会出现????这样的无法识别的字符导致出现异常。
该版本代码及程序发布在服务器219.224.191.25上,可自行下载试用。
标签:style blog http ar sp 文件 数据 on 2014
原文地址:http://www.cnblogs.com/newbe/p/4115483.html