标签:style class blog c code java
转载自:http://hc.csdn.net/contents/content_details?type=1&id=341
1.展开循环
如果提前知道了循环的次数,可以进行循环展开,这样省去了循环条件的比较次数。但是同时也不能使得kernel代码太大。

1 #include 2 using namespace std; 3 4 int main(){ 5 int sum=0; 6 for(int i=1;i<=100;i++){ 7 sum+=i; 8 } 9 10 sum=0; 11 for(int i=1;i<=100;i=i+5){ 12 sum+=i; 13 sum+=i+1; 14 sum+=i+2; 15 sum+=i+3; 16 sum+=i+4; 17 } 18 return 0; 19 }
2.避免处理非标准化数字
OpenCL中非标准化数字,是指数值小于最小能表示的正常值。由于计算机的位数有限,表示数据的范围和精度都不可能是无限的。(具体可以查看IEEE 754标准,http://zh.wikipedia.org/zh-cn/IEEE_754)
在OpenCL中使用非标准化数字,可能会出现“除0操作”,处理很耗时间。
如果在kernel中“除0”操作影响不大的话,可以在编译选项中加入-cl-denorms-are-zero,如:
clBuildProgram(program, 0, NULL, "-cl-denorms-are-zero", NULL, NULL);
3.通过编译器选项传输常量基本类型数据到kernel,而不是使用private memory
如果程序中需要给kernel 传输常量基本类型数据,最好是使用编译器选项,比如宏定义。而不是,每个work-item都定义一个private memory变量。这样编译器在编译时,会直接进行变量替换,不会定义新的变量,节省空间。
如下面代码所示(Dmacro.cpp):
1 #include2 int
main()3 {4 int
a=SIZE;5 printf("a=%d, SIZE=%d\n",a,SIZE);6 return
0;7 } |
编译:
g++ -DSIZE=128 -o A Dmacro.cpp
4.如果共享不重要的话,保存一部分变量在private memory而不是local memory
work-item访问private memory速度快于local memory,因此可以把一部分变量数据保存在private memory中。当然,当private memory容量满时,GPU硬件会自动将数据转存到local memory中。
5.访问local memory应避免bank conflicts
local memory被组织为一个一个的只能被单独访问的bank,bank之间交叉存储数据,以便连续的32bit被保存在连续的bank中。如下图所示:
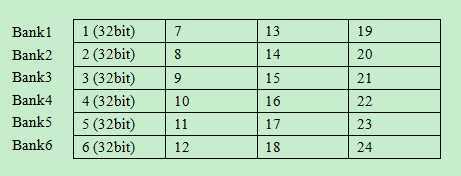
(1)如果多个work-item访问连续的local memory数据,他们就能最大限度的实现并行读写。
(2)如果多个work-item访问同一个bank中的数据,他们就必须顺序执行,严重降低数据读取的并行性。因此,要合理安排数据在local memory中的布局。
(3)特殊情况,如果一个wave/warp中的线程同时读取一个local memory中的一个地址,这时将进行广播,不属于bank 冲突。
6.避免使用”%“操作
"%"操作在GPU或者其他OpenCL设备上需要大量的处理时间,如果可能的话尽量避免使用模操作。
7.kernel中重用(Reuse) private memory,为同一变量定义不同的宏
如果kernel中有两个或者以上的private variable在代码中使用(比如一个在代码段A,一个在代码段B中),但是他们可以被数值相同。
也就是当一个变量用作不同的目的时,为了避免代码中的命名困惑,可以使用宏。在一个变量上定义不同的宏。
|
1
2
3
4
5
6
7
8
9
10
11 |
1 #include 2 int
main(){ 3 int
i=4; 4 #define EXP i 5 printf("EXP=%d\n",EXP); 6 7 #define COUNT i 8 printf("COUNT=%d\n",COUNT); 9 getchar();10 return
0;11 } |
8.对于(a*b+c)操作,尽量使用 fma function
如果定义了“FP_FAST_FMAF”宏,就可以使用函数fma(a,b,c)精确的计算a*b+c。函数fma(a,b,c)的执行时间小于或等于计算a*b+c。
9.在program file 文件中对非kernel的函数使用inline
inline修饰符告诉编译器在调用inline函数的地方,使用函数体替换函数调用。虽然会使得编译后的代码占用memory增加,但是省去了函数调用时上下、函数调用栈的切换操作,节省时间。
10.避免分支预测惩罚,应该尽量使得条件判断为真的可能性大
现代处理器一般都会进行“分支预测”,以便更好的提前“预取”下一条要执行的指令,使得“取指令、译码分析、执行、保存”尽可能的并行。
在“分支预测”出错时,提前取到的指令,不是要执行的指令,就需要根据跳转指令,进行重新取指令,就是“分支预测惩罚”。
看如下的代码:
1 #include 2 int main() 3 { 4 int i=1; 5 int b=0; 6 if(i == 1) 7 b=1; 8 else 9 b=0; 10 return 1; 11 }
对应的汇编代码:
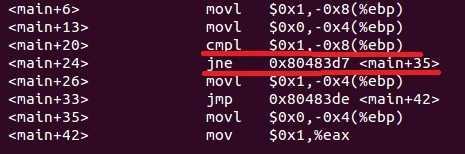
(movl 赋值,cmpl 比较,jne 不等于跳转,jmp 无条件跳转)
从上面的汇编指令代码看出,如果比较(<main+24>)结果相等,则执行<main+26>也就是比较指令的下一条指令,对应b=1顺序执行;如果比较(<main+24>)结果不相等,则执行跳转到<main+35>,不是顺序执行。
当然,有的处理器可能会根据以往“顺序执行”与“跳转执行”的比例来进行分支预测,但是这也是需要积累的过程。况且并不是,每个处理器多能这样只能。
最后,上面的10个tips,能过提升kernel函数的性能,但是你应该进行具体的性能分析知道程序中最耗时的地方在哪里。当然了,只有通过实验才能真正学会OpenCL高性能编程。
GPGPU OpenCL/CUDA 高性能编程的10大注意事项,布布扣,bubuko.com
GPGPU OpenCL/CUDA 高性能编程的10大注意事项
标签:style class blog c code java
原文地址:http://www.cnblogs.com/biglucky/p/3736981.html