标签:style blog http 使用 sp strong 数据 on 2014
关于缓存替换机制的问题主要有:
1、当替换发生时,替换哪些数据比较合适?
对于这个问题,可以通过一些算法,计算出缓存中每个数据块的价值,每次替换价值最小的数据。关于如何计算缓存数据的价值问题将在下面进行介绍。
由于不同的节点可能存储相同的的数据,因而在替换数据时,不仅考虑当前路由器的状态,同时也通过缓存协同,在了解了周围路由器的信息后再做替换决策。而要实现缓存的协同,路由器中需要保存与它交互的路由器中的信息,比如,我们在每个路由器中建立一个索引表,它记录了与之交互的路由其中保存的缓存信息。
假如有一个路由器R1,现在有一个数据块O3到达R1,这时数据块O3需要存储到路由器R1中,但此时R1中没有剩余的存储空间,这样就需要将R1中价值最小的数据块删除或移动到热度低的节点。一般来说,流行度高的资源我们尽量将它移动到网络的边缘节点,而流行度低的资源我们趋向于将其移动到距离用户相对较远的节点。
关于路由器中数据块价值的计算方法,我们使用如下公式进行计算:
Vnew=Vold+€
其中Vnew表示数据块计算后的价值,Vold表示计算数据块原来的价值,€代表价值的变化
2、缓存内容的价值何时进行刷新?
这个问题主要是研究缓存内容的刷新方式,主要有以下几种:
1) 周期刷新法。在路由器缓存中设置缓存刷新周期,在每个周期结束时,对路由中的所有缓存数据块的价值全部重新刷新一次。此方法的缺点在于,可能导致计算量很大,降低路由器整体性能;另外如果刷新周期过长会导致真正有价值的数据被移除,而价值不大的数据被保存。
2) 替换刷新法。在每次发生替换前先刷新一遍缓存,即更新当前缓存中内容的价值。然后找出价值最低的数据进行替换。此方法的缺点在于,当替换发生频繁时,对缓存的刷新也非常的频繁,这可能导致很大的计算开销,从而降低的路由器的整体性能。
3)替换刷新法改进版1。此方法主要是为了解决方法2)中存在的缺点。在进行替换前,先设置一个最小刷新周期Tm。并且记录上次刷新时间t1,当需要发生替换时,首先判断当前时间t2距离上次刷新时间t1之间的差值是否大于我们原来设定的最小刷新周期Tm,
若Tm≥Δt,则不刷新直接将缓存中价值最小的数据进行替换。
若Tm<Δt,则先将缓存进行刷新,然后再进行替换。
这样就可以大大减少缓存替换频繁所带来的刷新频繁所导致的巨大计算开销。但是此方法存在一个bug,也就是,当突然出现大量数据块需要进行替换时,由于Tm≥Δt,所以导致数据块价值没有得到及时刷新,当所有那些小于数据初始价值的数据被替换后还没有被刷新,这时就会替换那些数据块价值为初值值的数据,这样就可能导致刚进入路由器的数据可能被移除。当然这种情况在Tm越大的情况下发生的概率越大。
4)替换刷新法改进版2。对于方法3)存在的问题,此方法在处理时做了一些改进。当出现要替换的数据块的最小价值等于数据块的初始价值时,这时对缓存进行一次刷新后再找出缓存中最小的数据进行替换,而不是一定要等到Tm<Δt时才去进行刷新。这样就可以及时移除那些价值不大的数据,保留真正有价值的数据。
最后,通过以上分析,理论上来讲,第四种方法的效果最优,也就是在两种情况下才去刷新缓存:
A)在需要替换的数据最小价值等于数据的初始价值时,对缓存进行刷新。
B)当Tm<Δt时,对缓存进行刷新。
3、经过上面的分析,那么如何计算缓存中内容的价值呢?
这是一个非常值得研究的问题。比较传统的方法是使用LRU,LFU等替换算法。这种方法过于僵化,很难达到一种比较理想的效果。
那么,为了替换系统的性能,我们首先分析一下,数据的价值到底与哪些因素有关:(假设现在我们分析的是路由节点i上的数据块O)
1)请求次数(n1)。数据被请求的次数越多,说明该数据块的价值也就越大,反之,其价值可能就越小。即数据块的价值与请求次数成正比。
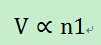
2)距离上次请求的时间(t)。若数据块长时间没有请求,则其重要性应该慢慢降低,以将宝贵的缓存空间让给其他更有价值的数据。即数据块的价值和距离上次请求的时间之间成反比,当距离上次请求的时间越长,则该数据的价值则越低。
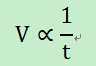
3)节点i周围邻居缓存内容O的次数(s)。周围邻居缓存的次数越多,则节点i的内容O的价值可以适当的降低,因为当节点i中的内容O被替换后,还可以很容易从其邻居节点获得该内容。因而,邻居节点中的缓存内容O的数量与节点i中的内容O的价值正反比。
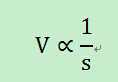
至于邻居节点的范围问题需要进一步研究,可以考虑与节点i的距离小于一个常数c的节点为邻居节点。
4)节点i中请求过内容O的端口数(n2)。在节点i中请求过内容O的端口再次请求内容O的概率较小,因为请求一次后下游节点会保存该内容。因而,当内容O被请求的端口越多,则该内容再次被请求的概率就越低,我们可以认为其价值就越小。故而内容O的价值与该内容被请求的端口数成反比。
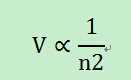
或许,这里看起来有点矛盾,应该说被请求的次数越多,说明内容越受欢迎,其价值应该就越大,因而更应当存储。而实际上流行度越高的数据,我们要尽量将它转移到网络的边缘节点,这样离用户更近,这样当用户需要该数据时就能快速获取。而通过这个参数n2,我们就可以实现将热门资源移向网络的边缘,从而使系统整体达到更好的性能。同理,我们尽量将流行度低的资源向网络的中间移动。
5)节点i与内容O的永久保存节点之间的距离(d)。这个有点类似参数s,只是s的值很有可能一直为0,因而,通过此参数可以从一定程度上更好的调整内容O的价值。
当节点i与内容O的距离越近,那么下次获取内容O的代价就越小,这样替换内容O的代价就越小。因而,内容O的价值可以认为与参数d成反比。
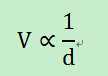
4、如何根据数据块O的相关参数计算其价值V?
在上面,我们已经详细分析了价值V与哪些参数相关,以及是正相关还是负相关。那么我们如何通过这些参数,构建一个计算模型,最终得到我们想要的内容价值?
这将是下一个月的主要研究任务。。。
标签:style blog http 使用 sp strong 数据 on 2014
原文地址:http://www.cnblogs.com/liuwu265/p/4121179.html