标签:style blog http io ar color os 使用 sp
上一篇分析了split的生成,现在接着来说具体的split具体内容及其相关的文件和类。以FileSplit(mapred包下org/apache/hadoop/mapreduce/lib/input/FileSplit.java)为例,它继承了InputSplit接口,包括以下属性:
1 public class FileSplit extends InputSplit implements Writable {
2 private Path file; //分片对应的文件路径
3 private long start; //分片在文件中的偏移量
4 private long length; //分片长度
5 private String[] hosts; //所在主机列表
其中路径信息file标示了split对应的文件,其格式是这样的:hdfs://localhost:9000/home/hadoop/input/text1.txt。这个可以在debug的时候看的很清楚。另外就是hosts数组,标示了split对应的block所在的主机列表。当然有这么一种情况:就是split可能跨多个block,这时hosts表示的是哪个block所在的主机列表呢?这个问题等以后看到这部分源码的时候再说吧。
JobClient端的submitJobInternal()方法在计划和划分split的同时,生成了两个文件:job.split和job.splitmetainfo,将其放在HDFS的${mapreduce.jobtracker.staging.root.dir}/${user}/.staging/${JobId}目录下。他们的作用分别为:
job.split:表示原始分片信息,Map task初始化时使用,用以获取要处理的数据。
job.splitmetainfo:表示分片元信息, JobTracker用来构造locality的task。
下面着重解析下这两个文件:
job.split文件:
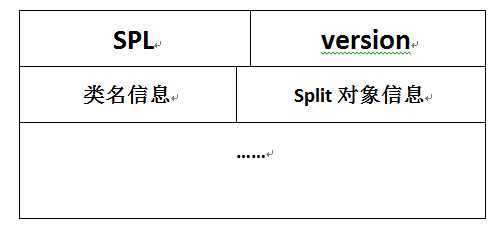
SPL :job.split文件头
version:版本信息,为1,int类型
类名信息:
类名长度:int类型,表示其后的类名由多少个字符组成(47)
类名:org.apache.hadoop.mapreduce.lib.input.FileSplit(共47个字符)
对象信息:
长度:int类型,表示其后的文件名信息由多少字符组成(49)
文件名:hdfs://localhost:9000/home/hadoop/input/text1.txt(共49个字符)
start:Long类型,表示该split的偏移量,
length:Long类型,表示分片长度
然后就是类名信息和对象信息作为一个条目,如此一直重复下去。要注意一点:图中的的边界并不一定是对齐的。
Job.splitmetainfo文件:

META-SPL :Job.splitmetainfo文件头
version:版本信息,为1,int类型
length:split的数目,int类型
副本信息:
副本个数:int类型
主机信息:int(表示主机名的长度),byte[](用来存储主机名) (如:8:gouyk-pc)
…… (以上边的形式重复写,因为会有多个split)
startOffset:split在job.split中的偏移量,Long
inputDataLength:分片长度, Long
然后就是副本信息和startOffset、inputDataLength作为一个条目,如此一直重复下去。同样,图中的的边界并不一定是对齐的。
下面说说关于读写split的基础类:SplitMetaInfo、TaskSplitMetaInfo和TaskSplitIndex,它们都封装在JobSplit类中。
SplitMetaInfo类代表了split的元数据信息,在生成job.split文件时被构造出来。主要属性如下:
1 public static class SplitMetaInfo implements Writable {
2 private long startOffset; //该split元信息在job.split文件中的偏移量
3 private long inputDataLength; //该split的数据长度
4 private String[] locations; //该split对应的host列表
TaskSplitMetaInfo类代表了Map Task要处理的split的元信息,在JobTracker端初始化Job时读取job.splitmetainfo文件后被构造出来。并将其存入到Map Task(TaskInProgress)中。在TaskTracker端,Map Task根据TaskSplitMetaInfo从job.split文件中读取split信息。主要属性如下:
1 public static class TaskSplitMetaInfo {
2 private TaskSplitIndex splitIndex; //split元信息在job.split文件中的索引
3 private long inputDataLength; //split的数据长度
4 private String[] locations; //split对应的host列表
TaskSplitIndex用于指定split在job.split中的位置。主要属性如下:
1 public static class TaskSplitIndex {
2 private String splitLocation; //job.split文件所在的位置
3 private long startOffset; //split在job.split文件中的索引
本文基于hadoop1.2.1
如有错误,还请指正
参考文章:《Hadoop技术内幕 深入理解MapReduce架构设计与实现原理》 董西成
转载请注明出处:http://www.cnblogs.com/gwgyk/p/4123414.html
标签:style blog http io ar color os 使用 sp
原文地址:http://www.cnblogs.com/gwgyk/p/4123414.html